LLMs as Policy-Agnostic Teammates: A Case Study in Human Proxy Design for Heterogeneous Agent Teams
作者: Aju Ani Justus, Chris Baber
分类: cs.LG, cs.AI, cs.HC
发布日期: 2025-10-07
备注: This is a preprint of a paper presented at the \textit{European Conference on Artificial Intelligence (ECAI 2025)}. It is made publicly available for the benefit of the research community and should be regarded as a preprint rather than a formally reviewed publication
💡 一句话要点
提出利用LLM作为策略无关代理,解决异构智能体团队中人机协作问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 人机协作 异构智能体 大型语言模型 策略无关 合成数据
📋 核心要点
- 异构智能体团队协作面临挑战,尤其是在与策略未知的非平稳人类队友交互时,传统人机交互数据成本高昂。
- 利用大型语言模型(LLM)作为策略无关的人类代理,通过提示工程生成模仿人类决策的合成数据,降低数据收集成本。
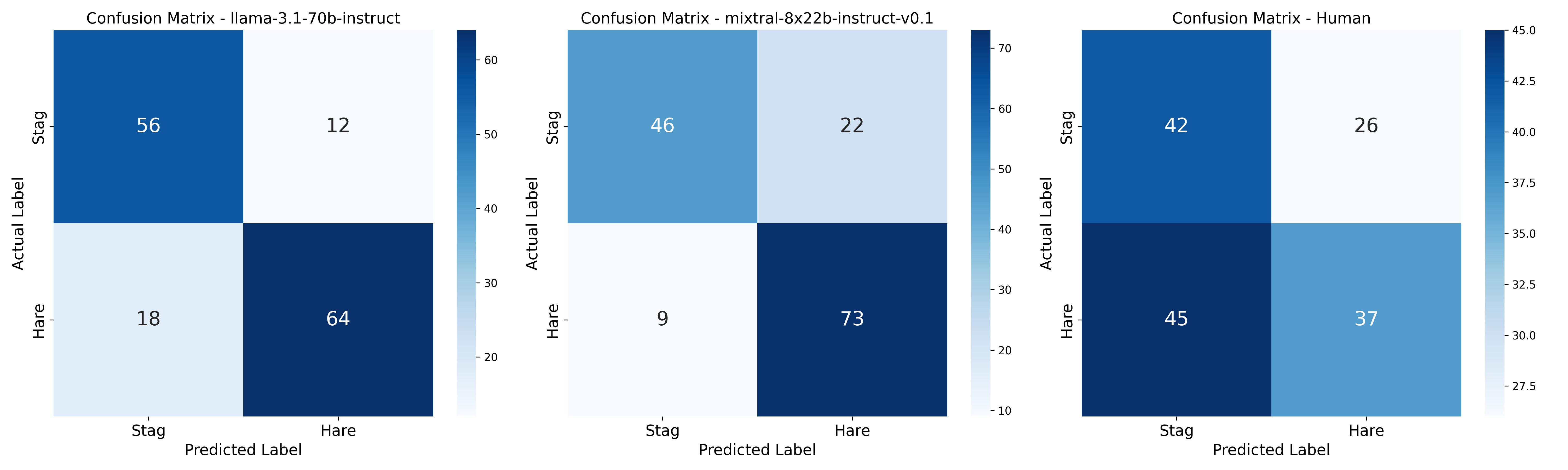
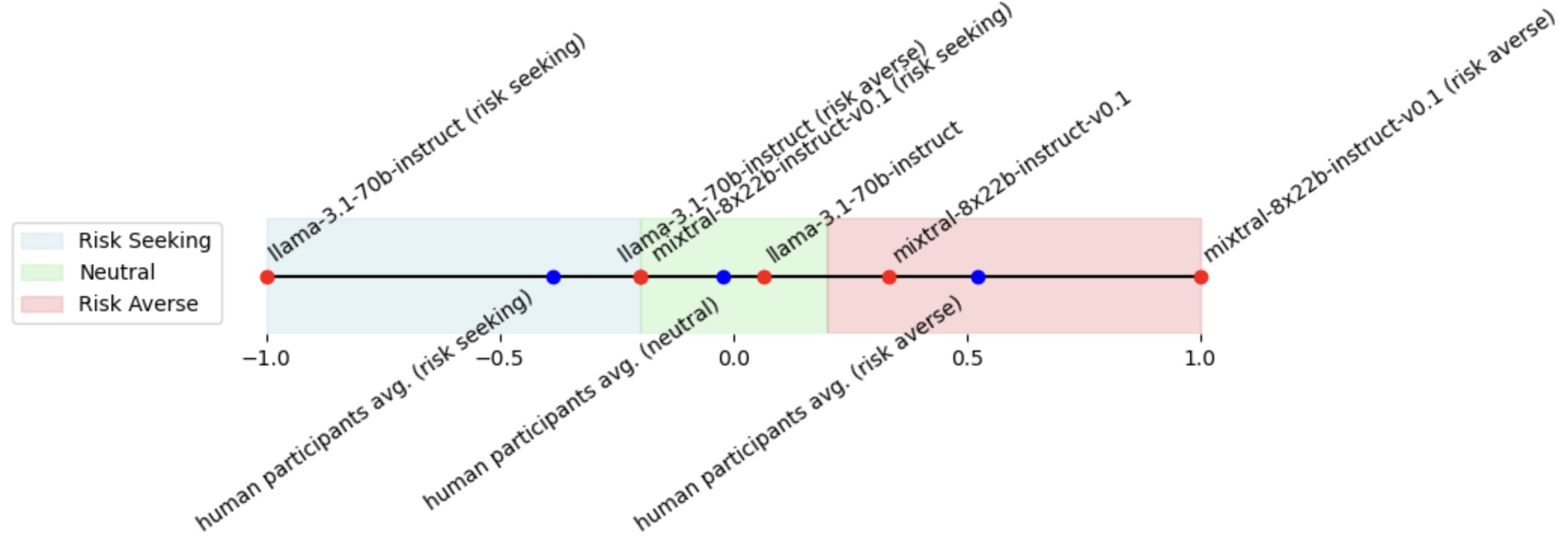
- 实验表明,LLM在特定提示下能模拟人类的风险偏好,并在动态环境中生成类似人类的运动轨迹,为策略无关队友建模提供基础。
📝 摘要(中文)
在建模异构智能体团队时,一个关键挑战是训练智能体与策略不可访问或非平稳的队友(如人类)协作。传统方法依赖于昂贵的人在环数据,限制了可扩展性。本文提出使用大型语言模型(LLM)作为策略无关的人类代理,生成模仿人类决策的合成数据。为了评估该方法,我们在一个受猎鹿博弈启发的网格世界捕获游戏中进行了三个实验,该博弈平衡了风险和回报。实验1比较了30名人类参与者和2名专家判断的决策与LLaMA 3.1和Mixtral 8x22B模型的输出。LLM在游戏状态观察和奖励结构的提示下,比参与者更接近专家,表明在应用底层决策标准方面具有一致性。实验2修改提示以诱导风险敏感策略(例如“规避风险”)。LLM输出反映了人类参与者的可变性,在风险规避和风险寻求行为之间切换。最后,实验3在LLM智能体生成移动动作的动态网格世界中测试LLM。LLM产生类似于人类参与者路径的轨迹。虽然LLM还不能完全复制人类的适应性,但它们在提示指导下的多样性为模拟策略无关的队友提供了可扩展的基础。
