Permutation-Invariant Representation Learning for Robust and Privacy-Preserving Feature Selection
作者: Rui Liu, Tao Zhe, Yanjie Fu, Feng Xia, Ted Senator, Dongjie Wang
分类: cs.LG, cs.AI
发布日期: 2025-10-07 (更新: 2025-12-08)
备注: We note that this work has been reproduced without authorization by Stchingtana Naryso and Zihang Yang under the title "Robust and Privacy-Preserving Feature Selection: A Permutation-Invariant Representation Learning Approach with Federated Extension." Their version remains the same technical content, with only the title and abstract changed. This version is the authoritative and original source
💡 一句话要点
提出一种联邦学习框架FedCAPS,用于稳健且保护隐私的特征选择。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 联邦学习 特征选择 隐私保护 知识融合 数据异构
📋 核心要点
- 现有特征选择方法难以捕捉复杂特征交互,且在联邦学习等分布式场景中面临数据异构和隐私保护的挑战。
- 提出FedCAPS框架,结合排列不变嵌入和策略引导搜索,并通过知识融合和样本感知加权来解决数据异构和隐私问题。
- 实验表明,FedCAPS在特征选择任务中表现出有效性、鲁棒性和效率,并在联邦学习场景中具有强大的泛化能力。
📝 摘要(中文)
本文提出了一种用于稳健且保护隐私的特征选择的框架。现有特征选择方法难以捕捉复杂的特征交互,且难以适应不同的应用场景。虽然基于生成智能的方法有所改进,但仍受嵌入的排列敏感性和基于梯度的搜索中凸性假设的限制。为了解决这些问题,本文扩展了之前的工作,从两个角度改进框架:1) 开发了一种保护隐私的知识融合策略,以在不共享敏感原始数据的情况下推导统一的表示空间;2) 结合了一种感知样本的加权策略,以解决异构本地客户端之间的分布不平衡问题。大量实验验证了该框架的有效性、鲁棒性和效率。结果进一步证明了其在联邦学习场景中的强大泛化能力。代码和数据已公开。
🔬 方法详解
问题定义:论文旨在解决联邦学习场景下,由于数据分布不平衡、异构以及隐私限制,传统的特征选择方法无法有效利用全局信息进行特征选择的问题。现有方法通常需要共享原始数据,这违反了隐私保护原则,并且难以处理客户端之间的数据异构性。
核心思路:论文的核心思路是在不直接共享原始数据的前提下,通过一种保护隐私的知识融合策略,将各个客户端的特征选择知识整合到一个统一的表示空间中。同时,采用样本感知的加权策略,解决客户端之间数据分布不平衡的问题,从而提升特征选择的性能和泛化能力。
技术框架:FedCAPS框架主要包含以下几个模块:1) 本地特征选择模块:每个客户端独立进行特征选择,生成本地的特征重要性评估。2) 隐私保护知识融合模块:该模块负责将各个客户端的特征重要性评估进行融合,生成一个全局的特征表示,同时保证不泄露客户端的原始数据。3) 样本感知加权模块:该模块根据客户端的数据量和数据质量,对各个客户端的特征重要性评估进行加权,以解决数据分布不平衡的问题。4) 全局特征选择模块:基于融合后的全局特征表示,进行最终的特征选择。
关键创新:论文的关键创新在于提出了一种保护隐私的知识融合策略和样本感知的加权策略。知识融合策略能够在不共享原始数据的情况下,将各个客户端的特征选择知识整合到一个统一的表示空间中。样本感知的加权策略能够根据客户端的数据量和数据质量,对各个客户端的特征重要性评估进行加权,从而解决数据分布不平衡的问题。
关键设计:在知识融合模块中,可能采用了差分隐私、同态加密或安全多方计算等技术来保护客户端的隐私。样本感知加权模块可能使用客户端的数据量、数据质量或模型性能等指标来计算权重。具体的损失函数设计可能包括特征选择的准确率、模型在下游任务上的性能以及隐私保护的约束。
🖼️ 关键图片


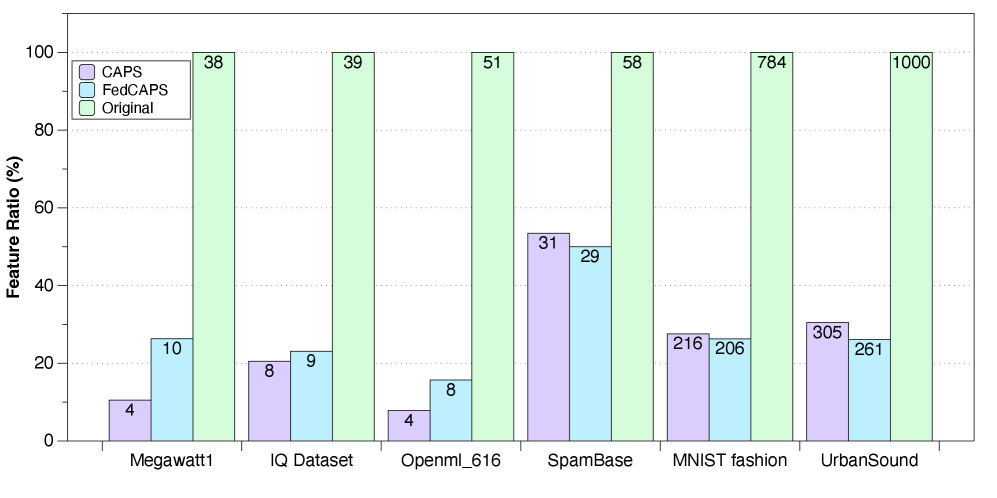
📊 实验亮点
实验结果表明,FedCAPS框架在多个数据集上均取得了优于现有方法的性能。特别是在联邦学习场景下,FedCAPS能够显著提升特征选择的准确率和泛化能力,同时有效地保护用户隐私。具体的性能提升幅度取决于数据集和任务的设置,但总体而言,FedCAPS展现了其在稳健性和隐私保护方面的优势。
🎯 应用场景
该研究成果可应用于金融风控、医疗诊断、智能推荐等领域。在这些场景中,数据通常分布在不同的机构或设备上,且数据具有异构性和隐私敏感性。FedCAPS框架能够在保护用户隐私的前提下,有效地进行特征选择,提升模型性能,具有重要的实际应用价值和广阔的应用前景。
📄 摘要(原文)
Feature selection eliminates redundancy among features to improve downstream task performance while reducing computational overhead. Existing methods often struggle to capture intricate feature interactions and adapt across diverse application scenarios. Recent advances employ generative intelligence to alleviate these drawbacks. However, these methods remain constrained by permutation sensitivity in embedding and reliance on convexity assumptions in gradient-based search. To address these limitations, our initial work introduces a novel framework that integrates permutation-invariant embedding with policy-guided search. Although effective, it still left opportunities to adapt to realistic distributed scenarios. In practice, data across local clients is highly imbalanced, heterogeneous and constrained by strict privacy regulations, limiting direct sharing. These challenges highlight the need for a framework that can integrate feature selection knowledge across clients without exposing sensitive information. In this extended journal version, we advance the framework from two perspectives: 1) developing a privacy-preserving knowledge fusion strategy to derive a unified representation space without sharing sensitive raw data. 2) incorporating a sample-aware weighting strategy to address distributional imbalance among heterogeneous local clients. Extensive experiments validate the effectiveness, robustness, and efficiency of our framework. The results further demonstrate its strong generalization ability in federated learning scenarios. The code and data are publicly available: https://anonymous.4open.science/r/FedCAPS-08BF.