Stratified GRPO: Handling Structural Heterogeneity in Reinforcement Learning of LLM Search Agents
作者: Mingkang Zhu, Xi Chen, Bei Yu, Hengshuang Zhao, Jiaya Jia
分类: cs.LG, cs.AI, cs.CL
发布日期: 2025-10-07
💡 一句话要点
提出Stratified GRPO,解决LLM搜索Agent强化学习中结构异质性问题
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 强化学习 大型语言模型 搜索Agent 结构异质性 策略梯度 分层优势归一化 跨层偏差 智能问答
📋 核心要点
- 现有强化学习方法在训练LLM搜索Agent时,由于搜索轨迹的结构异质性,导致跨层偏差,影响信用分配和策略探索。
- 论文提出Stratified GRPO,通过分层优势归一化(SAN)将轨迹划分为同质层,在层内局部计算优势,消除跨层偏差。
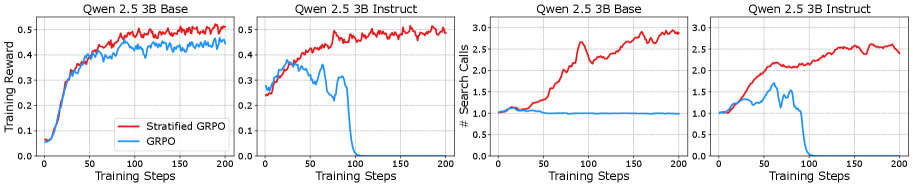
- 实验表明,Stratified GRPO在单跳和多跳问答任务上显著优于GRPO,提升高达11.3个点,提高了训练稳定性和搜索策略效果。
📝 摘要(中文)
大型语言模型(LLM)Agent越来越多地依赖搜索引擎等外部工具来解决复杂的多步骤问题,而强化学习(RL)已成为训练它们的关键范例。然而,搜索Agent的轨迹在结构上是异质的,搜索调用的数量、位置和结果的变化导致了根本不同的答案方向和奖励分布。标准的策略梯度方法使用单一的全局基线,会受到我们定义和形式化的跨层偏差的影响,即对异质轨迹进行“苹果与橙子”的比较。这种跨层偏差扭曲了信用分配,阻碍了复杂的多步骤搜索策略的探索。为了解决这个问题,我们提出了Stratified GRPO,其核心组件是分层优势归一化(SAN),它根据轨迹的结构属性将轨迹划分为同质层,并在每个层内局部计算优势。这确保了轨迹仅根据其真正的同类进行评估。我们的分析证明,SAN消除了跨层偏差,在每个层内产生条件无偏的单位方差估计,并保留了标准归一化所享有的全局无偏性和单位方差特性,从而产生更纯粹和尺度稳定的学习信号。为了提高有限样本情况下的实际稳定性,我们进一步将SAN与全局估计器线性混合。在各种单跳和多跳问答基准上的大量实验表明,Stratified GRPO始终且大幅优于GRPO,最高提升11.3个点,实现了更高的训练奖励、更大的训练稳定性和更有效的搜索策略。这些结果表明,分层是解决LLM搜索Agent强化学习中结构异质性的一个原则性补救措施。
🔬 方法详解
问题定义:论文旨在解决LLM搜索Agent在强化学习训练过程中,由于搜索轨迹的结构异质性(例如,搜索次数、搜索位置、搜索结果的不同)导致的跨层偏差问题。现有方法使用单一全局基线进行策略梯度更新,无法有效区分不同结构的轨迹,导致信用分配不准确,阻碍了复杂搜索策略的探索。
核心思路:论文的核心思路是将具有相似结构属性的轨迹划分到同一“层”中,然后在每一层内部进行优势函数的归一化。这样可以确保在计算优势函数时,只将相似的轨迹进行比较,从而消除跨层偏差,得到更准确的信用分配。这种分层处理使得学习信号更加纯粹和尺度稳定。
技术框架:Stratified GRPO 的整体框架包括以下几个主要步骤:1. 收集LLM搜索Agent的轨迹数据。2. 根据轨迹的结构属性(例如,搜索次数)将轨迹划分到不同的层中。3. 在每一层内部,计算优势函数并进行归一化(SAN)。4. 使用归一化后的优势函数进行策略梯度更新。为了提高实际稳定性,还将SAN与全局估计器线性混合。
关键创新:论文最重要的技术创新点是分层优势归一化(SAN)。SAN通过将轨迹划分到同质层中,并在层内进行优势函数归一化,有效消除了跨层偏差。与传统的全局归一化方法相比,SAN能够更准确地评估每个轨迹的价值,从而提高强化学习的效率和效果。论文还从理论上证明了SAN消除了跨层偏差,并保留了全局无偏性和单位方差特性。
关键设计:SAN的关键设计在于如何定义轨迹的结构属性以及如何进行分层。论文中使用了搜索次数作为结构属性的示例,但也可以根据具体任务选择其他合适的属性。分层的具体实现方式可以采用聚类算法或其他划分方法。此外,SAN与全局估计器的线性混合比例也是一个需要调整的关键参数,以平衡偏差消除和稳定性。
🖼️ 关键图片
📊 实验亮点
实验结果表明,Stratified GRPO在单跳和多跳问答基准测试中,相较于基线方法GRPO,性能提升高达11.3个点。此外,Stratified GRPO还表现出更高的训练稳定性和更有效的搜索策略,验证了分层处理对于解决LLM搜索Agent强化学习中结构异质性问题的有效性。
🎯 应用场景
该研究成果可广泛应用于需要LLM Agent与外部工具(如搜索引擎、数据库)交互的复杂任务中,例如智能问答、信息检索、任务规划等。通过提高LLM Agent的搜索策略学习能力,可以显著提升其解决复杂问题的效率和准确性,具有重要的实际应用价值和商业潜力。
📄 摘要(原文)
Large language model (LLM) agents increasingly rely on external tools such as search engines to solve complex, multi-step problems, and reinforcement learning (RL) has become a key paradigm for training them. However, the trajectories of search agents are structurally heterogeneous, where variations in the number, placement, and outcomes of search calls lead to fundamentally different answer directions and reward distributions. Standard policy gradient methods, which use a single global baseline, suffer from what we identify and formalize as cross-stratum bias-an "apples-to-oranges" comparison of heterogeneous trajectories. This cross-stratum bias distorts credit assignment and hinders exploration of complex, multi-step search strategies. To address this, we propose Stratified GRPO, whose central component, Stratified Advantage Normalization (SAN), partitions trajectories into homogeneous strata based on their structural properties and computes advantages locally within each stratum. This ensures that trajectories are evaluated only against their true peers. Our analysis proves that SAN eliminates cross-stratum bias, yields conditionally unbiased unit-variance estimates inside each stratum, and retains the global unbiasedness and unit-variance properties enjoyed by standard normalization, resulting in a more pure and scale-stable learning signal. To improve practical stability under finite-sample regimes, we further linearly blend SAN with the global estimator. Extensive experiments on diverse single-hop and multi-hop question-answering benchmarks demonstrate that Stratified GRPO consistently and substantially outperforms GRPO by up to 11.3 points, achieving higher training rewards, greater training stability, and more effective search policies. These results establish stratification as a principled remedy for structural heterogeneity in RL for LLM search agents.