Generative World Modelling for Humanoids: 1X World Model Challenge Technical Report
作者: Riccardo Mereu, Aidan Scannell, Yuxin Hou, Yi Zhao, Aditya Jitta, Antonio Dominguez, Luigi Acerbi, Amos Storkey, Paul Chang
分类: cs.LG, cs.AI, cs.RO
发布日期: 2025-10-08
备注: 6 pages, 3 figures, 1X world model challenge technical report
💡 一句话要点
针对具身智能体,提出基于Wan-2.2和时空Transformer的生成式世界模型,在1X挑战赛中获得第一。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 世界模型 具身智能 视频生成 时空Transformer 人形机器人
📋 核心要点
- 现有世界模型在处理复杂具身智能体交互时,面临着预测精度和计算效率的挑战。
- 论文提出一种基于视频生成模型和时空Transformer的混合方法,分别用于图像采样和潜在编码压缩。
- 实验结果表明,该方法在1X世界模型挑战赛的两个赛道上均取得了领先成绩,验证了其有效性。
📝 摘要(中文)
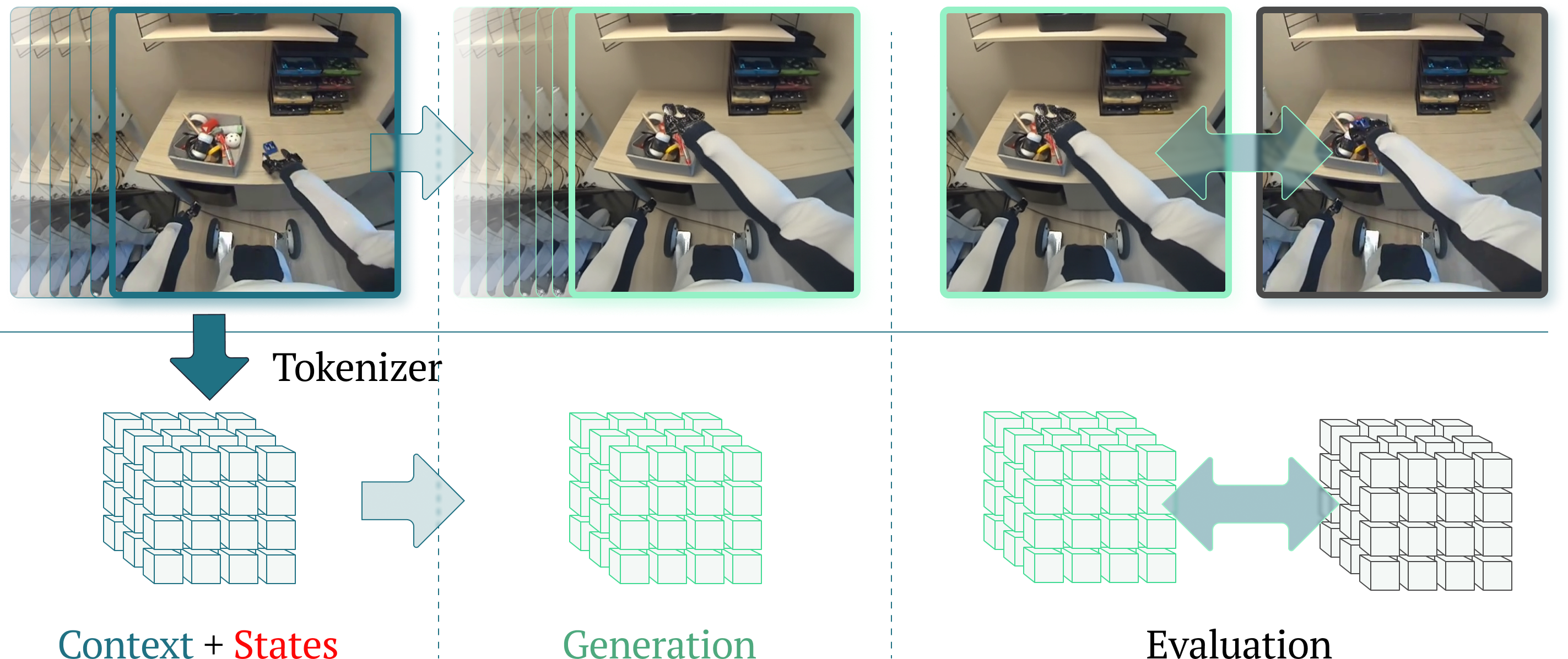
世界模型是人工智能和机器人领域中一种强大的范式,它使智能体能够通过预测视觉观察或紧凑的潜在状态来推理未来。1X世界模型挑战赛引入了一个开源的真实世界人形机器人交互基准,包含两个互补的赛道:采样,侧重于预测未来的图像帧;压缩,侧重于预测未来的离散潜在代码。对于采样赛道,我们调整了视频生成基础模型Wan-2.2 TI2V-5B,使其能够进行视频-状态条件下的未来帧预测。我们使用AdaLN-Zero将视频生成模型与机器人状态进行条件约束,并使用LoRA进一步对模型进行后训练。对于压缩赛道,我们从头开始训练了一个时空Transformer模型。我们的模型在采样任务中实现了23.0 dB的PSNR,在压缩任务中实现了6.6386的Top-500 CE,在两个挑战赛中均获得了第一名。
🔬 方法详解
问题定义:论文旨在解决人形机器人与环境交互过程中,如何构建高效且准确的世界模型的问题。现有方法在预测未来视觉观测或潜在状态时,往往面临精度不足或计算成本过高的问题,难以满足实时控制的需求。特别是在1X世界模型挑战赛中,需要在采样和压缩两个维度上同时优化性能。
核心思路:论文的核心思路是利用预训练的视频生成模型Wan-2.2 TI2V-5B的强大生成能力,并结合时空Transformer模型对潜在状态进行高效压缩。通过迁移学习和微调,将预训练模型适应于机器人交互场景,同时利用Transformer的建模能力捕捉时序依赖关系。
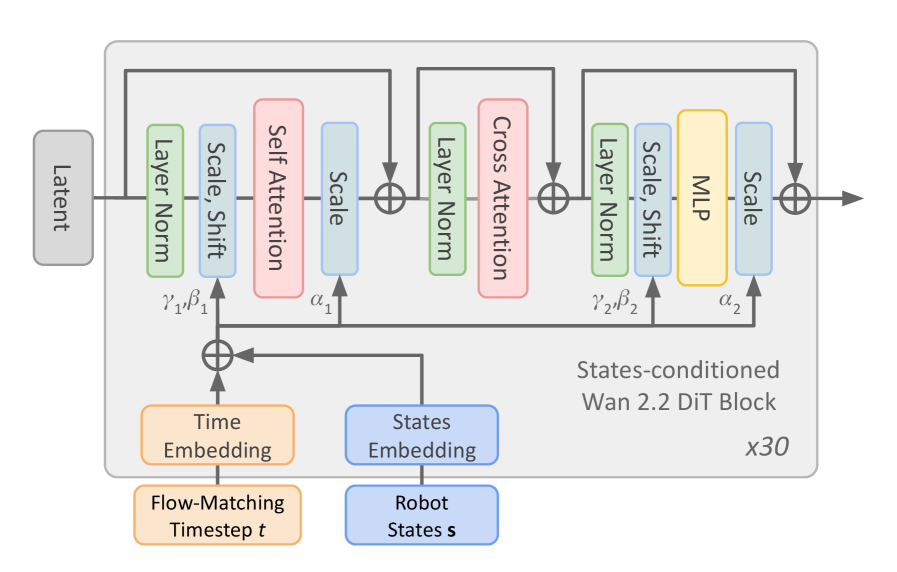
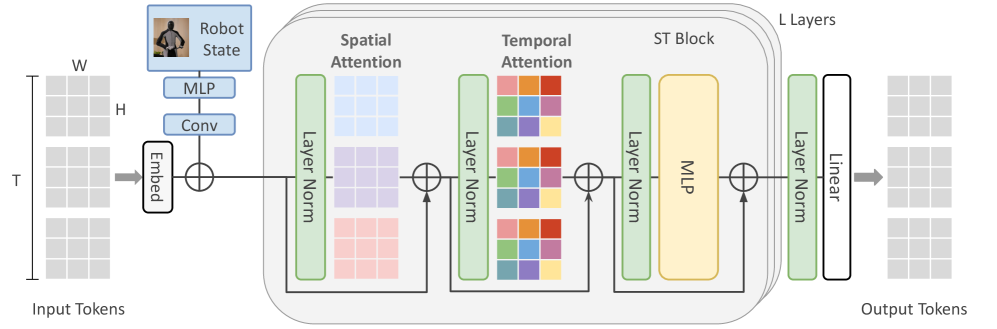
技术框架:整体框架包含两个主要分支:采样分支和压缩分支。采样分支使用Wan-2.2 TI2V-5B模型,通过AdaLN-Zero将机器人状态信息融入视频生成过程,并使用LoRA进行微调。压缩分支则从头训练一个时空Transformer模型,用于预测未来的离散潜在代码。两个分支独立训练,分别优化采样质量和压缩效率。
