Online Matching via Reinforcement Learning: An Expert Policy Orchestration Strategy
作者: Chiara Mignacco, Matthieu Jonckheere, Gilles Stoltz
分类: stat.ML, cs.LG
发布日期: 2025-10-07
💡 一句话要点
提出基于强化学习的专家策略编排方法,解决在线匹配问题。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 在线匹配 强化学习 专家策略 策略编排 Actor-Critic 优势函数 时间差分学习
📋 核心要点
- 传统在线匹配启发式算法针对特定场景设计,难以适应动态变化的环境,导致效率降低。
- 利用强化学习编排多个专家策略,通过优势函数自适应地调整策略权重,实现更高效的决策。
- 实验表明,该方法在随机匹配模型和器官交换场景中,比传统方法收敛更快,系统效率更高。
📝 摘要(中文)
在线匹配问题广泛存在于复杂系统中,如云服务、在线市场和器官交换网络。在这些场景中,及时且合理的决策对于维持系统高性能至关重要。传统启发式方法虽然简单易懂,但通常针对特定运行状态设计,当条件变化时可能导致效率低下。本文提出一种强化学习(RL)方法,学习编排一组专家策略,以数据驱动和自适应的方式利用它们的互补优势。该方法基于Adv2框架,通过基于优势的权重更新结合专家决策,并自然地扩展到仅有估计值函数可用的场景。本文建立了期望和高概率遗憾保证,并推导了时间差分学习的有限时间偏差界限,即使在恒定步长和非平稳动态下也能实现可靠的优势估计。为了支持可扩展性,本文引入了一种神经Actor-Critic架构,该架构可以在大型状态空间中泛化,同时保持可解释性。在随机匹配模型(包括器官交换场景)上的仿真表明,编排策略比单个专家和传统RL基线收敛更快,并产生更高的系统级效率。研究结果表明,结构化的自适应学习可以改善复杂资源分配和决策过程的建模和管理。
🔬 方法详解
问题定义:论文旨在解决在线匹配问题,例如云服务资源分配、在线市场匹配供需、器官交换等。现有启发式算法通常针对特定场景设计,缺乏泛化能力,难以适应动态变化的环境。当系统状态发生变化时,这些算法的性能会显著下降,导致资源利用率低或匹配效率不高。
核心思路:论文的核心思路是利用强化学习(RL)来学习如何有效地组合多个专家策略。每个专家策略在特定场景下表现良好,但都有其局限性。通过RL,可以学习一个策略,该策略能够根据当前系统状态,自适应地选择或组合不同的专家策略,从而充分利用它们的互补优势,提高整体性能。
技术框架:该方法基于Adv2框架,整体流程如下:1) 定义一组专家策略,每个策略针对不同的场景或目标。2) 使用强化学习算法(Actor-Critic)学习一个策略(Actor),该策略根据当前状态为每个专家策略分配权重。3) Critic评估当前状态下策略的价值,用于指导Actor的更新。4) 通过优势函数(advantage function)来衡量每个专家策略相对于平均策略的优劣,并根据优势函数更新专家策略的权重。5) 使用时间差分学习(TD learning)来估计价值函数,并推导了有限时间偏差界限,以保证学习的可靠性。
关键创新:该方法的关键创新在于:1) 使用强化学习自适应地编排多个专家策略,而不是依赖单一的启发式算法。2) 基于Adv2框架,利用优势函数来更新专家策略的权重,能够更有效地利用专家知识。3) 推导了时间差分学习的有限时间偏差界限,即使在非平稳动态下也能保证学习的可靠性。4) 提出了一个神经Actor-Critic架构,可以在大型状态空间中泛化,同时保持可解释性。
关键设计:1) Actor网络:可以使用神经网络来表示,输入是系统状态,输出是每个专家策略的权重。2) Critic网络:可以使用神经网络来表示,输入是系统状态,输出是当前策略的价值估计。3) 损失函数:可以使用TD误差来训练Critic网络,使用策略梯度来训练Actor网络。4) 优势函数:可以使用TD误差的估计值来计算优势函数。5) 步长:可以使用恒定步长,但需要保证步长足够小,以保证学习的稳定性。
🖼️ 关键图片
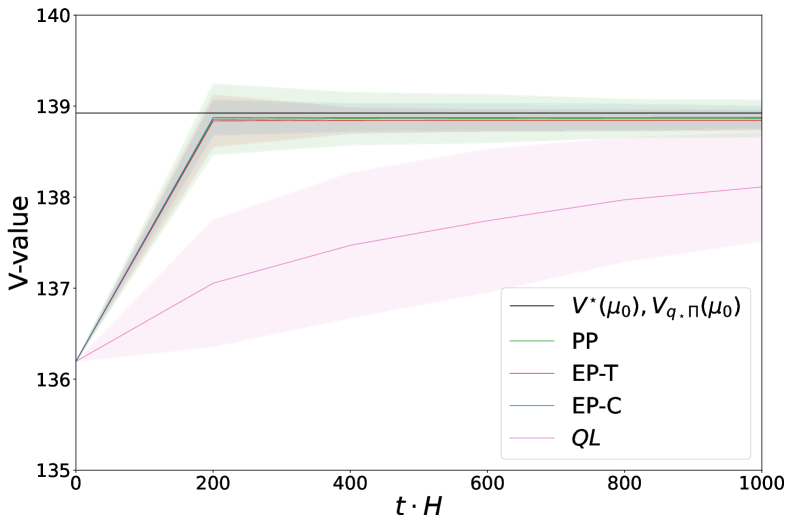
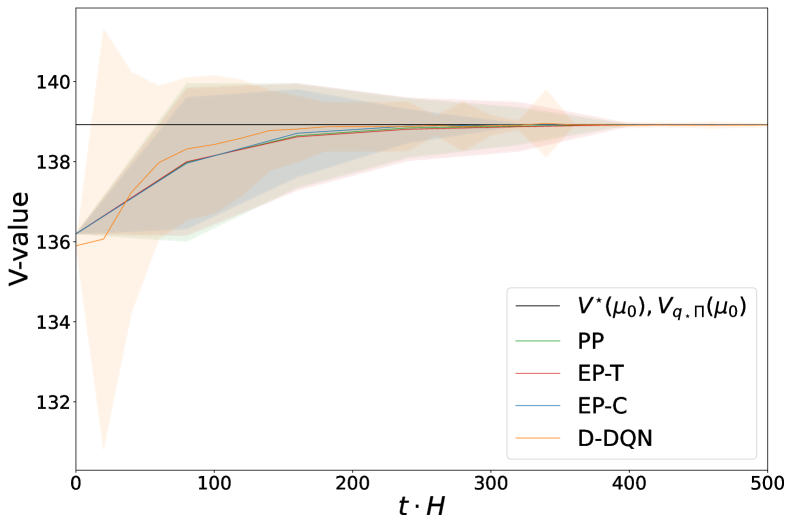
