Influence Functions for Efficient Data Selection in Reasoning
作者: Prateek Humane, Paolo Cudrano, Daniel Z. Kaplan, Matteo Matteucci, Supriyo Chakraborty, Irina Rish
分类: cs.LG, cs.CL
发布日期: 2025-10-07 (更新: 2025-12-01)
备注: 4 pages, 2 figures; added link to codebase
💡 一句话要点
提出基于影响函数的CoT数据选择方法,提升LLM推理性能
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 链式思考 数据选择 影响函数 推理 微调 数据质量
📋 核心要点
- 现有方法在选择用于微调LLM的CoT数据时,依赖间接启发式方法,缺乏对数据质量的直接度量。
- 论文提出使用影响函数来量化CoT数据对下游推理性能的因果影响,以此作为数据质量的度量标准。
- 实验表明,基于影响函数的CoT数据选择方法在数学推理任务上优于基于困惑度和嵌入的基线方法。
📝 摘要(中文)
本文研究了在链式思考(CoT)数据上微调大型语言模型(LLM)的问题,发现少量高质量数据可以胜过海量数据集。然而,“质量”的定义仍然模糊。现有推理方法依赖于问题难度或轨迹长度等间接启发式方法,而指令调优则探索了更广泛的自动选择策略,但很少在推理的背景下进行。本文提出使用影响函数来定义推理数据质量,该函数衡量单个CoT示例对下游准确性的因果影响,并引入基于影响的剪枝方法,该方法在模型家族内的数学推理方面始终优于困惑度和基于嵌入的基线。
