Learning from Failures: Understanding LLM Alignment through Failure-Aware Inverse RL
作者: Nyal Patel, Matthieu Bou, Arjun Jagota, Satyapriya Krishna, Sonali Parbhoo
分类: cs.LG, cs.CL
发布日期: 2025-10-07 (更新: 2026-01-17)
备注: Preprint
💡 一句话要点
提出Failure-aware IRL,通过关注失败案例提升LLM对齐效果
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 逆强化学习 大型语言模型对齐 人类反馈强化学习 奖励函数学习 失败案例分析
📋 核心要点
- 现有IRL方法在提取LLM的潜在奖励信号时,未能充分利用错误分类或难以区分的“失败”案例。
- Failure-aware IRL算法通过聚焦这些“失败”案例,学习更准确反映RLHF真实目标的奖励函数。
- 实验表明,Failure-aware IRL在LLM解毒任务中优于现有IRL方法,并能提升re-RLHF训练效果。
📝 摘要(中文)
通过人类反馈的强化学习(RLHF)使大型语言模型(LLM)与人类偏好对齐,但其内部化的潜在奖励信号仍然隐藏,这对可解释性和安全性提出了严峻挑战。现有方法尝试使用逆强化学习(IRL)提取这些潜在激励,但平等对待所有偏好对,常常忽略了信息量最大的信号:提取的奖励模型错误分类或分配几乎相等分数的示例,我们称之为“失败”。我们提出了一种新颖的“failure-aware”IRL算法,该算法侧重于错误分类或难以区分的示例,以恢复定义模型行为的潜在奖励。通过从这些失败中学习,我们的failure-aware IRL提取的奖励函数能更好地反映RLHF背后的真实目标。我们证明,在LLM解毒方面,failure-aware IRL优于现有的IRL基线,且无需外部分类器或监督。至关重要的是,failure-aware IRL产生的奖励能更好地捕捉RLHF期间学习到的真实激励,从而实现比标准IRL更有效的re-RLHF训练。这确立了failure-aware IRL作为一种稳健、可扩展的方法,用于审计模型对齐并减少IRL过程中的歧义。
🔬 方法详解
问题定义:现有基于IRL的方法在对齐大型语言模型(LLM)时,通常平等对待所有偏好数据,忽略了那些奖励模型难以区分或错误分类的样本(即“失败”样本)。这些“失败”样本实际上包含了关于人类偏好的重要信息,未能有效利用导致学习到的奖励函数不够准确,影响了模型对齐的效果。现有方法缺乏对这些关键样本的关注,导致IRL过程存在歧义。
核心思路:Failure-aware IRL的核心思路是,通过更加关注那些奖励模型难以区分或错误分类的“失败”样本,来更准确地学习人类的偏好。算法认为,这些“失败”样本包含了关于奖励函数边界的重要信息,通过对这些样本进行加权或特殊处理,可以提高学习到的奖励函数的准确性和鲁棒性。这样设计的目的是为了减少IRL过程中的歧义,使学习到的奖励函数更好地反映RLHF的真实目标。
技术框架:Failure-aware IRL的整体框架与标准的IRL类似,但关键在于对损失函数的修改,使其更加关注“失败”样本。具体流程包括:1) 使用RLHF训练后的LLM生成样本对;2) 使用初始奖励模型对样本对进行评分;3) 识别“失败”样本(即评分接近或被错误分类的样本);4) 修改IRL的损失函数,增加对“失败”样本的惩罚或权重;5) 使用修改后的损失函数训练奖励模型;6) 重复步骤2-5,直到奖励模型收敛。
关键创新:Failure-aware IRL最重要的创新点在于其对“失败”样本的关注。与传统IRL方法平等对待所有样本不同,该方法通过识别和加权“失败”样本,使奖励模型更加关注那些难以区分或错误分类的样本,从而提高了学习到的奖励函数的准确性和鲁棒性。这种方法不需要额外的外部分类器或监督信息,可以直接从RLHF的数据中学习。
关键设计:Failure-aware IRL的关键设计在于如何定义和加权“失败”样本。一种方法是设置一个阈值,将评分差异小于该阈值的样本定义为“失败”样本,并增加这些样本在损失函数中的权重。另一种方法是使用交叉熵损失函数,并对错误分类的样本进行加权。具体的权重可以根据样本的评分差异或分类置信度进行调整。此外,还可以使用对抗训练等技术,使奖励模型更加鲁棒。