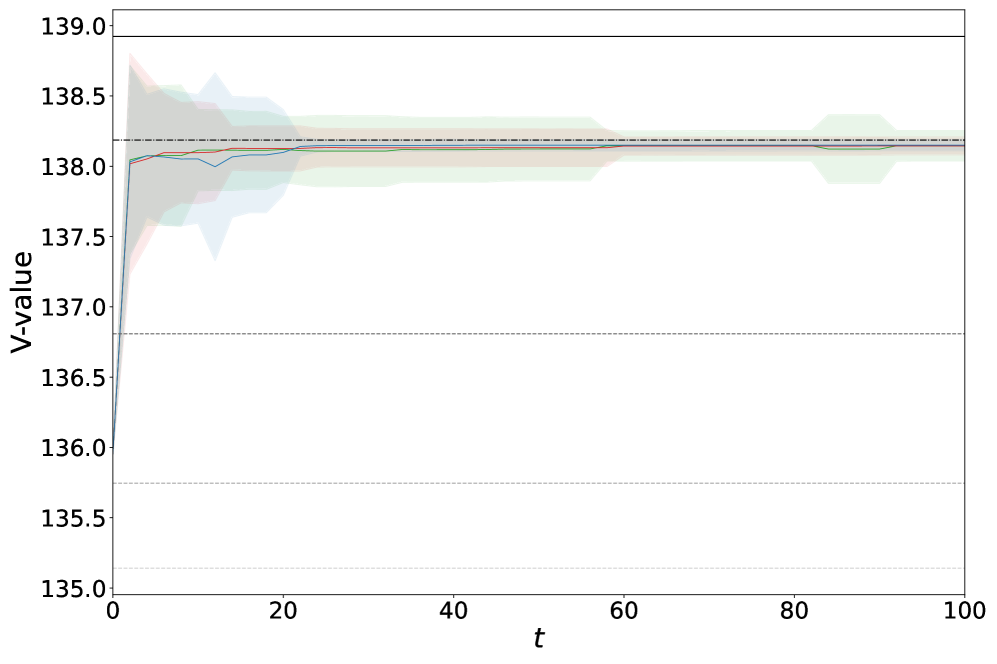
📊 实验亮点
在随机匹配模型和器官交换场景的仿真实验中,该方法表现出优于传统启发式算法和传统强化学习基线的性能。具体来说,该方法收敛速度更快,系统级效率更高。例如,在器官交换场景中,该方法能够显著提高成功匹配的器官数量,从而挽救更多患者的生命。
🎯 应用场景
该研究成果可应用于各种在线匹配场景,例如:云服务资源分配、在线市场供需匹配、器官交换网络、车辆调度等。通过自适应地选择或组合不同的专家策略,可以提高资源利用率、匹配效率和系统整体性能。该方法具有很高的实际应用价值,可以帮助企业和组织更好地管理和优化其资源分配和决策过程。
📄 摘要(原文)
Online matching problems arise in many complex systems, from cloud services and online marketplaces to organ exchange networks, where timely, principled decisions are critical for maintaining high system performance. Traditional heuristics in these settings are simple and interpretable but typically tailored to specific operating regimes, which can lead to inefficiencies when conditions change. We propose a reinforcement learning (RL) approach that learns to orchestrate a set of such expert policies, leveraging their complementary strengths in a data-driven, adaptive manner. Building on the Adv2 framework (Jonckheere et al., 2024), our method combines expert decisions through advantage-based weight updates and extends naturally to settings where only estimated value functions are available. We establish both expectation and high-probability regret guarantees and derive a novel finite-time bias bound for temporal-difference learning, enabling reliable advantage estimation even under constant step size and non-stationary dynamics. To support scalability, we introduce a neural actor-critic architecture that generalizes across large state spaces while preserving interpretability. Simulations on stochastic matching models, including an organ exchange scenario, show that the orchestrated policy converges faster and yields higher system level efficiency than both individual experts and conventional RL baselines. Our results highlight how structured, adaptive learning can improve the modeling and management of complex resource allocation and decision-making processes.