BLISS: A Lightweight Bilevel Influence Scoring Method for Data Selection in Language Model Pretraining
作者: Jie Hao, Rui Yu, Wei Zhang, Huixia Wang, Jie Xu, Mingrui Liu
分类: cs.LG
发布日期: 2025-10-07 (更新: 2026-02-02)
💡 一句话要点
提出BLISS:一种轻量级的双层影响评分方法,用于语言模型预训练中的数据选择。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 数据选择 语言模型预训练 双层优化 影响评分 轻量级方法
📋 核心要点
- 现有数据选择方法依赖外部预训练模型,难以区分数据选择本身的效果,且忽略了训练至收敛时数据的长期影响。
- BLISS使用小型代理模型和评分模型,通过双层优化估计训练样本的长期影响,从而选择高质量数据。
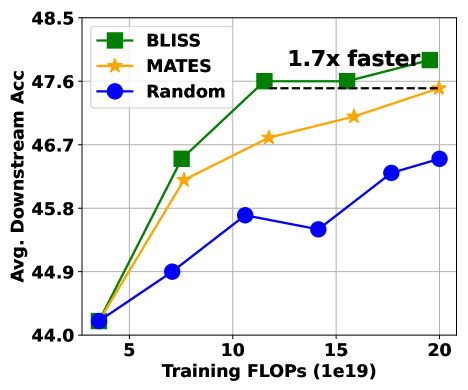
- 实验表明,BLISS在1B模型设置下,达到相同性能的速度是最先进方法的1.7倍,并在多个下游任务中表现出色。
📝 摘要(中文)
有效的数据选择对于预训练大型语言模型(LLMs)至关重要,它可以提高效率并改善对下游任务的泛化能力。然而,现有方法通常需要利用外部预训练模型,这使得难以将数据选择的效果与外部预训练模型的效果区分开来。此外,如果模型训练到收敛,它们通常会忽略所选数据的长期影响,这主要是由于全面LLM预训练的成本过高。在本文中,我们介绍BLISS(用于数据选择的双层影响评分方法):一种轻量级的数据选择方法,它完全从头开始运行,不依赖于任何外部预训练的oracle模型,同时明确考虑了所选数据的长期影响。BLISS利用一个小型代理模型作为LLM的替代,并采用评分模型来估计训练样本的长期影响(如果代理模型训练到收敛)。我们将数据选择公式化为一个双层优化问题,其中上层目标优化评分模型,为训练样本分配重要性权重,确保最小化下层目标(即,在加权训练损失上训练代理模型直到收敛)能够带来最佳的验证性能。一旦优化,训练后的评分模型会预测数据集的影响分数,从而能够有效地选择高质量的样本用于LLM预训练。我们通过在C4数据集的选定子集上预训练410M/1B/2.8B Pythia和LLaMA-0.5B模型来验证BLISS。值得注意的是,在1B模型设置下,BLISS在达到与最先进方法相同的性能时实现了1.7倍的加速,证明了其在多个下游任务中的卓越性能。
🔬 方法详解
问题定义:论文旨在解决大型语言模型预训练中数据选择的问题。现有方法主要痛点在于依赖外部预训练模型,导致数据选择效果与预训练模型效果混淆,且忽略了数据对模型长期训练的影响,预训练成本高昂。
核心思路:论文的核心思路是使用一个轻量级的代理模型来模拟大型语言模型的训练过程,并训练一个评分模型来预测每个训练样本对代理模型长期训练的影响。通过优化评分模型,使得选择出的数据能够使代理模型在验证集上达到最佳性能,从而间接选择出对大型语言模型有益的数据。
技术框架:BLISS方法包含以下主要阶段:1) 使用小型代理模型替代大型语言模型;2) 训练一个评分模型,该模型为每个训练样本分配一个重要性权重;3) 将数据选择问题建模为一个双层优化问题,上层优化评分模型,下层优化代理模型;4) 使用优化后的评分模型对整个数据集进行评分,并选择高分样本用于大型语言模型的预训练。
关键创新:BLISS的关键创新在于其完全从头开始进行数据选择,不依赖任何外部预训练模型,从而避免了混淆数据选择和预训练模型的效果。此外,BLISS显式地考虑了所选数据对模型长期训练的影响,通过代理模型模拟了训练至收敛的过程。
关键设计:BLISS的关键设计包括:1) 使用小型Transformer模型作为代理模型;2) 评分模型可以是任何可以预测样本重要性的模型,例如一个简单的线性模型或神经网络;3) 双层优化问题可以使用梯度下降等方法进行求解,上层目标是验证集上的性能,下层目标是加权训练损失;4) 代理模型的规模和训练时间需要根据实际情况进行调整,以保证其能够有效地模拟大型语言模型的训练过程。
🖼️ 关键图片


📊 实验亮点
BLISS在预训练Pythia和LLaMA模型时表现出色。在1B模型设置下,BLISS达到与最先进方法相同性能的速度提升了1.7倍。此外,在多个下游任务中,使用BLISS选择的数据预训练的模型也表现出优越的性能,验证了该方法的有效性。
🎯 应用场景
BLISS可应用于各种大型语言模型的预训练场景,尤其是在计算资源有限的情况下,能够高效地选择高质量数据,加速模型训练,提升模型性能。该方法还可用于构建更小、更高效的语言模型,降低部署成本,并促进语言模型在边缘设备上的应用。
📄 摘要(原文)
Effective data selection is essential for pretraining large language models (LLMs), enhancing efficiency and improving generalization to downstream tasks. However, existing approaches often require leveraging external pretrained models, making it difficult to disentangle the effects of data selection from those of the external pretrained models. In addition, they often overlook the long-term impact of selected data if the model is trained to convergence, primarily due to the prohibitive cost of full-scale LLM pretraining. In this paper, we introduce BLISS (\textbf{B}ileve\textbf{L} \textbf{I}nfluence \textbf{S}coring method for data \textbf{S}election): a lightweight data selection method that operates entirely \emph{from scratch}, without relying on any external pretrained oracle models, while explicitly accounting for the long-term impact of selected data. BLISS leverages a small proxy model as a surrogate for the LLM and employs a score model to estimate the long-term influence of training samples if the proxy model is trained to convergence. We formulate data selection as a bilevel optimization problem, where the upper-level objective optimizes the score model to assign importance weights to training samples, ensuring that minimizing the lower-level objective (i.e., training the proxy model over the weighted training loss until convergence) leads to best validation performance. Once optimized, the trained score model predicts influence scores for the dataset, enabling efficient selection of high-quality samples for LLM pretraining. We validate BLISS by pretraining 410M/1B/2.8B Pythia and LLaMA-0.5B models on selected subsets of the C4 dataset. Notably, under the 1B model setting, BLISS achieves $1.7\times$ speedup in reaching the same performance as the state-of-the-art method, demonstrating superior performance across multiple downstream tasks.