lm-Meter: Unveiling Runtime Inference Latency for On-Device Language Models
作者: Haoxin Wang, Xiaolong Tu, Hongyu Ke, Huirong Chai, Dawei Chen, Kyungtae Han
分类: cs.LG, cs.PF
发布日期: 2025-10-07
备注: This is the preprint version of the paper accepted to The 10th ACM/IEEE Symposium on Edge Computing (SEC 2025)
🔗 代码/项目: GITHUB
💡 一句话要点
lm-Meter:揭示设备端语言模型的运行时推理延迟瓶颈
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 设备端LLM 推理延迟 性能分析 在线分析 移动平台
📋 核心要点
- 现有设备端LLM推理缺乏细粒度的性能分析工具,难以优化资源受限设备上的推理效率。
- lm-Meter通过轻量级的在线延迟分析,在阶段和内核级别实时捕获LLM推理的延迟信息。
- 实验表明,lm-Meter具有高精度和低开销,可有效识别设备端LLM推理的瓶颈并指导优化。
📝 摘要(中文)
大型语言模型(LLM)正日益融入日常应用,但其普遍的云端部署引发了对数据隐私和长期可持续性的担忧。在移动和边缘设备上本地运行LLM(设备端LLM)有望增强隐私、可靠性并降低通信成本。然而,由于巨大的内存和计算需求,以及对资源受限硬件上性能效率权衡的有限可见性,实现这一愿景仍然具有挑战性。我们提出了lm-Meter,这是第一个轻量级的在线延迟分析器,专为设备端LLM推理而定制。lm-Meter无需辅助设备即可捕获阶段(例如,嵌入、预填充、解码、softmax、采样)和内核级别的细粒度、实时延迟。我们在商业移动平台上实现了lm-Meter,并证明了其高分析精度和最小的系统开销,例如,在最受限的Powersave governor下,预填充的吞吐量降低仅为2.58%,解码的吞吐量降低仅为0.99%。利用lm-Meter,我们进行了全面的实证研究,揭示了设备端LLM推理中的阶段和内核级瓶颈,量化了精度-效率的权衡,并确定了系统的优化机会。lm-Meter为受限平台上LLM的运行时行为提供了前所未有的可见性,为知情的优化奠定了基础,并加速了设备端LLM系统的普及。代码和教程可在https://github.com/amai-gsu/LM-Meter获取。
🔬 方法详解
问题定义:论文旨在解决设备端LLM推理缺乏有效性能分析工具的问题。现有方法要么依赖离线分析,要么引入显著的性能开销,无法实时、细粒度地分析LLM在资源受限设备上的推理延迟,阻碍了针对性优化。
