The Alignment Auditor: A Bayesian Framework for Verifying and Refining LLM Objectives
作者: Matthieu Bou, Nyal Patel, Arjun Jagota, Satyapriya Krishna, Sonali Parbhoo
分类: cs.LG, cs.CL
发布日期: 2025-10-07 (更新: 2025-10-08)
备注: Preprint
💡 一句话要点
提出贝叶斯框架以验证和优化大语言模型目标
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 贝叶斯逆强化学习 目标推断 模型审计 对齐技术 不确定性分析 安全性评估
📋 核心要点
- 现有方法在推断大语言模型的目标时,往往产生过于自信的奖励估计,且未能有效解决不可识别性问题。
- 本文提出了一种基于贝叶斯逆强化学习的审计框架,旨在通过验证过程来恢复目标分布,并提供多项审计能力。
- 实验表明,该框架能够成功审计去毒化的LLM,得到的目标具有良好的校准性和可解释性,提升了对齐的可靠性。
📝 摘要(中文)
大语言模型(LLMs)隐含优化的目标往往不透明,使得可信的对齐和审计成为一项重大挑战。逆强化学习(IRL)虽然可以从行为中推断奖励函数,但现有方法要么产生单一且过于自信的奖励估计,要么未能解决任务的根本模糊性(不可识别性)。本文提出了一种原则性的审计框架,将奖励推断从简单的估计任务重新构建为全面的验证过程。该框架利用贝叶斯IRL,不仅恢复目标的分布,还实现了三项关键审计能力:量化并系统性地减少不可识别性,提供可操作的、不确定性意识的诊断,以及验证政策级效用。实验证明,该框架成功审计了去毒化的LLM,得到了良好校准和可解释的目标,增强了对齐保证。
🔬 方法详解
问题定义:本文旨在解决大语言模型目标推断中的不透明性和不可识别性问题。现有方法往往只能提供单一的奖励估计,缺乏对目标分布的全面理解。
核心思路:通过引入贝叶斯逆强化学习,本文将奖励推断视为一个验证过程,而非简单的估计任务,从而能够恢复目标的分布并提供更可靠的审计能力。
技术框架:该框架包括三个主要模块:首先,通过贝叶斯推断量化不可识别性;其次,提供不确定性意识的诊断工具;最后,验证政策级效用,确保优化的奖励可以在强化学习中有效使用。
关键创新:最重要的创新在于将奖励推断转变为一个系统的验证过程,允许对目标分布进行全面的审计,而不仅仅是单一的估计。这种方法显著提高了对齐的可靠性和透明度。
关键设计:框架中采用了贝叶斯推断技术,通过后验收缩来减少不可识别性,并设计了针对不确定性诊断的工具,以识别不可信的提示和潜在的偏差。
🖼️ 关键图片

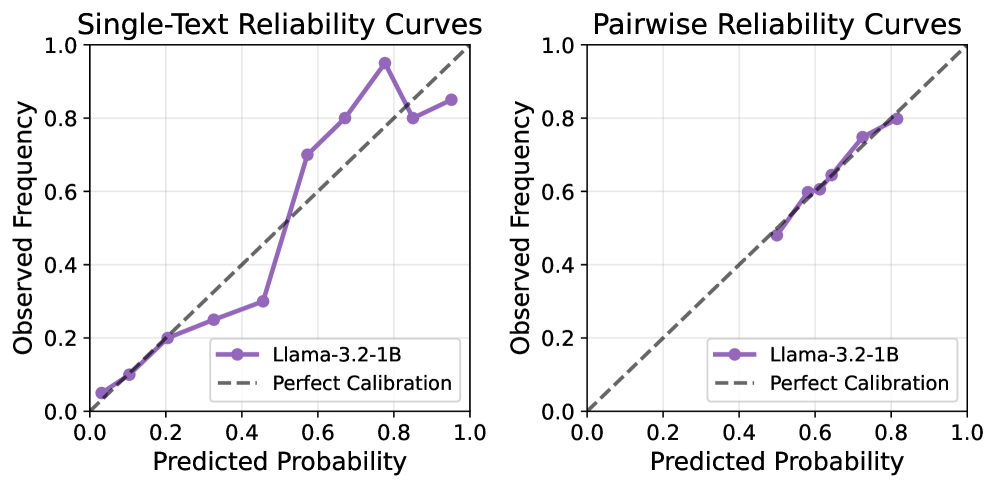

📊 实验亮点
实验结果显示,使用该框架审计的去毒化LLM,其目标的校准性和可解释性显著提升,验证的奖励在强化学习中的应用效果与真实对齐过程相当,展示了良好的训练动态和毒性降低效果。
🎯 应用场景
该研究为大语言模型的审计和对齐提供了一种实用工具,适用于审计员、安全团队和监管机构。通过验证模型的真实目标,能够提高AI系统的透明度和可信度,推动更安全的人工智能应用。
📄 摘要(原文)
The objectives that Large Language Models (LLMs) implicitly optimize remain dangerously opaque, making trustworthy alignment and auditing a grand challenge. While Inverse Reinforcement Learning (IRL) can infer reward functions from behaviour, existing approaches either produce a single, overconfident reward estimate or fail to address the fundamental ambiguity of the task (non-identifiability). This paper introduces a principled auditing framework that re-frames reward inference from a simple estimation task to a comprehensive process for verification. Our framework leverages Bayesian IRL to not only recover a distribution over objectives but to enable three critical audit capabilities: (i) Quantifying and systematically reducing non-identifiability by demonstrating posterior contraction over sequential rounds of evidence; (ii) Providing actionable, uncertainty-aware diagnostics that expose spurious shortcuts and identify out-of-distribution prompts where the inferred objective cannot be trusted; and (iii) Validating policy-level utility by showing that the refined, low-uncertainty reward can be used directly in RLHF to achieve training dynamics and toxicity reductions comparable to the ground-truth alignment process. Empirically, our framework successfully audits a detoxified LLM, yielding a well-calibrated and interpretable objective that strengthens alignment guarantees. Overall, this work provides a practical toolkit for auditors, safety teams, and regulators to verify what LLMs are truly trying to achieve, moving us toward more trustworthy and accountable AI.