🔬 方法详解
问题定义:论文旨在解决如何高效地选择高质量的链式思考(CoT)数据,以提升大型语言模型(LLM)在推理任务上的性能。现有方法,如基于问题难度或轨迹长度的启发式方法,以及指令调优中的自动选择策略,都未能直接有效地衡量CoT数据的质量,导致微调后的模型性能提升有限。
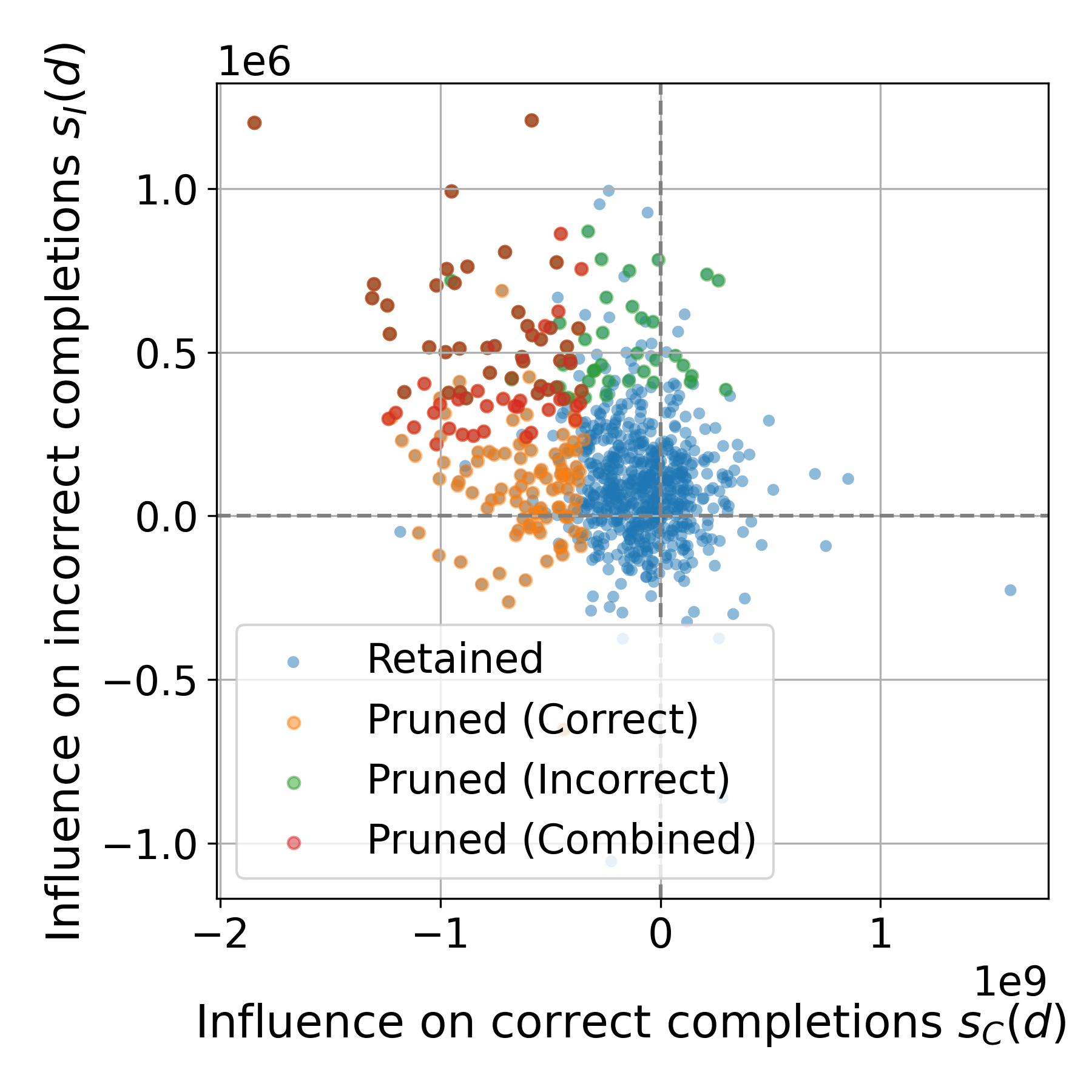
核心思路:论文的核心思路是利用影响函数来衡量每个CoT样本对下游推理准确性的因果影响。影响函数能够评估删除或修改某个训练样本对模型预测结果的影响,从而可以量化该样本对模型性能的贡献程度。通过选择对模型性能提升贡献最大的CoT样本,可以实现更高效的数据选择和微调。
技术框架:论文提出的方法主要包含以下几个阶段:1) 使用LLM生成CoT数据;2) 计算每个CoT样本的影响函数值,该值反映了该样本对下游推理准确性的影响;3) 基于影响函数值对CoT数据进行排序,选择影响函数值最高的样本子集;4) 使用选择的CoT数据子集对LLM进行微调。
关键创新:论文的关键创新在于将影响函数应用于CoT数据的选择,从而能够直接量化每个CoT样本对下游推理性能的贡献。与现有方法相比,该方法不再依赖于间接的启发式规则,而是基于数据驱动的方式选择高质量的CoT样本。
