From Principles to Practice: A Systematic Study of LLM Serving on Multi-core NPUs
作者: Tianhao Zhu, Dahu Feng, Erhu Feng, Yubin Xia
分类: cs.AR, cs.LG
发布日期: 2025-10-07
💡 一句话要点
针对多核NPU,提出LLM Serving的系统性优化方案,提升推理性能。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: LLM Serving 多核NPU 张量并行 核心放置 内存管理 性能优化 AI加速器
📋 核心要点
- 现有NPU多核架构在LLM推理中,由于缺乏灵活性和优化配置,导致计算资源利用率低,推理性能受限。
- 论文提出多级仿真框架,系统分析张量并行、核心放置、内存管理等策略,寻找多核NPU的最佳LLM serving方案。
- 实验表明,该方案在不同硬件配置下,相比SOTA设计,实现了1.32x-6.03x的加速,显著提升了LLM推理性能。
📝 摘要(中文)
随着大型语言模型(LLM)的广泛应用,对高性能LLM推理服务的需求持续增长。为了满足这一需求,越来越多的AI加速器被提出,例如Google TPU、华为NPU、Graphcore IPU和Cerebras WSE等。这些加速器大多采用多核架构以实现增强的可扩展性,但缺乏SIMT架构的灵活性。因此,如果没有对硬件架构进行仔细配置,以及对张量并行和核心放置策略进行周密设计,计算资源可能会未被充分利用,从而导致次优的推理性能。为了解决这些挑战,我们首先提出了一个多级仿真框架,该框架同时包含事务级和基于性能模型的仿真,用于多核NPU。利用该仿真器,我们进行了一项系统分析,并进一步提出了针对多核NPU的张量并行策略、核心放置策略、内存管理方法以及PD-disaggregation和PD-fusion之间选择的最佳解决方案。我们对具有代表性的LLM和各种NPU配置进行了全面的实验。评估结果表明,与多核NPU的SOTA设计相比,我们的解决方案可以在不同的硬件配置上实现1.32倍-6.03倍的加速。至于LLM serving,我们的工作为跨各种LLM工作负载设计多核NPU的最佳硬件架构和服务策略提供了指导。
🔬 方法详解
问题定义:论文旨在解决多核NPU上LLM推理服务性能优化的问题。现有方法在多核NPU上进行LLM推理时,由于硬件架构的特殊性(缺乏SIMT架构的灵活性)以及对张量并行策略、核心放置策略、内存管理方法等配置考虑不周,导致计算资源利用率不高,推理性能无法达到最优。因此,如何充分利用多核NPU的计算能力,提升LLM推理速度是本文要解决的核心问题。
