Implicit Updates for Average-Reward Temporal Difference Learning
作者: Hwanwoo Kim, Dongkyu Derek Cho, Eric Laber
分类: stat.ML, cs.LG
发布日期: 2025-10-07
💡 一句话要点
提出平均奖励隐式TD(λ)算法,提升时序差分学习的数值稳定性和效率
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 强化学习 时序差分学习 平均奖励 隐式更新 数值稳定性
📋 核心要点
- 标准平均奖励TD(λ)对步长敏感,需要精细调整以保证数值稳定,这是核心问题。
- 提出平均奖励隐式TD(λ),利用隐式不动点更新实现数据自适应稳定,同时保持计算效率。
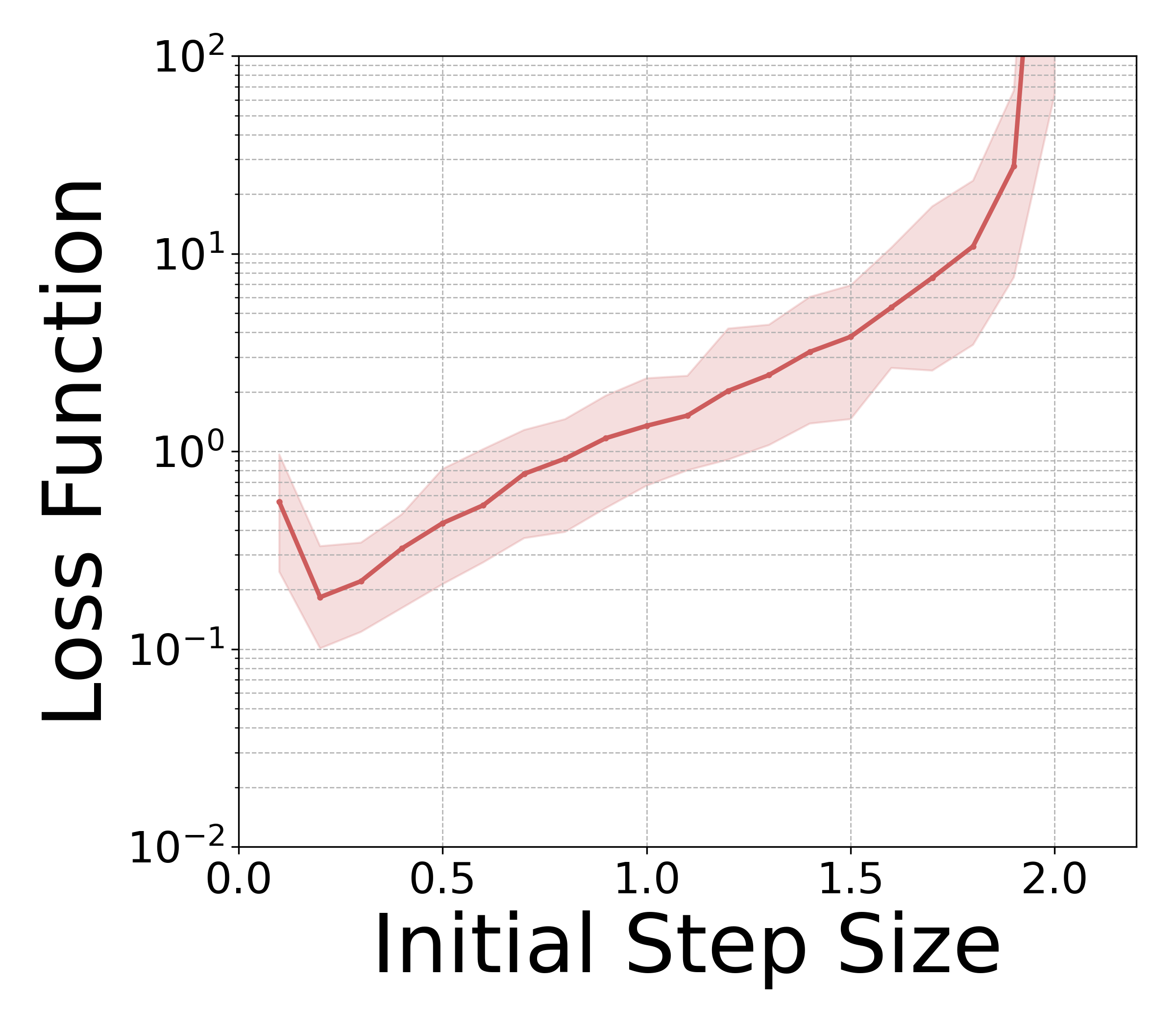
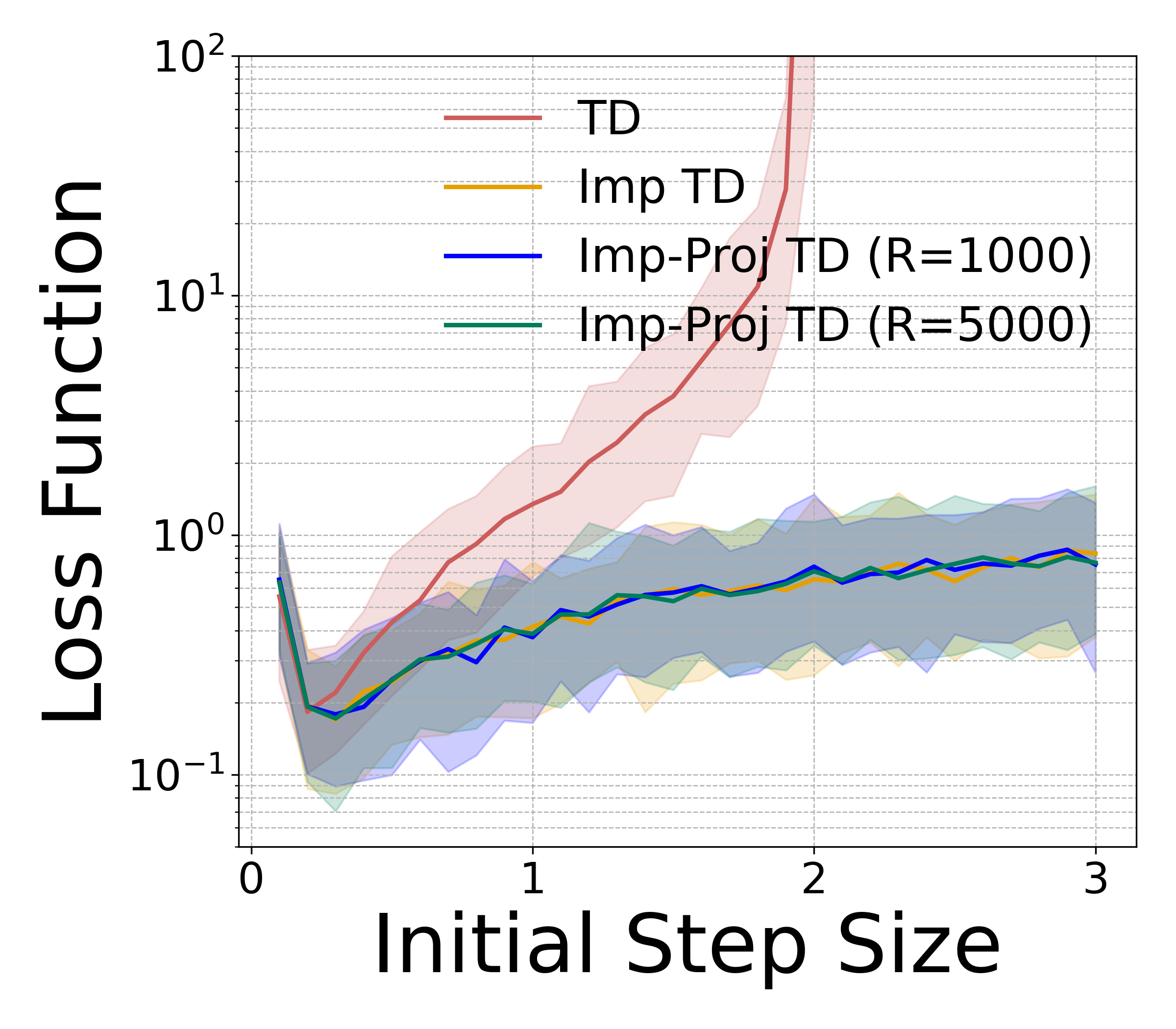
- 实验表明,该方法在更广步长范围内稳定运行,数值稳定性显著提升,策略评估和学习更高效。
📝 摘要(中文)
时序差分(TD)学习是强化学习的基石。在平均奖励设置中,标准TD(λ)对步长的选择非常敏感,因此需要仔细调整以保持数值稳定性。本文提出平均奖励隐式TD(λ),它采用隐式不动点更新来提供数据自适应的稳定,同时保持标准平均奖励TD(λ)的每次迭代计算复杂度。与先前对平均奖励TD(λ)的有限时间分析(施加了严格的步长条件)相比,我们建立了在显著较弱的步长要求下隐式变体的有限时间误差界限。经验表明,平均奖励隐式TD(λ)在更广泛的步长范围内可靠地运行,并表现出显著改善的数值稳定性。这使得更有效的策略评估和策略学习成为可能,突显了其作为平均奖励TD(λ)的稳健替代方案的有效性。
🔬 方法详解
问题定义:论文旨在解决平均奖励强化学习中,标准TD(λ)算法对步长选择过于敏感,导致数值不稳定,需要耗费大量精力调参的问题。现有方法通常需要施加严格的步长条件才能保证收敛性,限制了其应用范围。