关键设计:论文中影响函数的计算采用标准的Hessian inverse approximation方法。具体来说,首先计算模型在训练数据上的损失函数梯度,然后使用Hessian矩阵的逆来近似计算影响函数值。为了提高计算效率,论文可能采用了诸如随机梯度下降或共轭梯度法等优化算法来近似计算Hessian矩阵的逆。此外,论文可能还探索了不同的CoT数据生成策略和微调方法,以进一步提升模型性能。具体的参数设置、损失函数和网络结构等技术细节需要在论文原文中查找。
🖼️ 关键图片
📊 实验亮点
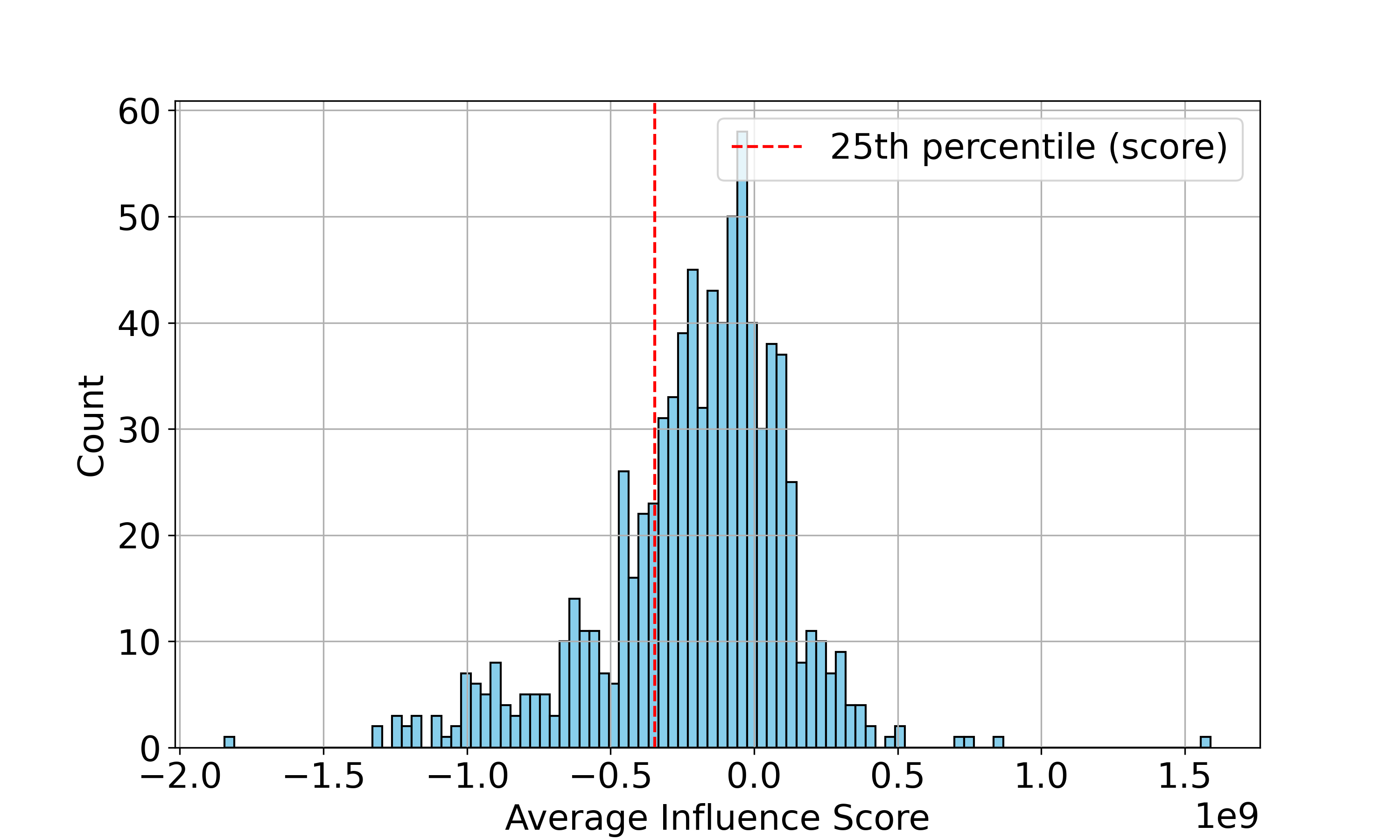
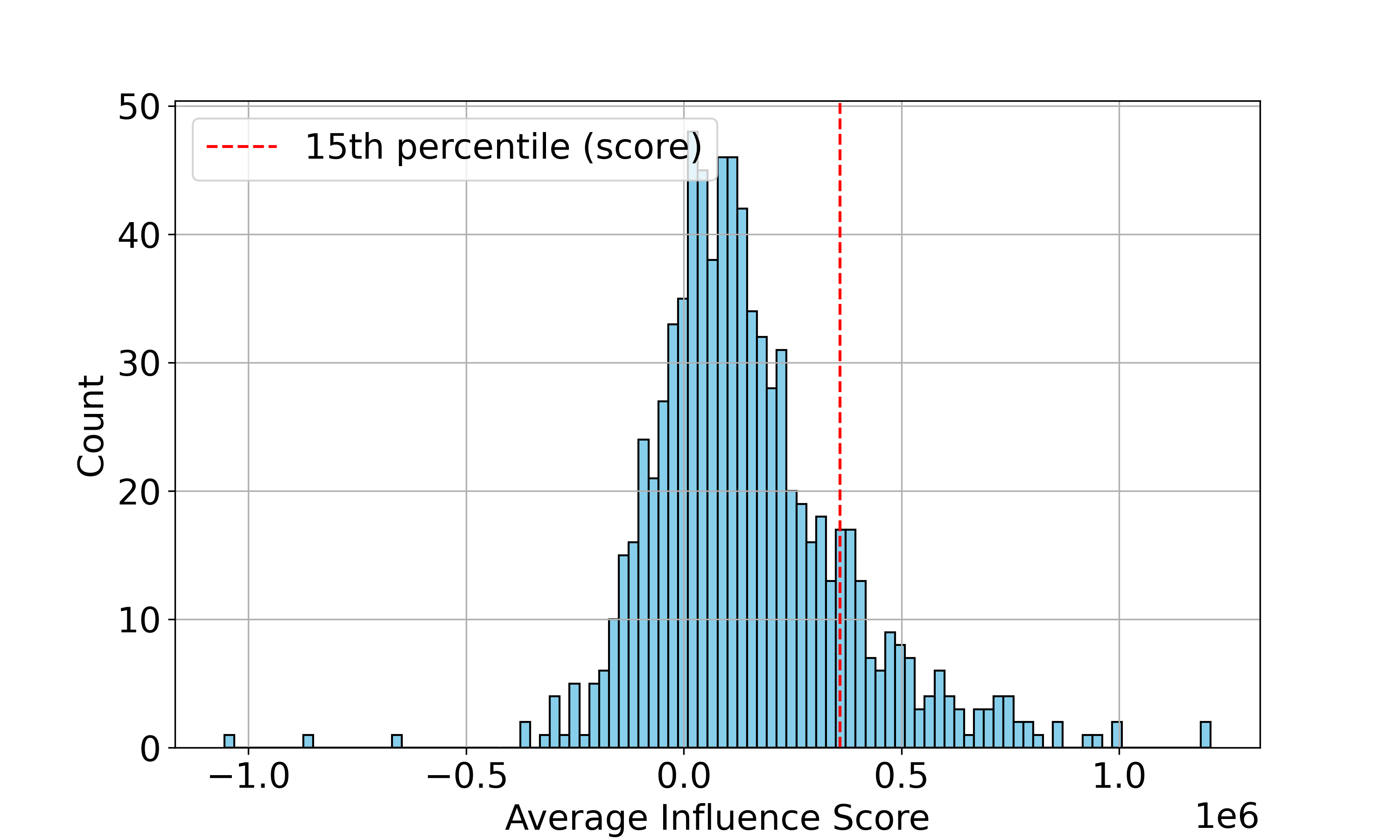
实验结果表明,基于影响函数的CoT数据选择方法在数学推理任务上显著优于基于困惑度和基于嵌入的基线方法。具体来说,在相同的模型家族内,使用基于影响函数的剪枝方法选择的CoT数据进行微调后,模型的推理准确率得到了显著提升,证明了该方法在提升LLM推理性能方面的有效性。
🎯 应用场景
该研究成果可应用于各种需要利用大型语言模型进行推理的任务,例如数学问题求解、常识推理、代码生成等。通过高效地选择高质量的训练数据,可以显著降低模型训练成本,提高模型推理性能,并加速LLM在实际场景中的部署和应用。此外,该方法还可以用于评估和筛选已有的CoT数据集,从而构建更高质量的推理数据集。
📄 摘要(原文)
Fine-tuning large language models (LLMs) on chain-of-thought (CoT) data shows that a small amount of high-quality data can outperform massive datasets. Yet, what constitutes "quality" remains ill-defined. Existing reasoning methods rely on indirect heuristics such as problem difficulty or trace length, while instruction-tuning has explored a broader range of automated selection strategies, but rarely in the context of reasoning. We propose to define reasoning data quality using influence functions, which measure the causal effect of individual CoT examples on downstream accuracy, and introduce influence-based pruning, which consistently outperforms perplexity and embedding-based baselines on math reasoning within a model family.