核心思路:论文的核心思路是通过系统性的分析和优化,找到最适合多核NPU的LLM serving策略。具体而言,首先构建一个多级仿真框架,用于模拟不同配置下的多核NPU性能。然后,利用该仿真框架,对张量并行策略、核心放置策略、内存管理方法以及PD-disaggregation和PD-fusion的选择进行全面的分析和优化,从而找到最佳的硬件架构和服务策略。
技术框架:论文的技术框架主要包含两个部分:多级仿真框架和优化策略。多级仿真框架同时包含事务级和基于性能模型的仿真,用于模拟多核NPU的性能。优化策略则包括张量并行策略、核心放置策略、内存管理方法以及PD-disaggregation和PD-fusion的选择。通过仿真框架,可以评估不同策略的性能,从而找到最佳的组合。
关键创新:论文的关键创新在于提出了一个多级仿真框架,可以对多核NPU的LLM推理性能进行精确的模拟。该仿真框架可以帮助研究人员和工程师快速评估不同硬件配置和软件策略的性能,从而加速LLM serving的优化过程。此外,论文还系统地分析了张量并行策略、核心放置策略、内存管理方法等因素对LLM推理性能的影响,并提出了相应的优化方案。
关键设计:论文的关键设计包括多级仿真框架的构建方法、张量并行策略的选择、核心放置策略的设计、内存管理方法的优化以及PD-disaggregation和PD-fusion的选择。具体的参数设置、损失函数、网络结构等技术细节取决于具体的LLM模型和NPU硬件配置,论文主要关注的是通用性的优化策略。
🖼️ 关键图片
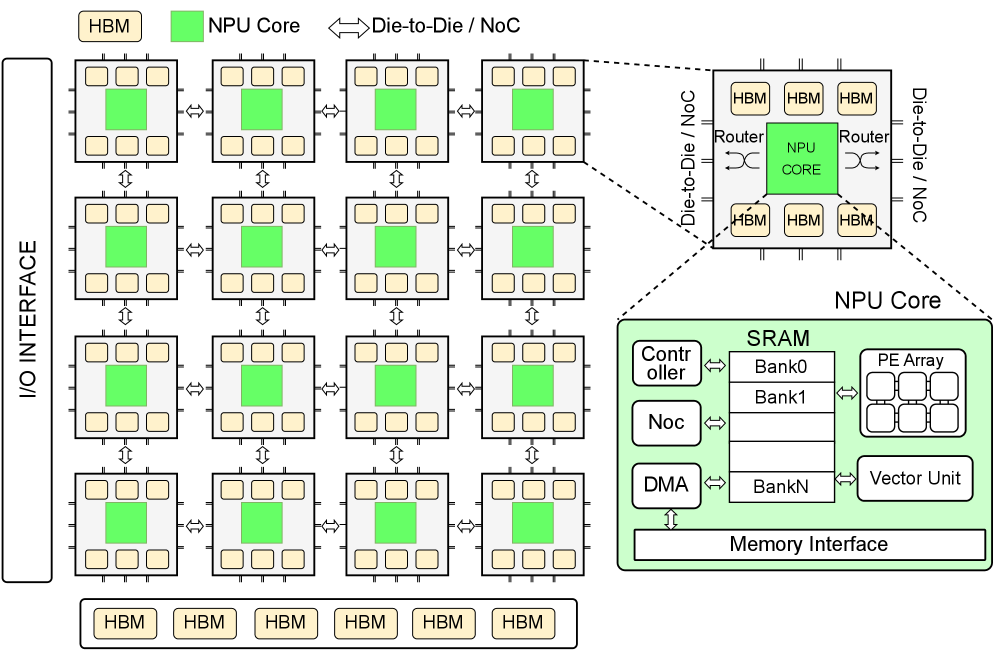
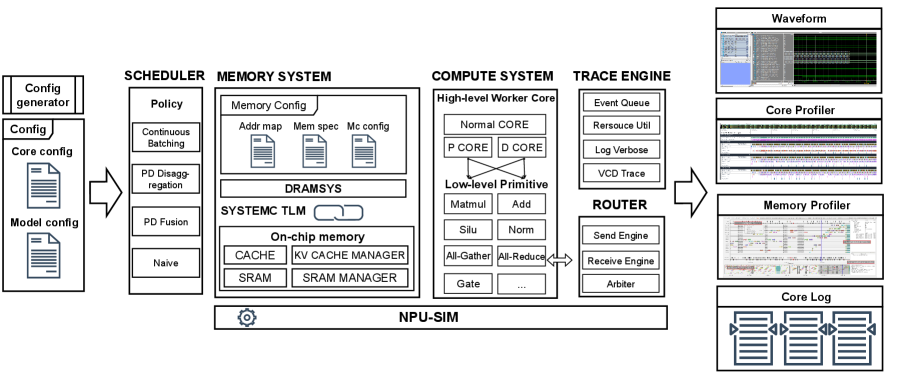
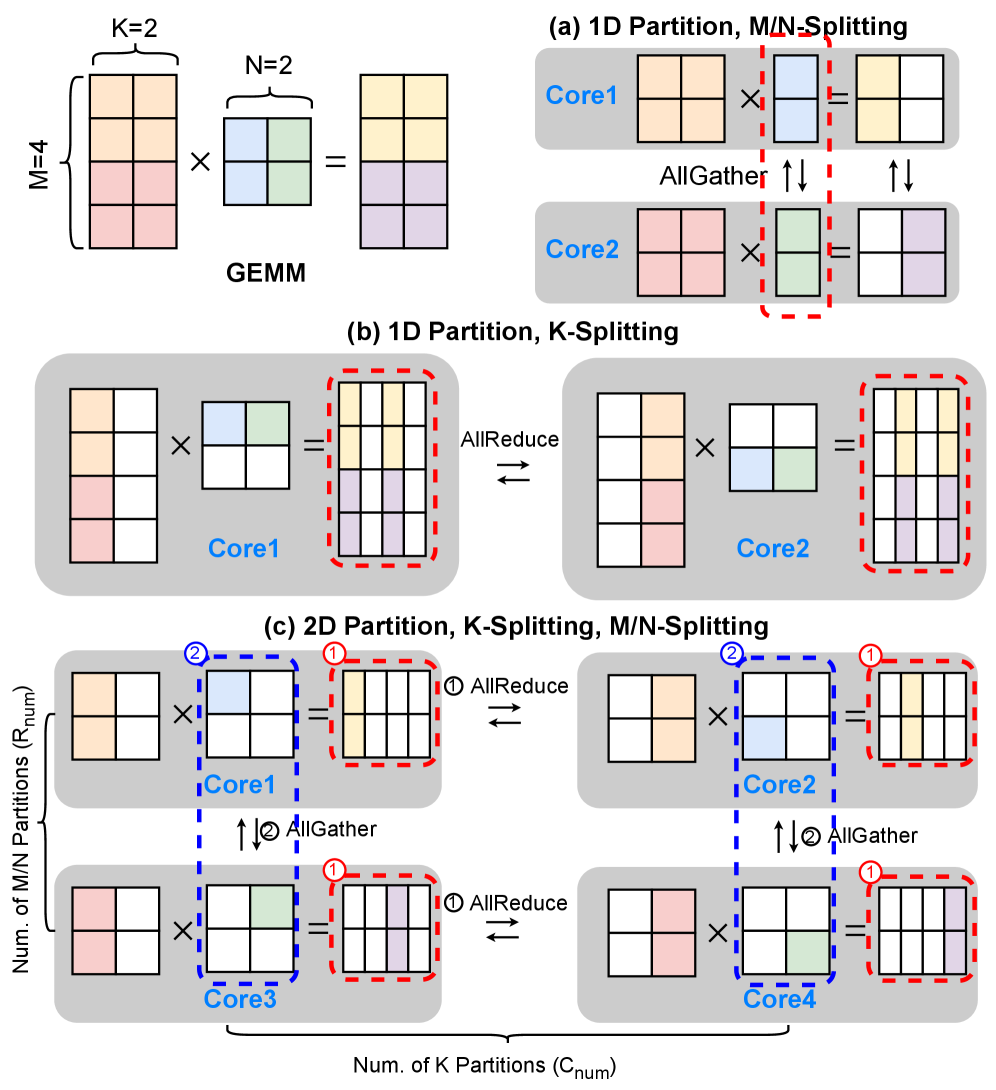
📊 实验亮点
实验结果表明,论文提出的解决方案在不同的硬件配置下,相比SOTA设计,实现了1.32倍-6.03倍的加速。这意味着在相同的硬件条件下,可以显著提升LLM推理速度,降低延迟,提高吞吐量。这一结果验证了论文提出的优化策略的有效性,并为多核NPU上的LLM serving提供了重要的指导。
🎯 应用场景
该研究成果可广泛应用于各种需要高性能LLM推理服务的场景,例如智能客服、机器翻译、文本生成等。通过优化多核NPU上的LLM serving,可以显著降低推理延迟,提高用户体验,并降低部署成本。未来,该研究可以进一步扩展到其他类型的AI加速器和LLM模型,为更广泛的AI应用提供支持。
📄 摘要(原文)
With the widespread adoption of Large Language Models (LLMs), the demand for high-performance LLM inference services continues to grow. To meet this demand, a growing number of AI accelerators have been proposed, such as Google TPU, Huawei NPU, Graphcore IPU, and Cerebras WSE, etc. Most of these accelerators adopt multi-core architectures to achieve enhanced scalability, but lack the flexibility of SIMT architectures. Therefore, without careful configuration of the hardware architecture, as well as deliberate design of tensor parallelism and core placement strategies, computational resources may be underutilized, resulting in suboptimal inference performance. To address these challenges, we first present a multi-level simulation framework with both transaction-level and performance-model-based simulation for multi-core NPUs. Using this simulator, we conduct a systematic analysis and further propose the optimal solutions for tensor parallelism strategies, core placement policies, memory management methods, as well as the selection between PD-disaggregation and PD-fusion on multi-core NPUs. We conduct comprehensive experiments on representative LLMs and various NPU configurations. The evaluation results demonstrate that, our solution can achieve 1.32x-6.03x speedup compared to SOTA designs for multi-core NPUs across different hardware configurations. As for LLM serving, our work offers guidance on designing optimal hardware architectures and serving strategies for multi-core NPUs across various LLM workloads.