核心思路:论文的核心思路是引入隐式更新机制,通过求解一个不动点方程来更新TD(λ)算法中的参数。这种隐式更新能够提供数据自适应的稳定效果,从而降低对步长选择的敏感性,允许使用更大的步长,加速学习过程。
技术框架:整体框架仍然是基于TD(λ)的强化学习算法,主要改进在于TD更新的计算方式。具体流程如下:1. 收集环境交互数据;2. 使用隐式更新公式计算TD误差和价值函数的更新量;3. 更新价值函数和平均奖励;4. 重复以上步骤直到收敛。
关键创新:最重要的创新点在于使用隐式不动点更新来替代显式更新。与传统TD(λ)算法直接使用当前数据更新参数不同,隐式TD(λ)通过求解一个关于参数更新量的方程来确定更新方向和大小。这种方式能够有效地抑制由于步长过大或数据噪声引起的震荡,从而提高数值稳定性。
关键设计:关键设计在于如何高效地求解隐式更新方程。论文中采用了一种迭代方法来近似求解不动点,并在每次迭代中保持与标准TD(λ)算法相同的计算复杂度。此外,论文还给出了在较弱步长条件下隐式TD(λ)算法的有限时间误差界限,为算法的收敛性提供了理论保证。
🖼️ 关键图片
📊 实验亮点
实验结果表明,平均奖励隐式TD(λ)在更广泛的步长范围内表现出可靠的性能,并且数值稳定性显著优于标准平均奖励TD(λ)。这意味着可以使用更大的步长来加速学习过程,同时避免由于步长选择不当导致的算法发散。该方法在策略评估和策略学习任务中均取得了显著的性能提升。
🎯 应用场景
该研究成果可应用于各种需要长期稳定运行的强化学习任务,例如机器人控制、资源调度、推荐系统等。通过提高算法的数值稳定性和鲁棒性,可以减少人工干预,降低调参成本,加速算法的部署和应用。尤其是在环境动态变化或奖励稀疏的场景下,该方法具有更大的优势。
📄 摘要(原文)
Temporal difference (TD) learning is a cornerstone of reinforcement learning. In the average-reward setting, standard TD($λ$) is highly sensitive to the choice of step-size and thus requires careful tuning to maintain numerical stability. We introduce average-reward implicit TD($λ$), which employs an implicit fixed point update to provide data-adaptive stabilization while preserving the per iteration computational complexity of standard average-reward TD($λ$). In contrast to prior finite-time analyses of average-reward TD($λ$), which impose restrictive step-size conditions, we establish finite-time error bounds for the implicit variant under substantially weaker step-size requirements. Empirically, average-reward implicit TD($λ$) operates reliably over a much broader range of step-sizes and exhibits markedly improved numerical stability. This enables more efficient policy evaluation and policy learning, highlighting its effectiveness as a robust alternative to average-reward TD($λ$).