GUIDE: Guided Initialization and Distillation of Embeddings
作者: Khoa Trinh, Gaurav Menghani, Erik Vee
分类: cs.LG
发布日期: 2025-10-07
💡 一句话要点
提出GUIDE:引导初始化和嵌入蒸馏,提升学生模型质量且无额外开销
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 嵌入蒸馏 知识蒸馏 模型压缩 模型加速 参数初始化 迁移学习
📋 核心要点
- 传统蒸馏方法仅关注输出匹配,忽略了大型教师模型中蕴含的更多信息,未能充分利用其价值。
- GUIDE通过引导学生模型在参数空间中匹配教师模型,从而更有效地传递知识,提升学生模型性能。
- 实验表明,GUIDE能显著缩小师生模型质量差距,且可与知识蒸馏结合,同时不增加训练或推理负担。
📝 摘要(中文)
本文提出了一种名为GUIDE(Guided Initialization and Distillation of Embeddings,引导初始化和嵌入蒸馏)的蒸馏技术。与标准蒸馏方法仅强制学生模型匹配教师模型的输出不同,GUIDE强制学生模型在参数空间中匹配教师模型。实验结果表明,在使用大型学生模型(400M-1B参数)并在约20B tokens上训练时,GUIDE可以将教师-学生模型的质量差距缩小25-26%。进一步分析表明,GUIDE可以与知识蒸馏相结合,实现近乎叠加的性能提升。更重要的是,单独应用GUIDE比单独应用知识蒸馏能获得更好的模型质量。GUIDE不引入额外的训练或推理开销,因此该方法带来的模型质量提升几乎是免费的。
🔬 方法详解
问题定义:现有知识蒸馏方法主要关注让学生模型模仿教师模型的输出,而忽略了教师模型内部参数所蕴含的丰富知识。训练大型模型成本高昂,仅仅让学生模型匹配输出,无法充分利用教师模型的价值。因此,需要一种更有效的方法,将教师模型的知识迁移到学生模型,缩小模型质量差距。
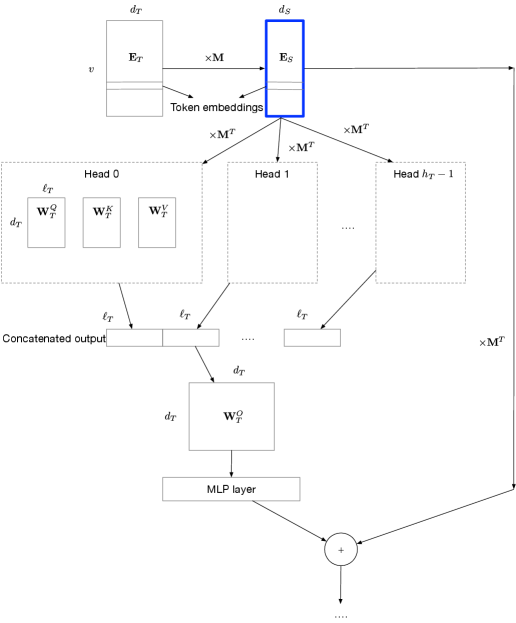
核心思路:GUIDE的核心思路是让学生模型的嵌入(embeddings)在训练初期就尽可能接近教师模型的嵌入。通过在参数空间进行匹配,学生模型能够更好地学习到教师模型的知识表示,从而提高模型质量。这种方法可以看作是一种参数空间的蒸馏。
技术框架:GUIDE的整体框架非常简单,主要包括以下步骤:1)使用教师模型训练得到高质量的嵌入;2)使用教师模型的嵌入来初始化学生模型的嵌入;3)在训练过程中,可以结合传统的知识蒸馏方法,进一步提升学生模型的性能。GUIDE不改变原有的训练流程,只是在初始化阶段引入了教师模型的知识。
关键创新:GUIDE的关键创新在于将蒸馏的思想从输出空间扩展到参数空间,通过引导学生模型的嵌入初始化,使其能够更快地学习到教师模型的知识表示。与传统的知识蒸馏方法相比,GUIDE能够更有效地利用教师模型的知识,从而提高学生模型的性能。
关键设计:GUIDE的关键设计在于如何有效地将教师模型的嵌入迁移到学生模型。一种简单的方法是直接复制教师模型的嵌入到学生模型中。当学生模型和教师模型的嵌入维度不同时,可以使用线性变换或其他映射方法将教师模型的嵌入映射到学生模型的嵌入空间。在训练过程中,可以使用均方误差等损失函数来衡量学生模型和教师模型嵌入之间的差异,并将其作为正则化项添加到总损失函数中。
🖼️ 关键图片

📊 实验亮点
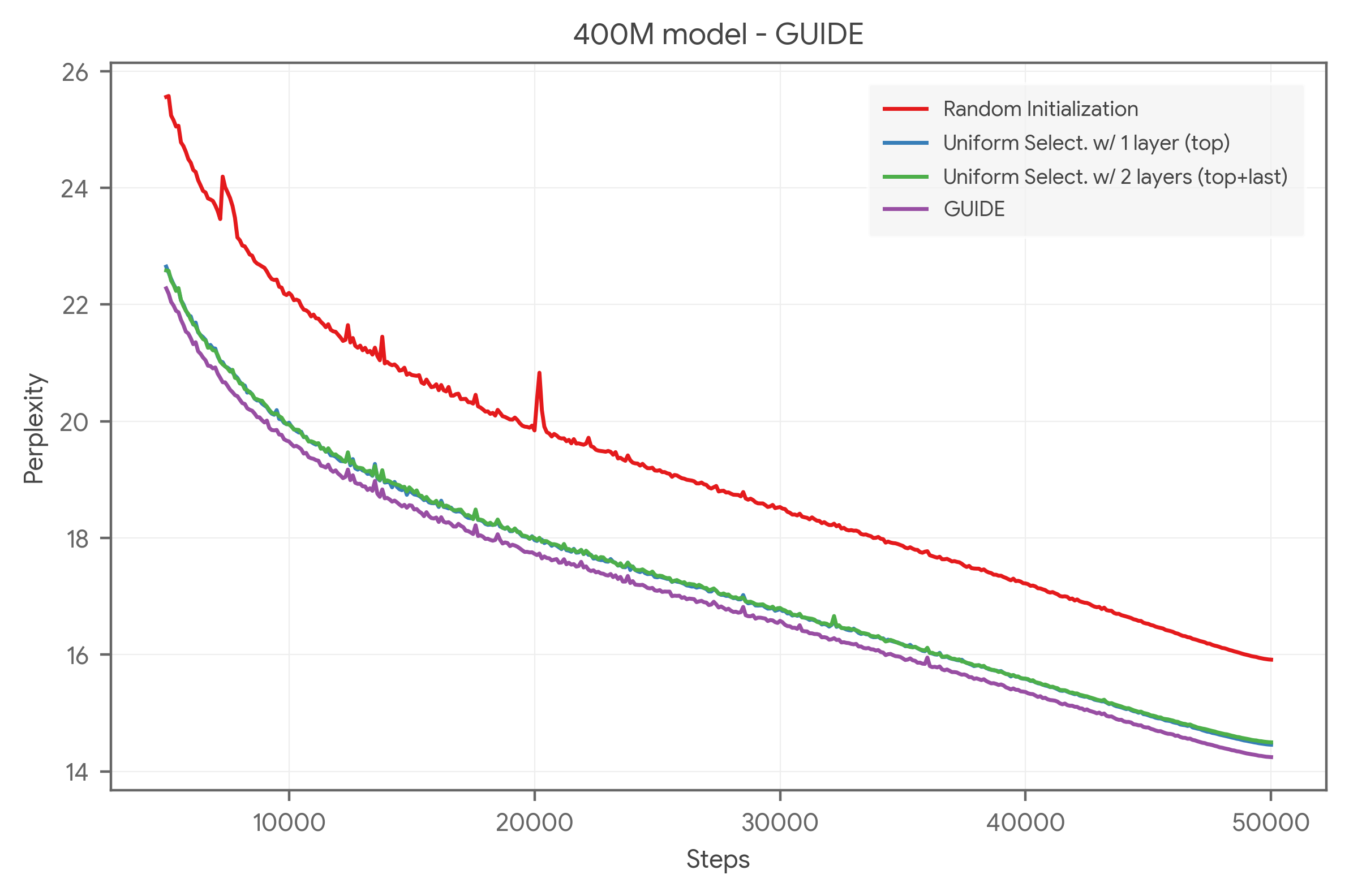
