Draft, Verify, and Improve: Toward Training-Aware Speculative Decoding
作者: Shrenik Bhansali, Larry Heck
分类: cs.LG
发布日期: 2025-10-06
💡 一句话要点
提出DVI框架以解决自回归解码的延迟瓶颈问题
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 自回归解码 推测解码 在线学习 语言模型 速度提升 蒸馏训练 深度学习
📋 核心要点
- 现有的推测解码系统通常需要大量的离线训练或额外组件,导致数据和计算成本高,且在分布漂移下表现脆弱。
- DVI框架通过将大型语言模型分为推测者和验证者,利用验证者的接受/拒绝决策作为监督信号,进行持续的在线学习。
- 在Spec-Bench上,DVI实现了2.16倍的墙面时间加速,性能与最先进的方法EAGLE-2相当,但所需训练数据量却少得多。
📝 摘要(中文)
自回归解码是大型语言模型的主要延迟瓶颈。论文提出的自我推测框架DVI通过将推测者和验证者相结合,利用在线学习来提升解码效率。DVI在Spec-Bench上实现了2.16倍的速度提升,且所需训练数据显著减少,展示了训练感知的自我推测能够在保持无损的前提下实现先进的速度提升。
🔬 方法详解
问题定义:论文要解决的问题是自回归解码在大型语言模型中的延迟瓶颈,现有方法往往依赖于大量的离线训练和额外组件,导致高昂的计算和数据成本。
核心思路:DVI框架的核心思路是将推测者和验证者结合,通过在线学习来提升推测者的性能,利用验证者的反馈作为监督信号来不断优化推测者。
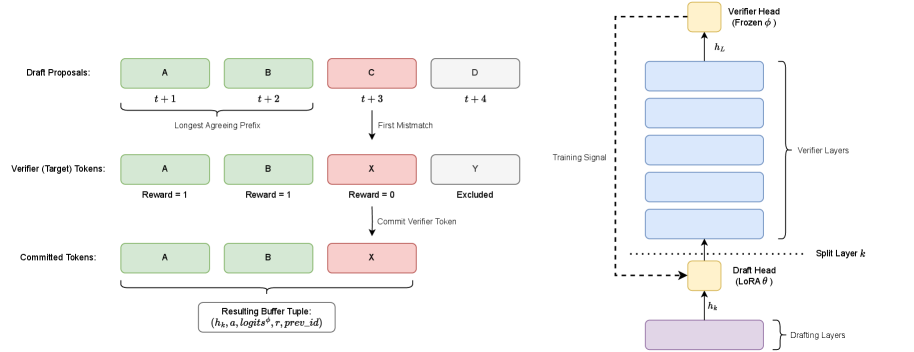
技术框架:DVI的整体架构包括推测者和验证者两个模块。在生成过程中,验证者的接受/拒绝决策被转化为监督信号,用于更新推测者的头部。
关键创新:DVI的主要创新在于其训练感知的自我推测能力,通过在线蒸馏和奖励掩蔽交叉熵的结合,实现了无损的单模型部署。
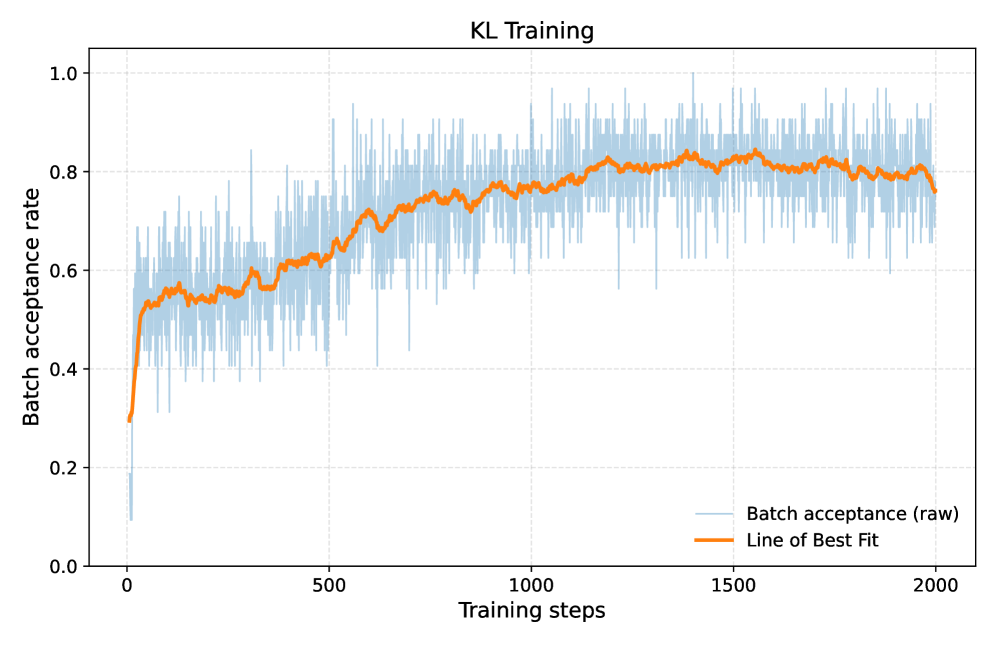
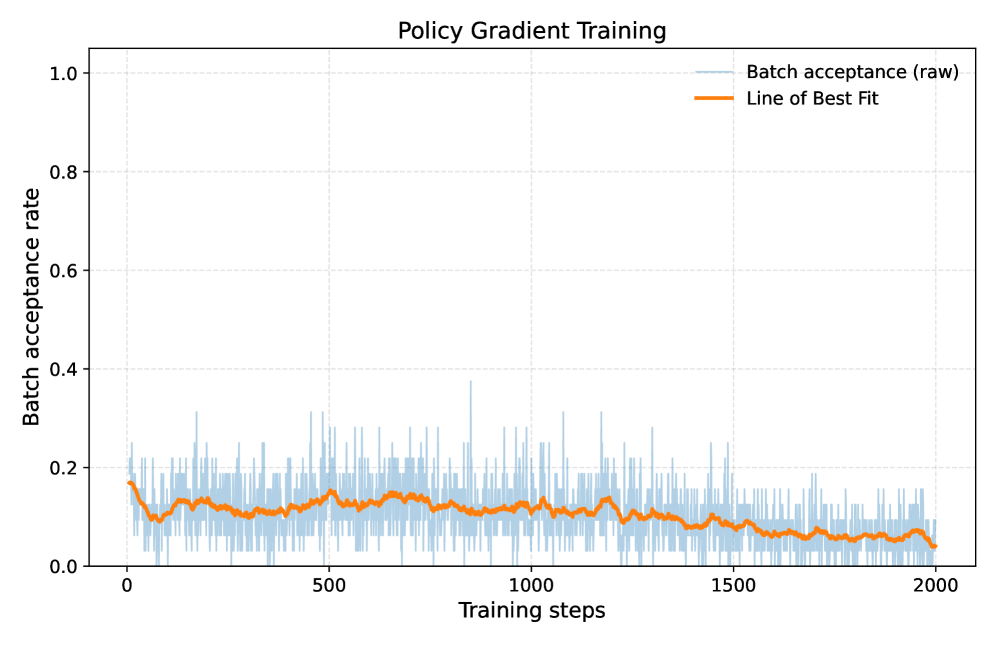
关键设计:DVI采用了简单的KL到RL调度来启动在线蒸馏,并引入了基于策略梯度的奖励掩蔽交叉熵损失函数,确保了模型在训练过程中的稳定性和有效性。
🖼️ 关键图片
📊 实验亮点
DVI在Spec-Bench上实现了2.16倍的墙面时间加速,性能与最先进的EAGLE-2方法相当,但所需训练数据量却少得多,且实验结果表明DVI在KL-only在线蒸馏的对比中表现更佳。
🎯 应用场景
该研究的潜在应用领域包括自然语言处理、对话系统和实时文本生成等。通过提升解码速度,DVI能够显著改善用户体验,降低计算资源消耗,具有广泛的实际价值和未来影响。
📄 摘要(原文)
Autoregressive (AR) decoding is a major latency bottleneck for large language models. Speculative decoding (SD) accelerates AR by letting a drafter propose multi-token blocks that a verifier accepts or rejects. However, many SD systems require heavy offline training or extra components. These choices raise data/compute cost and can yield brittle drafters under distribution drift. We introduce \emph{Draft, Verify, \& Improve (DVI)}, a training-aware self-speculative framework that combines inference with continual online learning. We partition an LLM into a drafter and a verifier, and during generation, verifier accept/reject decisions are converted into supervision signals and used to update the drafter head. A simple \emph{KL$\rightarrow$RL} schedule bootstraps calibration via online distillation and then adds reward-masked cross-entropy with a on-policy policy-gradient term, preserving lossless, single model deployment. On Spec-Bench, DVI achieves a $2.16\times$ wall-time speedup, on par with SoTA approaches like EAGLE-2, while orders of magnitude less data for training, and ablations show that DVI outperforms KL-only online distillation. DVI demonstrates that \emph{training-aware} self-speculation can deliver state-of-the-art, lossless speedups with minimal training overhead.