核心思路:论文的核心思路是设计一个轻量级的在线延迟分析器,能够在不显著影响LLM推理性能的前提下,实时捕获阶段和内核级别的细粒度延迟信息。通过这种方式,可以准确识别推理瓶颈,指导优化方向。
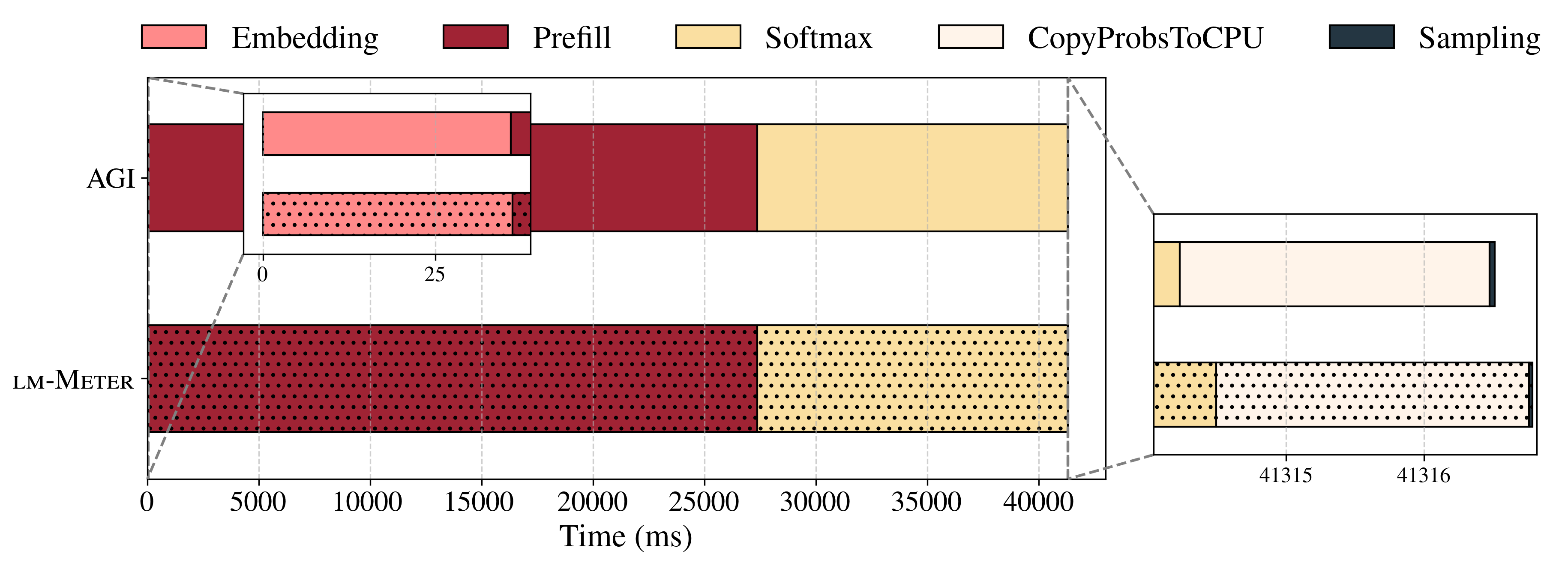
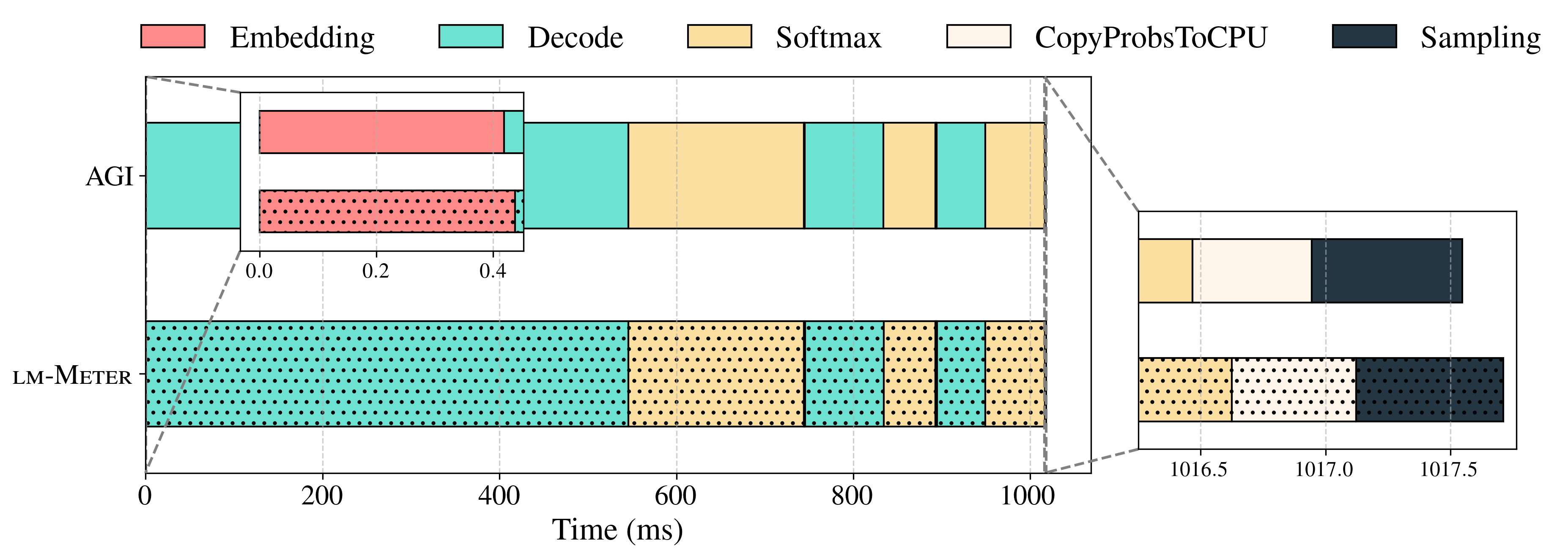
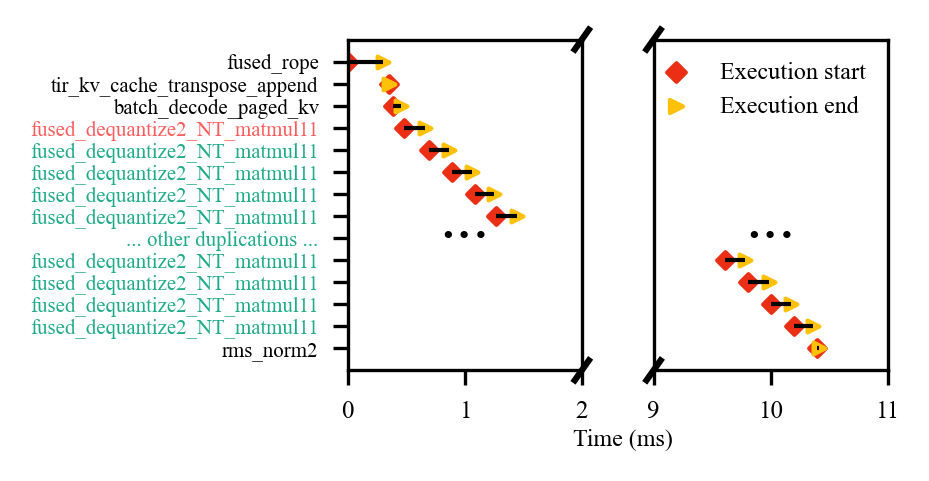
技术框架:lm-Meter的整体框架包括以下几个主要模块:1) 嵌入层延迟分析;2) 预填充阶段延迟分析;3) 解码阶段延迟分析;4) Softmax层延迟分析;5) 采样阶段延迟分析。每个模块都设计了特定的探针,用于捕获对应阶段的延迟信息。这些探针以低开销的方式集成到LLM推理流程中,实现实时监控。
关键创新:lm-Meter的关键创新在于其轻量级的在线分析方法。与传统的离线分析方法相比,lm-Meter能够实时捕获延迟信息,更准确地反映LLM在实际运行环境中的性能表现。此外,lm-Meter的探针设计尽可能减少了对LLM推理流程的干扰,保证了分析的准确性。
关键设计:lm-Meter的关键设计包括:1) 探针的轻量化设计,采用低开销的计时器和回调函数,避免引入显著的性能开销;2) 阶段和内核级别的细粒度分析,能够准确识别推理瓶颈;3) 动态调整分析频率,根据系统负载自动调整探针的采样频率,保证分析的准确性和效率。
🖼️ 关键图片
📊 实验亮点
lm-Meter在商业移动平台上进行了验证,实验结果表明,在最受限的Powersave governor下,预填充阶段的吞吐量降低仅为2.58%,解码阶段的吞吐量降低仅为0.99%。这表明lm-Meter具有高精度和低开销,能够有效识别设备端LLM推理的瓶颈。
🎯 应用场景
lm-Meter可用于优化设备端LLM的部署和推理效率,提升移动设备和边缘设备的AI能力。通过识别性能瓶颈,开发者可以针对性地优化模型结构、算子实现和硬件配置,从而在资源受限的平台上实现更高效的LLM推理。这有助于推动LLM在隐私保护、低延迟应用等领域的普及。
📄 摘要(原文)
Large Language Models (LLMs) are increasingly integrated into everyday applications, but their prevalent cloud-based deployment raises growing concerns around data privacy and long-term sustainability. Running LLMs locally on mobile and edge devices (on-device LLMs) offers the promise of enhanced privacy, reliability, and reduced communication costs. However, realizing this vision remains challenging due to substantial memory and compute demands, as well as limited visibility into performance-efficiency trade-offs on resource-constrained hardware. We propose lm-Meter, the first lightweight, online latency profiler tailored for on-device LLM inference. lm-Meter captures fine-grained, real-time latency at both phase (e.g., embedding, prefill, decode, softmax, sampling) and kernel levels without auxiliary devices. We implement lm-Meter on commercial mobile platforms and demonstrate its high profiling accuracy with minimal system overhead, e.g., only 2.58% throughput reduction in prefill and 0.99% in decode under the most constrained Powersave governor. Leveraging lm-Meter, we conduct comprehensive empirical studies revealing phase- and kernel-level bottlenecks in on-device LLM inference, quantifying accuracy-efficiency trade-offs, and identifying systematic optimization opportunities. lm-Meter provides unprecedented visibility into the runtime behavior of LLMs on constrained platforms, laying the foundation for informed optimization and accelerating the democratization of on-device LLM systems. Code and tutorials are available at https://github.com/amai-gsu/LM-Meter.