🔬 方法详解
问题定义:论文旨在解决异构智能体团队中,智能体与策略不可知的队友(特别是人类)进行有效协作的问题。现有方法主要依赖于大量的人在环数据进行训练,成本高昂且难以扩展。这种方法的痛点在于数据获取的瓶颈,以及难以泛化到不同人类行为模式。
核心思路:论文的核心思路是利用大型语言模型(LLM)的强大泛化能力和上下文理解能力,将其作为人类决策的代理模型。通过精心设计的提示(Prompt),引导LLM模拟人类在特定情境下的决策过程,从而生成高质量的合成数据。这种方法避免了直接与人类交互,降低了数据获取成本,并为训练策略无关的智能体提供了新的途径。
技术框架:整体框架包含以下几个主要阶段:1) 环境建模:构建一个网格世界捕获游戏,模拟智能体之间的协作场景。2) LLM提示设计:设计包含游戏状态观察和奖励结构的提示,引导LLM进行决策。3) LLM决策生成:使用LLM(如LLaMA 3.1和Mixtral 8x22B)根据提示生成动作。4) 行为分析与评估:将LLM生成的决策与人类参与者和专家的决策进行比较,评估LLM的决策质量和行为模式。5) 动态环境测试:在动态网格世界中测试LLM智能体的行为,观察其运动轨迹。
关键创新:最重要的技术创新点在于将LLM作为策略无关的人类代理,用于生成合成数据。与传统的行为克隆或逆强化学习方法不同,该方法不需要访问人类的策略,而是通过提示工程直接引导LLM模拟人类的决策过程。这种方法具有更好的泛化能力和可扩展性,可以应用于更广泛的异构智能体团队协作场景。
关键设计:关键设计包括:1) 提示工程:设计包含游戏状态观察、奖励结构和风险偏好信息的提示,以引导LLM生成不同的行为模式。2) 风险敏感策略诱导:通过修改提示,诱导LLM生成风险规避或风险寻求的行为。3) 动态环境建模:构建动态网格世界,测试LLM智能体在复杂环境中的行为。4) 行为评估指标:使用专家判断、行为相似度等指标评估LLM生成的决策质量。
🖼️ 关键图片

📊 实验亮点
实验结果表明,LLM在特定提示下能够模拟人类的风险偏好,并在动态环境中生成类似人类的运动轨迹。LLM的决策与专家判断更接近,表明其在应用底层决策标准方面具有一致性。通过修改提示,可以诱导LLM生成风险规避或风险寻求的行为,反映了人类参与者的可变性。
🎯 应用场景
该研究成果可应用于机器人、自动驾驶、游戏AI等领域,尤其是在人机协作场景中。通过使用LLM模拟人类队友,可以降低训练成本,提高智能体的泛化能力和协作效率。未来,该方法有望扩展到更复杂的任务和环境,实现更自然、高效的人机协作。
📄 摘要(原文)
A critical challenge in modelling Heterogeneous-Agent Teams is training agents to collaborate with teammates whose policies are inaccessible or non-stationary, such as humans. Traditional approaches rely on expensive human-in-the-loop data, which limits scalability. We propose using Large Language Models (LLMs) as policy-agnostic human proxies to generate synthetic data that mimics human decision-making. To evaluate this, we conduct three experiments in a grid-world capture game inspired by Stag Hunt, a game theory paradigm that balances risk and reward. In Experiment 1, we compare decisions from 30 human participants and 2 expert judges with outputs from LLaMA 3.1 and Mixtral 8x22B models. LLMs, prompted with game-state observations and reward structures, align more closely with experts than participants, demonstrating consistency in applying underlying decision criteria. Experiment 2 modifies prompts to induce risk-sensitive strategies (e.g. "be risk averse"). LLM outputs mirror human participants' variability, shifting between risk-averse and risk-seeking behaviours. Finally, Experiment 3 tests LLMs in a dynamic grid-world where the LLM agents generate movement actions. LLMs produce trajectories resembling human participants' paths. While LLMs cannot yet fully replicate human adaptability, their prompt-guided diversity offers a scalable foundation for simulating policy-agnostic teammates.