LLM-FS-Agent: A Deliberative Role-based Large Language Model Architecture for Transparent Feature Selection
作者: Mohamed Bal-Ghaoui, Fayssal Sabri
分类: cs.LG, cs.AI
发布日期: 2025-10-07
💡 一句话要点
提出LLM-FS-Agent,一种基于角色扮演的大语言模型架构,用于透明特征选择。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 特征选择 多智能体系统 可解释性 网络安全
📋 核心要点
- 高维数据降低模型可解释性和计算效率,现有基于LLM的特征选择方法缺乏结构化推理和透明的决策依据。
- LLM-FS-Agent通过构建多智能体辩论机制,每个智能体扮演特定角色,集体评估特征相关性并生成详细理由。
- 实验表明,LLM-FS-Agent在保持或提升分类性能的同时,显著降低了下游训练时间,平均减少46%。
📝 摘要(中文)
高维数据是机器学习中普遍存在的挑战,它常常会损害模型的可解释性和计算效率。虽然大型语言模型(LLM)在通过特征选择进行降维方面显示出潜力,但现有的基于LLM的方法通常缺乏结构化的推理和对其决策的透明论证。本文介绍了一种新颖的多智能体架构LLM-FS-Agent,专为可解释和稳健的特征选择而设计。该系统组织多个LLM智能体之间进行审议性的“辩论”,每个智能体都被分配了特定的角色,从而能够集体评估特征相关性并生成详细的理由。我们在网络安全领域使用CIC-DIAD 2024 IoT入侵检测数据集评估LLM-FS-Agent,并将其性能与包括LLM-Select和PCA等传统方法在内的强大基线进行比较。实验结果表明,LLM-FS-Agent始终如一地实现优越或可比的分类性能,同时将下游训练时间平均减少46%(具有统计学意义的改进,XGBoost的p = 0.028)。这些发现表明,所提出的审议架构增强了决策透明度和计算效率,使LLM-FS-Agent成为实际应用中实用且可靠的解决方案。
🔬 方法详解
问题定义:论文旨在解决高维数据下,传统特征选择方法和现有基于LLM的特征选择方法缺乏可解释性和透明性的问题。现有方法要么依赖于黑盒模型,要么缺乏对特征选择决策的明确解释,难以满足实际应用中对模型可信度的要求。
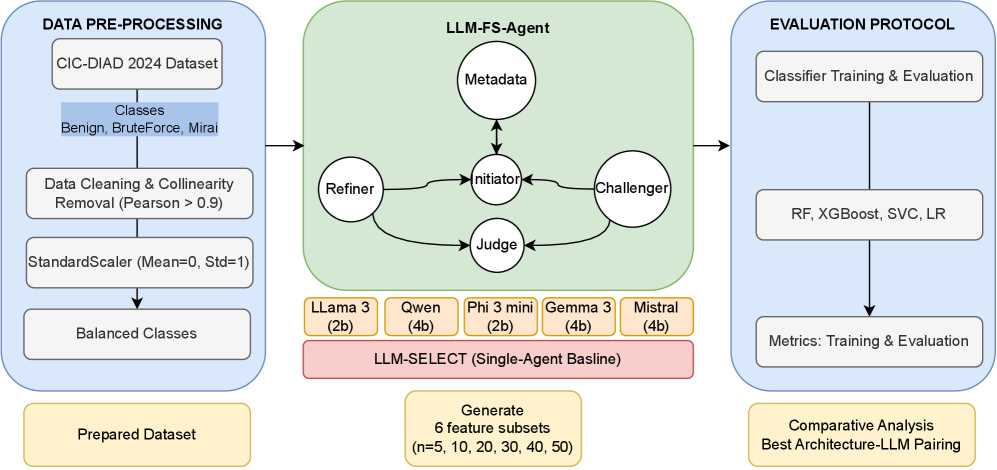
核心思路:论文的核心思路是利用多智能体系统模拟专家辩论过程,每个智能体扮演不同的角色(例如,支持者、反对者、总结者),通过角色扮演和相互辩论,对特征的重要性进行全面评估,并生成可解释的决策依据。这种方法旨在提高特征选择过程的透明度和可信度。
技术框架:LLM-FS-Agent的整体架构包含以下几个主要模块:1) 角色定义模块:定义每个LLM智能体的角色和职责。2) 特征评估模块:每个智能体根据自身角色,对特征进行评估并提出论据。3) 辩论协调模块:协调智能体之间的辩论过程,确保辩论的有效性和公平性。4) 决策生成模块:根据辩论结果,生成最终的特征选择决策和相应的解释。
关键创新:该方法最重要的创新点在于引入了多智能体辩论机制,将特征选择过程转化为一个透明、可解释的集体决策过程。与现有方法相比,LLM-FS-Agent不仅能够选择出有效的特征子集,还能够提供详细的决策依据,增强了模型的可信度和可解释性。
关键设计:关键设计包括:1) 智能体角色的选择,例如支持者、反对者、总结者等,不同的角色可以从不同的角度评估特征的重要性。2) 辩论规则的设计,例如辩论的轮次、发言时间限制等,确保辩论的有效性和公平性。3) 决策生成策略,例如根据智能体的投票结果或论据的强度,确定最终的特征选择结果。
🖼️ 关键图片


📊 实验亮点
实验结果表明,LLM-FS-Agent在CIC-DIAD 2024 IoT入侵检测数据集上取得了优异的性能,与LLM-Select和PCA等基线方法相比,在分类性能上达到或超过了基线水平。更重要的是,LLM-FS-Agent能够显著降低下游训练时间,平均减少46%(XGBoost的p = 0.028),这表明该方法在提高计算效率方面具有显著优势。
🎯 应用场景
LLM-FS-Agent可应用于网络安全、金融风控、医疗诊断等多个领域。在这些领域中,高维数据普遍存在,且模型的可解释性至关重要。该方法能够帮助领域专家更好地理解模型的决策过程,提高模型的可靠性和可信度,从而促进人工智能技术在这些领域的应用。
📄 摘要(原文)
High-dimensional data remains a pervasive challenge in machine learning, often undermining model interpretability and computational efficiency. While Large Language Models (LLMs) have shown promise for dimensionality reduction through feature selection, existing LLM-based approaches frequently lack structured reasoning and transparent justification for their decisions. This paper introduces LLM-FS-Agent, a novel multi-agent architecture designed for interpretable and robust feature selection. The system orchestrates a deliberative "debate" among multiple LLM agents, each assigned a specific role, enabling collective evaluation of feature relevance and generation of detailed justifications. We evaluate LLM-FS-Agent in the cybersecurity domain using the CIC-DIAD 2024 IoT intrusion detection dataset and compare its performance against strong baselines, including LLM-Select and traditional methods such as PCA. Experimental results demonstrate that LLM-FS-Agent consistently achieves superior or comparable classification performance while reducing downstream training time by an average of 46% (statistically significant improvement, p = 0.028 for XGBoost). These findings highlight that the proposed deliberative architecture enhances both decision transparency and computational efficiency, establishing LLM-FS-Agent as a practical and reliable solution for real-world applications.