EARL: Efficient Agentic Reinforcement Learning Systems for Large Language Models
作者: Zheyue Tan, Mustapha Abdullahi, Tuo Shi, Huining Yuan, Zelai Xu, Chao Yu, Boxun Li, Bo Zhao
分类: cs.DC, cs.LG
发布日期: 2025-10-07
💡 一句话要点
EARL:用于大型语言模型的高效Agentic强化学习系统
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: Agentic强化学习 大型语言模型 并行训练 数据调度 系统优化
📋 核心要点
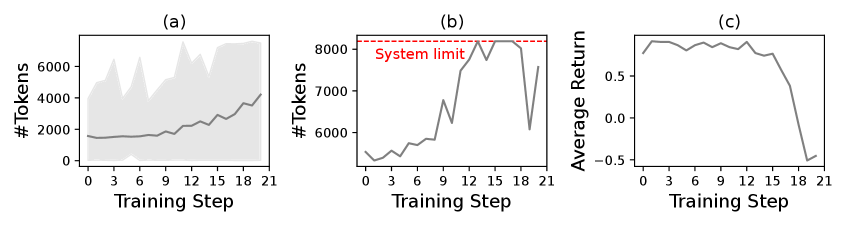
- Agentic RL在LLM训练中面临上下文长度增长带来的内存和延迟挑战,以及中间数据跨设备移动的瓶颈。
- EARL通过动态调整模型和训练并行性,以及布局感知的分布式数据交换,来解决这些问题。
- EARL提高了吞吐量,减少了长上下文失败,实现了大规模agentic LLM的稳定训练,无需限制上下文长度。
📝 摘要(中文)
强化学习(RL)已成为大型语言模型(LLM)后训练的关键组成部分,而agentic RL将这种范式扩展为通过多轮交互和工具使用作为智能体运行。扩展此类系统会暴露两个实际瓶颈:(1)训练期间上下文长度迅速增长,导致内存使用量和延迟增加,并触发内存不足(OOM)错误;(2)中间张量随上下文长度累积,使得跨设备数据移动成为主要的系统瓶颈。我们提出了EARL,一个用于高效agentic RL的可扩展系统。EARL设计了一个并行选择器,可以根据序列长度和系统负载在RL阶段动态调整模型和训练并行性,以及一个数据调度器,可以执行布局感知的、分散的中间数据批次交换。这些组件共同提高了吞吐量,减少了长上下文失败,并能够在不依赖于上下文长度的硬性限制或惩罚的情况下,稳定地大规模训练agentic LLM。
🔬 方法详解
问题定义:论文旨在解决大型语言模型在agentic强化学习训练过程中,由于上下文长度快速增长导致的内存占用过高、训练延迟增加以及跨设备数据传输瓶颈问题。现有方法通常采用限制上下文长度或施加惩罚的方式来缓解这些问题,但这些方法会影响模型的性能和泛化能力。
核心思路:EARL的核心思路是通过动态调整模型和训练的并行策略,以及优化数据在不同设备间的传输方式,来高效地利用计算资源,从而在不限制上下文长度的前提下,提升训练效率和稳定性。这种方法旨在根据序列长度和系统负载自适应地调整并行策略,并采用布局感知的分布式数据交换来减少数据传输开销。
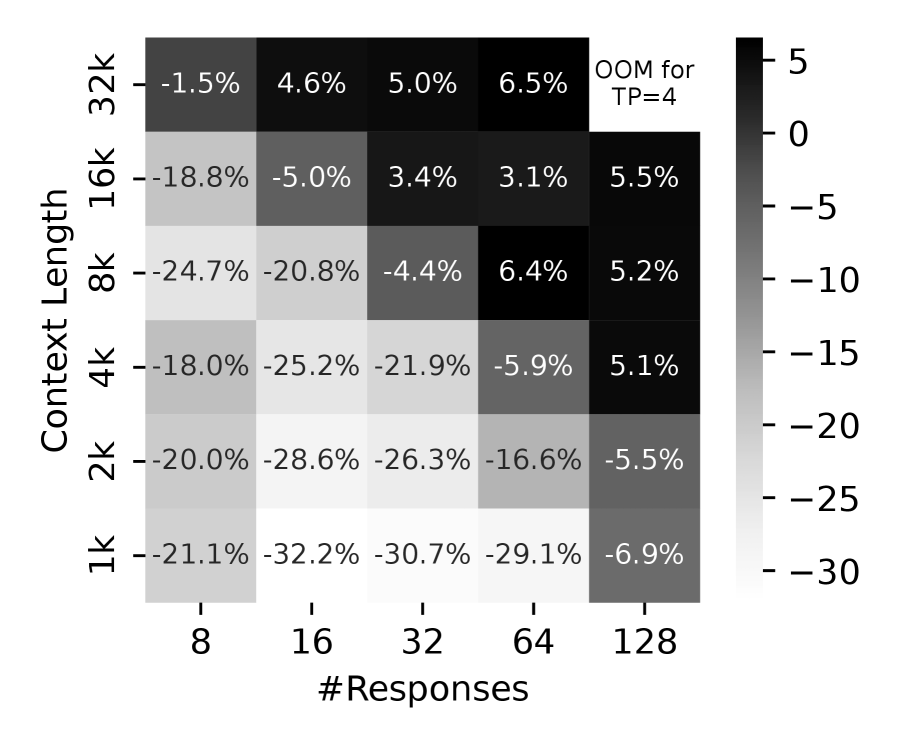
技术框架:EARL系统主要包含两个核心组件:并行选择器(Parallelism Selector)和数据调度器(Data Dispatcher)。并行选择器负责根据序列长度和系统负载,动态地选择合适的模型并行和训练并行策略。数据调度器则负责执行布局感知的、分散的中间数据批次交换,以减少跨设备数据传输的开销。整体流程包括:1. 初始化模型和训练环境;2. 根据当前序列长度和系统负载,并行选择器动态调整并行策略;3. 执行强化学习训练,生成中间数据;4. 数据调度器执行布局感知的分布式数据交换;5. 更新模型参数;6. 重复步骤2-5,直至训练完成。
关键创新:EARL的关键创新在于其动态并行选择器和布局感知的数据调度器。动态并行选择器能够根据序列长度和系统负载自适应地调整并行策略,避免了静态并行策略的局限性。布局感知的数据调度器则能够根据数据的布局信息,优化数据在不同设备间的传输路径,减少数据传输的开销。与现有方法相比,EARL能够在不限制上下文长度的前提下,提升训练效率和稳定性。
