ARMOR: High-Performance Semi-Structured Pruning via Adaptive Matrix Factorization
作者: Lawrence Liu, Alexander Liu, Mengdi Wang, Tuo Zhao, Lin F. Yang
分类: cs.LG
发布日期: 2025-10-07
💡 一句话要点
ARMOR:通过自适应矩阵分解实现高性能半结构化剪枝
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 模型剪枝 半结构化剪枝 矩阵分解 硬件加速
📋 核心要点
- 现有LLM剪枝方法,特别是2:4稀疏剪枝,虽能加速推理,但常导致显著的性能下降。
- ARMOR通过将权重矩阵分解为稀疏核心和块对角wrapper,实现更灵活的误差校正,提升模型质量。
- 实验表明,ARMOR在Llama和Qwen模型上显著优于现有2:4剪枝方法,同时保持推理加速和内存减少。
📝 摘要(中文)
大型语言模型(LLMs)因其巨大的计算和内存需求而面临严峻的部署挑战。半结构化剪枝,特别是2:4稀疏性,为实际的硬件加速提供了一条途径,但现有方法通常会导致显著的性能下降。为了弥合这一差距,我们引入了ARMOR(Adaptive Representation with Matrix-factORization),一种新颖的单次后训练剪枝算法。ARMOR不是直接剪枝权重,而是将每个权重矩阵分解为一个2:4稀疏核心,并用两个低开销的块对角矩阵包裹。与传统的2:4剪枝技术相比,这些wrapper充当高效的预处理和后处理误差校正器,提供更大的灵活性来保持模型质量。稀疏核心和块对角wrapper通过块坐标下降算法选择,该算法最小化层级的代理损失。我们从理论上证明,这种优化保证收敛到代理损失小于或等于最先进剪枝算法的解。在Llama和Qwen模型系列上的实验表明,ARMOR在各种下游任务和困惑度评估中始终且显著优于最先进的2:4剪枝方法。ARMOR在保持2:4剪枝的推理加速和显著内存使用减少的同时,实现了卓越的性能,从而在模型压缩和任务准确性之间建立了更有效的权衡。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLMs)部署时面临的计算和内存资源瓶颈问题。现有的半结构化剪枝方法,特别是2:4稀疏剪枝,虽然可以降低计算和内存需求,但往往会带来显著的性能损失,限制了其在实际应用中的价值。
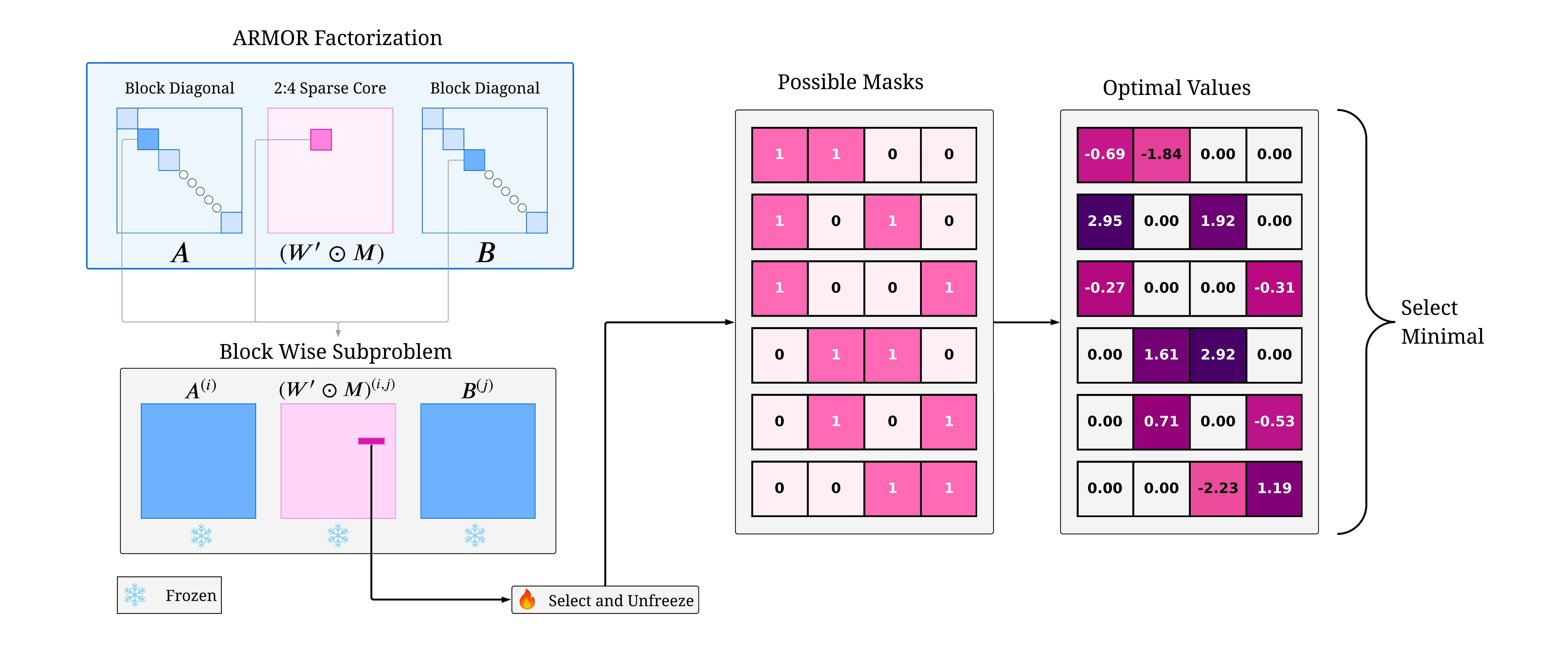
核心思路:ARMOR的核心思路是将权重矩阵分解为一个2:4稀疏的核心矩阵,并用两个低开销的块对角矩阵(wrapper)包裹。这些wrapper充当误差校正器,在剪枝前后对权重进行调整,从而在保持稀疏性的同时,尽可能地减少剪枝带来的性能损失。这种分解方式允许更大的灵活性,能够更好地保留模型的重要信息。
技术框架:ARMOR算法主要包含以下几个阶段:1) 权重矩阵分解:将原始权重矩阵分解为稀疏核心矩阵和两个块对角wrapper矩阵。2) 块坐标下降优化:使用块坐标下降算法,迭代优化稀疏核心矩阵和wrapper矩阵,以最小化层级的代理损失。3) 模型评估:在下游任务上评估剪枝后的模型性能。
关键创新:ARMOR的关键创新在于其自适应的矩阵分解方式。与直接对权重进行剪枝的方法不同,ARMOR通过引入wrapper矩阵,实现了更精细的权重调整,从而更好地保留了模型的信息。此外,块坐标下降优化算法保证了算法的收敛性,并能找到一个较好的局部最优解。
关键设计:ARMOR的关键设计包括:1) 2:4稀疏核心矩阵:选择2:4稀疏模式是为了兼顾硬件加速效率和模型性能。2) 块对角wrapper矩阵:块对角结构保证了wrapper矩阵的低开销,避免引入过多的计算负担。3) 层级代理损失:使用层级代理损失可以更好地控制每一层的剪枝程度,避免出现过剪枝或欠剪枝的情况。4) 块坐标下降算法:保证算法收敛到局部最优解。
🖼️ 关键图片


📊 实验亮点