实验结果表明,在使用大型学生模型(400M-1B参数)并在约20B tokens上训练时,GUIDE可以将教师-学生模型的质量差距缩小25-26%。此外,GUIDE可以与知识蒸馏相结合,实现近乎叠加的性能提升。更重要的是,单独应用GUIDE比单独应用知识蒸馏能获得更好的模型质量,且不引入额外的训练或推理开销。
🎯 应用场景
GUIDE可广泛应用于各种需要模型压缩和加速的场景,例如自然语言处理、计算机视觉等。通过将大型模型的知识迁移到小型模型,可以在资源受限的设备上部署高性能的模型,例如移动设备、嵌入式系统等。此外,GUIDE还可以用于模型迁移学习,将预训练模型的知识迁移到特定任务上,提高模型在特定任务上的性能。
📄 摘要(原文)
Algorithmic efficiency techniques such as distillation (\cite{hinton2015distillation}) are useful in improving model quality without increasing serving costs, provided a larger teacher model is available for a smaller student model to learn from during training. Standard distillation methods are limited to only forcing the student to match the teacher's outputs. Given the costs associated with training a large model, we believe we should be extracting more useful information from a teacher model than by just making the student match the teacher's outputs. In this paper, we introduce \guide (Guided Initialization and Distillation of Embeddings). \guide can be considered a distillation technique that forces the student to match the teacher in the parameter space. Using \guide we show 25-26\% reduction in the teacher-student quality gap when using large student models (400M - 1B parameters) trained on $\approx$ 20B tokens. We also present a thorough analysis demonstrating that \guide can be combined with knowledge distillation with near additive improvements. Furthermore, we show that applying \guide alone leads to substantially better model quality than applying knowledge distillation by itself. Most importantly, \guide introduces no training or inference overhead and hence any model quality gains from our method are virtually free.