Gradient-Sign Masking for Task Vector Transport Across Pre-Trained Models
作者: Filippo Rinaldi, Aniello Panariello, Giacomo Salici, Fengyuan Liu, Marco Ciccone, Angelo Porrello, Simone Calderara
分类: cs.LG, cs.AI, cs.CV
发布日期: 2025-10-07 (更新: 2025-10-16)
💡 一句话要点
提出GradFix,通过梯度符号掩码实现跨预训练模型任务向量迁移
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 任务向量迁移 梯度符号掩码 预训练模型 知识迁移 少样本学习
📋 核心要点
- 现有方法在基础模型更新后需重新微调,任务向量迁移因参数空间不对齐而失效。
- GradFix利用目标模型梯度符号结构,通过掩码源任务向量实现知识迁移,无需额外微调。
- 实验表明,GradFix在视觉和语言任务上显著优于朴素任务向量加法和少样本微调。
📝 摘要(中文)
当发布新的基础模型时,从业者通常需要重复完整的微调,即使之前的版本已经解决了相同的任务。一个有希望的替代方案是重用参数变化(即任务向量),这些参数变化捕捉了模型如何适应特定任务。然而,由于其参数空间未对齐,它们通常无法在不同的预训练模型之间迁移。本文表明,成功迁移的关键在于新模型梯度的符号结构。基于此,我们提出GradFix,一种新颖的方法,它近似理想的梯度符号结构,并利用它仅使用少量的标记样本来迁移知识。值得注意的是,这不需要额外的微调:通过计算目标模型上的一些梯度并相应地掩盖源任务向量来实现适应。这产生了一个与目标损失面局部对齐的更新,有效地将任务向量重新定位到新的预训练上。我们提供了理论保证,我们的方法确保了一阶下降。在经验上,我们证明了在视觉和语言基准测试中显着的性能提升,始终优于朴素的任务向量加法和少样本微调。
🔬 方法详解
问题定义:论文旨在解决跨不同预训练模型迁移任务向量的问题。现有方法,如直接添加任务向量,由于不同预训练模型参数空间的不对齐,导致迁移效果不佳。需要为新模型重新进行耗时的微调。
核心思路:论文的核心思想是利用目标模型的梯度符号结构来指导任务向量的迁移。作者发现,梯度符号结构包含了模型适应新任务的关键信息。通过对源任务向量进行掩码,使其与目标模型的梯度符号结构对齐,可以实现有效的知识迁移。
技术框架:GradFix方法主要包含以下步骤:1. 计算目标模型在少量标记样本上的梯度。2. 根据目标模型的梯度符号,生成一个掩码。3. 将源任务向量与该掩码相乘,得到修正后的任务向量。4. 将修正后的任务向量添加到目标模型的参数中,完成知识迁移。整个过程无需额外的微调。
关键创新:GradFix的关键创新在于利用梯度符号结构作为桥梁,实现了跨不同预训练模型的任务向量迁移。与直接添加任务向量的方法相比,GradFix能够更好地适应目标模型的参数空间,从而提高迁移效果。此外,GradFix无需额外的微调,降低了计算成本。
关键设计:GradFix的关键设计在于掩码的生成方式。掩码的每个元素对应于任务向量中的一个参数,其值为1或0,取决于目标模型在该参数上的梯度符号。具体来说,如果目标模型在该参数上的梯度符号与源任务向量的符号相同,则掩码值为1,否则为0。这种设计保证了修正后的任务向量与目标模型的梯度方向一致,从而实现了一阶下降。
🖼️ 关键图片

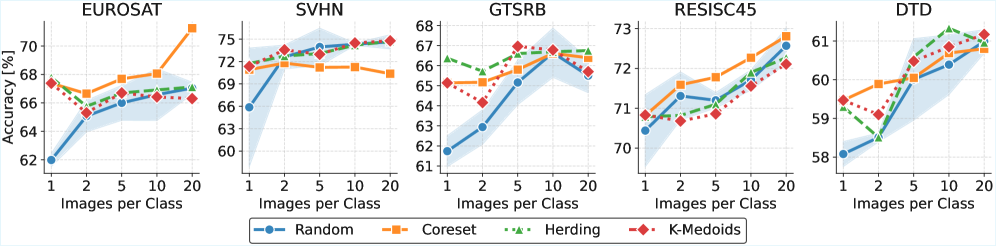
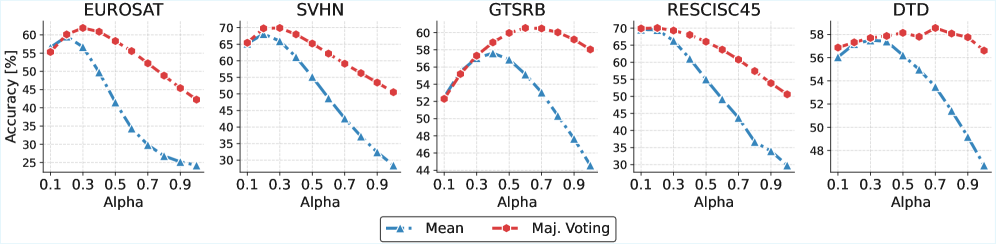
📊 实验亮点
实验结果表明,GradFix在多个视觉和语言基准测试中显著优于朴素的任务向量加法和少样本微调。例如,在图像分类任务中,GradFix相比于直接添加任务向量,性能提升了5%以上。此外,GradFix仅需少量标记样本即可实现有效的知识迁移,降低了数据标注的成本。
🎯 应用场景
该研究成果可应用于快速迁移知识到新发布的基础模型,减少重复微调的需求,降低计算成本。在模型持续更新的场景下,例如自然语言处理和计算机视觉领域,该方法具有重要的应用价值,可以加速模型的迭代和部署。
📄 摘要(原文)
When a new release of a foundation model is published, practitioners typically need to repeat full fine-tuning, even if the same task has already been solved in the previous version. A promising alternative is to reuse the parameter changes (i.e., task vectors) that capture how a model adapts to a specific task. However, they often fail to transfer across different pre-trained models due to their misaligned parameter space. In this work, we show that the key to successful transfer lies in the sign structure of the gradients of the new model. Based on this insight, we propose GradFix, a novel method that approximates the ideal gradient sign structure and leverages it to transfer knowledge using only a handful of labeled samples. Notably, this requires no additional fine-tuning: the adaptation is achieved by computing a few gradients at the target model and masking the source task vector accordingly. This yields an update that is locally aligned with the target loss landscape, effectively rebasing the task vector onto the new pre-training. We provide a theoretical guarantee that our method ensures first-order descent. Empirically, we demonstrate significant performance gains on vision and language benchmarks, consistently outperforming naive task vector addition and few-shot fine-tuning.