ARMOR在Llama和Qwen模型上进行了实验,结果表明其性能显著优于现有的2:4剪枝方法。在各种下游任务和困惑度评估中,ARMOR都取得了更好的结果,同时保持了2:4剪枝的推理加速和内存减少的优势。例如,在某些任务上,ARMOR相比于其他2:4剪枝方法,性能提升超过了5%。
🎯 应用场景
ARMOR算法可广泛应用于大型语言模型的压缩和加速,特别是在资源受限的边缘设备或移动设备上部署LLM。通过降低模型的计算和内存需求,ARMOR可以使LLM在更多场景下得到应用,例如智能助手、自然语言处理、机器翻译等。此外,该方法也可以应用于其他类型的深度学习模型,具有广泛的应用前景。
📄 摘要(原文)
Large language models (LLMs) present significant deployment challenges due to their immense computational and memory requirements. While semi-structured pruning, particularly 2:4 sparsity, offers a path to practical hardware acceleration, existing methods often incur substantial performance degradation. To bridge this gap, we introduce ARMOR: (Adaptive Representation with Matrix-factORization), a novel one-shot post-training pruning algorithm. Instead of directly pruning weights, ARMOR factorizes each weight matrix into a 2:4 sparse core wrapped by two low-overhead, block diagonal matrices. These wrappers act as efficient pre and post-transformation error correctors, offering greater flexibility to preserve model quality compared to conventional 2:4 pruning techniques. The sparse core and block diagonal wrappers are chosen through a block coordinate descent algorithm that minimizes a layer-wise proxy loss. We theoretically prove this optimization is guaranteed to converge to a solution with a proxy loss less than or equal to state-of-the-art pruning algorithms. Experiments on Llama (Touvron et al., 2023; Dubey et al., 2024) and Qwen (Yang et al., 2025) model families demonstrate that ARMOR consistently and significantly outperforms state-of-the-art 2:4 pruning methods across a wide range of downstream tasks and perplexity evaluations. ARMOR achieves this superior performance while retaining the inference speedups and substantial memory usage reductions of 2:4 pruning, establishing a more effective trade-off between model compression and task accuracy