Gaussian Embeddings: How JEPAs Secretly Learn Your Data Density
作者: Randall Balestriero, Nicolas Ballas, Mike Rabbat, Yann LeCun
分类: cs.LG, cs.AI, cs.CV, stat.ML
发布日期: 2025-10-07
💡 一句话要点
揭示JEPAs的密度估计能力:通过高斯嵌入实现数据密度学习
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 自监督学习 密度估计 联合嵌入 异常检测 数据质量 高斯嵌入
📋 核心要点
- 现有自监督学习方法缺乏对数据密度直接估计的能力,限制了其在数据质量评估和异常检测等方面的应用。
- 论文证明JEPAs架构中的防崩溃项能够有效地估计数据密度,从而为样本赋予可解释的概率。
- 实验表明,通过JEPA学习到的密度估计方法(JEPA-SCORE)在多种数据集和模型上均表现良好,验证了理论发现。
📝 摘要(中文)
联合嵌入预测架构(JEPAs)学习到的表征能够开箱即用地解决众多下游任务。JEPAs结合了两个目标:(i) 潜在空间预测项,即略微扰动样本的表征可以从原始样本的表征中预测;(ii) 防崩溃项,即并非所有样本都应具有相同的表征。虽然(ii)通常被认为是防止表征崩溃的显而易见的补救措施,但我们发现JEPAs的防崩溃项的作用远不止于此——它可证明地估计数据密度。简而言之,任何成功训练的JEPA都可用于获取样本概率,例如用于数据整理、异常值检测或简单地用于密度估计。我们的理论发现与所使用的数据集和架构无关——在任何情况下,都可以使用模型在x处的雅可比矩阵,以高效且闭式的形式计算样本x的学习概率。我们的发现已在数据集(合成、受控和Imagenet)以及属于JEPA系列的各种自监督学习方法(I-JEPA和DINOv2)以及多模态模型(如MetaCLIP)上进行了经验验证。我们将提取JEPA学习到的密度的方法表示为{\bf JEPA-SCORE}。
🔬 方法详解
问题定义:论文旨在解决自监督学习模型缺乏有效的数据密度估计方法的问题。现有的自监督学习方法主要关注学习数据的表征,而忽略了对数据分布的建模,这限制了其在数据质量评估、异常检测等需要概率信息的任务中的应用。
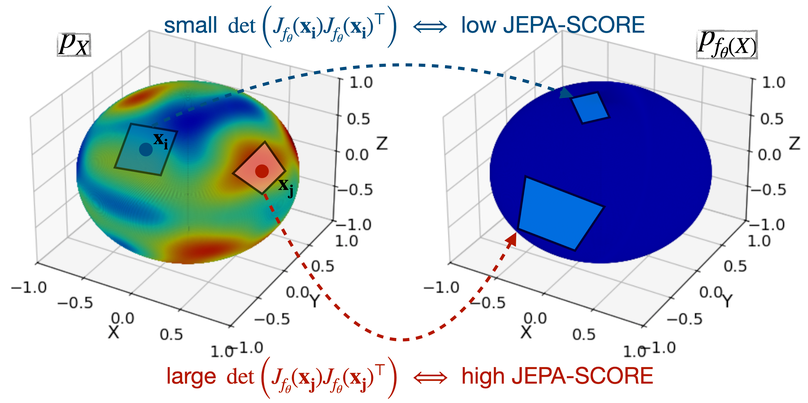
核心思路:论文的核心思路是揭示了JEPAs架构中防崩溃项的内在作用,证明它可以有效地估计数据密度。通过分析JEPAs的损失函数,论文表明防崩溃项实际上是在学习一个高斯嵌入,其方差与数据密度成反比。因此,可以通过JEPAs学习到的表征来推断样本的概率。
技术框架:论文提出的方法JEPA-SCORE主要包含以下步骤:1. 使用JEPAs架构训练一个自监督学习模型。2. 对于给定的样本x,计算模型在x处的雅可比矩阵。3. 使用雅可比矩阵计算样本x的高斯嵌入的方差。4. 根据高斯嵌入的方差估计样本x的概率。整个过程无需额外的训练或微调。
关键创新:论文最重要的技术创新点在于揭示了JEPAs架构中防崩溃项的密度估计能力。与现有方法相比,JEPA-SCORE无需显式地建模数据分布,而是通过利用JEPAs学习到的表征来隐式地估计数据密度。这种方法具有计算效率高、易于实现的优点。
关键设计:论文的理论分析表明,JEPA-SCORE的性能取决于JEPAs模型的训练效果。为了获得准确的密度估计,需要选择合适的JEPAs架构和训练策略,以确保模型能够学习到高质量的表征。此外,雅可比矩阵的计算可以使用自动微分等技术来高效地实现。
🖼️ 关键图片


📊 实验亮点
论文在合成数据、受控数据和Imagenet数据集上验证了JEPA-SCORE的有效性。实验结果表明,JEPA-SCORE能够准确地估计数据密度,并优于传统的密度估计方法。此外,论文还证明了JEPA-SCORE可以应用于不同的JEPAs架构(如I-JEPA和DINOv2)以及多模态模型(如MetaCLIP),表明该方法的通用性。
🎯 应用场景
该研究成果可广泛应用于数据质量评估、异常检测、数据策展等领域。例如,可以利用JEPA-SCORE来识别数据集中的异常样本或噪声数据,从而提高模型的训练效果。此外,还可以将JEPA-SCORE应用于主动学习,选择信息量最大的样本进行标注,从而降低标注成本。该研究为自监督学习在数据理解和质量控制方面的应用提供了新的思路。
📄 摘要(原文)
Joint Embedding Predictive Architectures (JEPAs) learn representations able to solve numerous downstream tasks out-of-the-box. JEPAs combine two objectives: (i) a latent-space prediction term, i.e., the representation of a slightly perturbed sample must be predictable from the original sample's representation, and (ii) an anti-collapse term, i.e., not all samples should have the same representation. While (ii) is often considered as an obvious remedy to representation collapse, we uncover that JEPAs' anti-collapse term does much more--it provably estimates the data density. In short, any successfully trained JEPA can be used to get sample probabilities, e.g., for data curation, outlier detection, or simply for density estimation. Our theoretical finding is agnostic of the dataset and architecture used--in any case one can compute the learned probabilities of sample $x$ efficiently and in closed-form using the model's Jacobian matrix at $x$. Our findings are empirically validated across datasets (synthetic, controlled, and Imagenet) and across different Self Supervised Learning methods falling under the JEPA family (I-JEPA and DINOv2) and on multimodal models, such as MetaCLIP. We denote the method extracting the JEPA learned density as {\bf JEPA-SCORE}.