关键创新:论文的关键创新在于将大规模视频生成模型应用于具身智能体的世界模型构建,并结合AdaLN-Zero和LoRA等技术,实现了高效的状态条件视频生成。此外,从头训练的时空Transformer模型也针对压缩任务进行了优化,能够有效捕捉时空依赖关系。
关键设计:在采样分支中,AdaLN-Zero用于将机器人状态信息融入到Wan-2.2模型的生成过程中,通过调整BatchNorm层的参数来实现。LoRA则用于在预训练模型的基础上进行微调,以适应特定的机器人交互场景。在压缩分支中,时空Transformer模型采用了标准的Transformer架构,并针对视频数据的特点进行了优化,例如使用3D卷积提取时空特征。
🖼️ 关键图片
📊 实验亮点
该论文提出的方法在1X世界模型挑战赛中取得了显著成果。在采样任务中,模型实现了23.0 dB的PSNR,显著优于其他参赛队伍。在压缩任务中,模型实现了6.6386的Top-500 CE,同样取得了领先地位。这些结果表明,该方法在生成高质量的未来帧和高效压缩潜在状态方面具有显著优势。
🎯 应用场景
该研究成果可应用于人形机器人的自主导航、操作和决策等领域。通过构建准确的世界模型,机器人能够更好地理解环境,预测未来状态,从而做出更合理的规划和控制。此外,该方法还可以推广到其他具身智能体,例如无人车、无人机等,具有广泛的应用前景。
📄 摘要(原文)
World models are a powerful paradigm in AI and robotics, enabling agents to reason about the future by predicting visual observations or compact latent states. The 1X World Model Challenge introduces an open-source benchmark of real-world humanoid interaction, with two complementary tracks: sampling, focused on forecasting future image frames, and compression, focused on predicting future discrete latent codes. For the sampling track, we adapt the video generation foundation model Wan-2.2 TI2V-5B to video-state-conditioned future frame prediction. We condition the video generation on robot states using AdaLN-Zero, and further post-train the model using LoRA. For the compression track, we train a Spatio-Temporal Transformer model from scratch. Our models achieve 23.0 dB PSNR in the sampling task and a Top-500 CE of 6.6386 in the compression task, securing 1st place in both challenges.