关键设计:并行选择器可能采用基于规则或基于学习的方法来选择合适的并行策略。基于规则的方法可能根据序列长度和系统负载设定阈值,并根据阈值选择不同的并行策略。基于学习的方法则可能使用强化学习或其他机器学习算法来学习最优的并行策略。数据调度器则需要考虑数据的布局信息,例如数据在不同设备上的分布情况,以及设备间的网络拓扑结构,来优化数据传输路径。具体的损失函数和网络结构取决于具体的强化学习算法和模型架构。
🖼️ 关键图片

📊 实验亮点
论文提出的EARL系统能够显著提高agentic LLM的训练效率和稳定性。通过动态调整并行策略和优化数据传输,EARL减少了长上下文失败,并能够在不限制上下文长度的情况下,稳定地训练大规模模型。具体的性能数据和对比基线将在论文的实验部分给出,预计EARL在吞吐量和训练时间上会有显著提升。
🎯 应用场景
EARL可应用于各种需要大规模agentic强化学习的场景,例如智能对话系统、游戏AI、机器人控制等。通过提高训练效率和稳定性,EARL能够帮助开发者训练出更强大的智能体,从而提升用户体验和解决实际问题。未来,EARL有望推动agentic RL在更多领域的应用,例如自动驾驶、金融交易等。
📄 摘要(原文)
Reinforcement learning (RL) has become a pivotal component of large language model (LLM) post-training, and agentic RL extends this paradigm to operate as agents through multi-turn interaction and tool use. Scaling such systems exposes two practical bottlenecks: (1) context length grows rapidly during training, inflating memory usage and latency, and triggering out-of-memory (OOM) failures; and (2) intermediate tensors accumulate with context length, making cross-device data movement a major system bottleneck. We present EARL, a scalable system for efficient agentic RL. EARL designs a parallelism selector that dynamically adapts model and training parallelism across RL stages based on sequence length and system load, and a data dispatcher that performs layout-aware, decentralized exchange of intermediate data batches. Together, these components increase throughput, reduce long-context failures, and enable stable large-scale training of agentic LLMs without relying on hard limits or penalties of context length.