KVLinC : KV Cache Quantization with Hadamard Rotation and Linear Correction
作者: Utkarsh Saxena, Kaushik Roy
分类: cs.LG
发布日期: 2025-10-06
备注: 14 pages, 7 figures, 6 tables
💡 一句话要点
KVLinC通过哈达玛旋转和线性校正实现KV缓存的极低比特量化,提升LLM推理效率。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: KV缓存量化 低比特量化 哈达玛旋转 线性校正 大语言模型 推理加速 注意力机制
📋 核心要点
- 现有方法在极低比特量化KV缓存时,会引入显著误差,导致生成质量下降,这是LLM推理效率提升的瓶颈。
- KVLinC通过哈达玛旋转降低value量化误差,并使用线性校正适配器补偿key量化误差,从而缓解注意力误差。
- 实验表明,KVLinC在保证或超过现有基线性能的同时,实现了更高的KV缓存压缩率,并加速了LLM推理。
📝 摘要(中文)
本文提出KVLinC框架,旨在缓解大语言模型(LLM)中KV缓存量化在极低精度下引入的注意力误差。KVLinC结合了哈达玛旋转,以减少value张量中的量化误差,以及轻量级的线性校正适配器,显式地补偿量化key引入的误差。在LLaMA、Qwen2.5和Qwen3模型家族的广泛评估中,KVLinC始终匹配或超过强大的基线,同时实现更高的KV缓存压缩率。此外,本文实现了一个自定义的注意力核,与Flash Attention基线相比,推理速度提高了高达2.55倍,从而实现了高效的长上下文LLM推理。
🔬 方法详解
问题定义:论文旨在解决大语言模型(LLM)推理过程中,KV缓存进行极低比特量化时,由于量化误差累积导致的生成质量显著下降的问题。现有的量化方法在极低比特下会引入较大的误差,影响注意力机制的准确性,从而降低LLM的性能。
核心思路:论文的核心思路是通过结合哈达玛旋转和线性校正适配器来缓解KV缓存量化引入的误差。哈达玛旋转用于降低value张量的量化误差,而线性校正适配器则用于显式地补偿量化key引入的误差。这种方法旨在在极低比特量化下保持或提高LLM的生成质量。
技术框架:KVLinC框架主要包含两个关键模块:哈达玛旋转模块和线性校正适配器模块。首先,对value张量进行哈达玛旋转,以减少量化误差。然后,使用线性校正适配器来补偿量化key引入的误差。这两个模块协同工作,以最小化KV缓存量化对注意力机制的影响。此外,论文还实现了一个自定义的注意力核,以进一步提高推理效率。
关键创新:论文的关键创新在于将哈达玛旋转和线性校正适配器结合起来,用于缓解KV缓存量化引入的误差。哈达玛旋转能够有效地降低value张量的量化误差,而线性校正适配器则能够显式地补偿量化key引入的误差。这种结合使得KVLinC能够在极低比特量化下保持或提高LLM的生成质量。与现有方法相比,KVLinC能够实现更高的KV缓存压缩率和更快的推理速度。
关键设计:线性校正适配器采用轻量级的设计,以减少额外的计算开销。具体的参数设置和网络结构取决于具体的LLM模型和量化比特数。损失函数的设计旨在最小化量化误差对注意力机制的影响。自定义注意力核的设计旨在充分利用硬件加速,提高推理效率。
🖼️ 关键图片
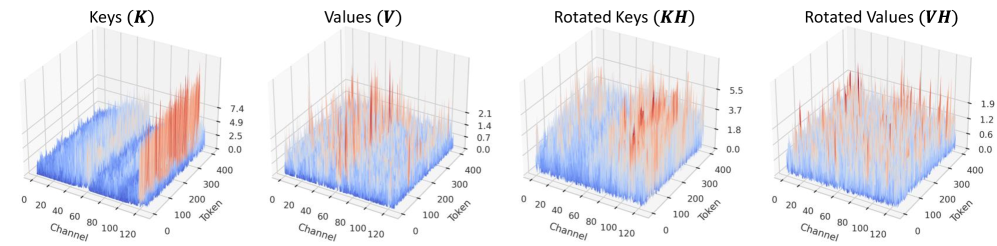
📊 实验亮点
实验结果表明,KVLinC在LLaMA、Qwen2.5和Qwen3模型家族上均表现出色,能够匹配或超过强大的基线,同时实现更高的KV缓存压缩率。此外,自定义注意力核实现了高达2.55倍的推理加速,显著提高了长上下文LLM的推理效率。这些结果表明KVLinC是一种有效的KV缓存量化方法,能够在保证性能的同时显著提高LLM的推理效率。
🎯 应用场景
KVLinC可应用于各种需要高效LLM推理的场景,例如移动设备上的本地LLM部署、边缘计算环境以及对延迟敏感的在线服务。通过降低KV缓存的存储需求和提高推理速度,KVLinC能够显著降低LLM的部署成本,并扩展其应用范围。未来,该技术有望推动LLM在资源受限环境中的广泛应用。
📄 摘要(原文)
Quantizing the key-value (KV) cache is a promising strategy for improving the inference efficiency of large language models (LLMs). However, aggressive quantization to very low precision (e.g., 2 bits) introduces significant errors in the stored key and value tensors, which propagate through the dot-product attention mechanism and ultimately degrade generation quality. To address this, we propose KVLinC, a framework to mitigate attention errors introduced by KV cache quantization in the extreme low-precision regime. KVLinC combines a Hadamard rotation, which reduces quantization error in values, with lightweight linear correction adapters that explicitly compensate for errors introduced by quantized keys. Across extensive evaluations on the LLaMA, Qwen2.5, and Qwen3 model families, KVLinC consistently matches or surpasses strong baselines while achieving higher KV-cache compression. Furthermore, we implement a custom attention kernel that results in upto 2.55x faster inference compared to Flash Attention baseline, enabling efficient long-context LLM inference.