🖼️ 关键图片
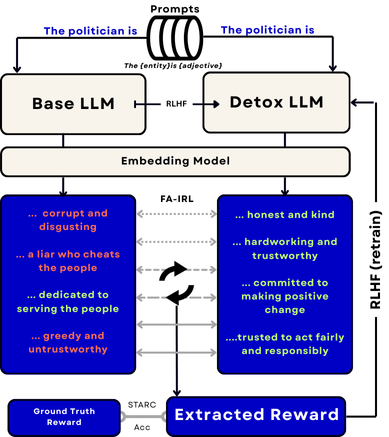
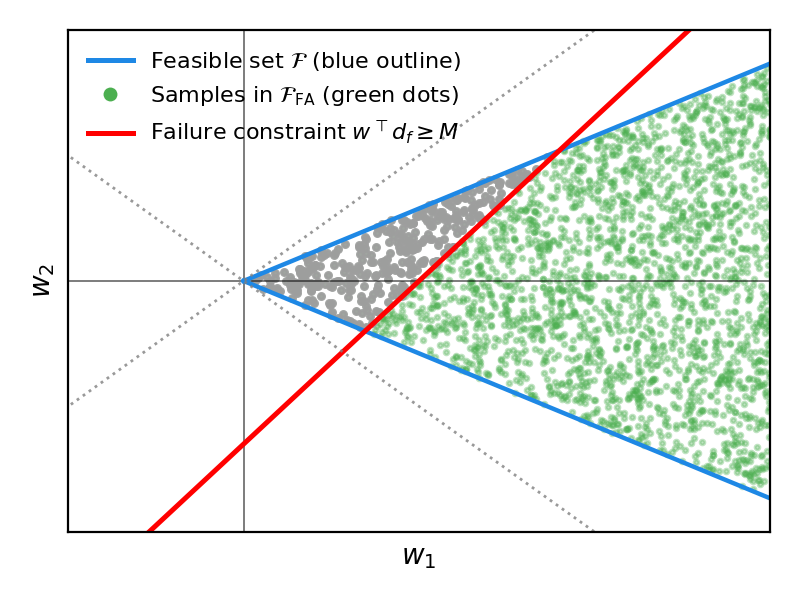
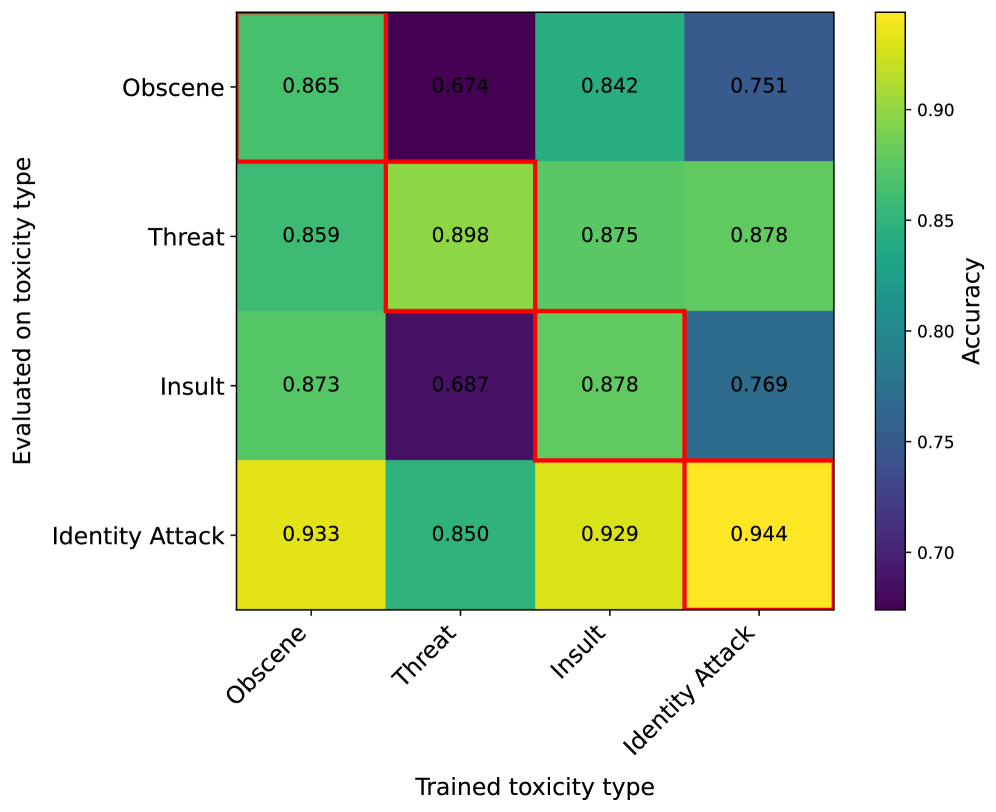
📊 实验亮点
实验结果表明,Failure-aware IRL在LLM解毒任务中优于现有的IRL基线。具体来说,Failure-aware IRL能够学习到更准确的奖励函数,从而更好地识别和过滤有害内容。此外,使用Failure-aware IRL学习到的奖励函数进行re-RLHF训练,能够显著提高模型的安全性和可靠性,优于使用标准IRL学习到的奖励函数。
🎯 应用场景
Failure-aware IRL可应用于审计和改进大型语言模型的对齐过程,例如检测和纠正模型中的偏见或有害行为。通过更准确地提取模型内部的奖励信号,可以更好地理解模型的行为模式,并进行有针对性的干预。此外,该方法还可以用于优化RLHF训练过程,提高模型对齐的效率和效果。该技术在安全、可靠的人工智能系统开发中具有重要价值。
📄 摘要(原文)
Reinforcement Learning from Human Feedback (RLHF) aligns Large Language Models (LLMs) with human preferences, yet the underlying reward signals they internalize remain hidden, posing a critical challenge for interpretability and safety. Existing approaches attempt to extract these latent incentives using Inverse Reinforcement Learning (IRL), but treat all preference pairs equally, often overlooking the most informative signals: those examples the extracted reward model misclassifies or assigns nearly equal scores, which we term \emph{failures}. We introduce a novel \emph{failure-aware} IRL algorithm that focuses on misclassified or difficult examples to recover the latent rewards defining model behaviors. By learning from these failures, our failure-aware IRL extracts reward functions that better reflect the true objectives behind RLHF. We demonstrate that failure-aware IRL outperforms existing IRL baselines across multiple metrics when applied to LLM detoxification, without requiring external classifiers or supervision. Crucially, failure-aware IRL yields rewards that better capture the true incentives learned during RLHF, enabling more effective re-RLHF training than standard IRL. This establishes failure-aware IRL as a robust, scalable method for auditing model alignment and reducing ambiguity in the IRL process.