Margin Adaptive DPO: Leveraging Reward Model for Granular Control in Preference Optimization
作者: Hyung Gyu Rho
分类: cs.LG, cs.AI
发布日期: 2025-10-06
💡 一句话要点
提出Margin Adaptive DPO,利用奖励模型实现偏好优化中的细粒度控制
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 偏好优化 直接偏好优化 奖励模型 自适应权重 实例级别控制
📋 核心要点
- 现有DPO方法依赖固定温度参数,导致在不同难度样本上学习效率不佳,易过拟合简单样本,忽略困难样本。
- MADPO通过训练奖励模型估计偏好边距,并以此自适应调整DPO损失权重,实现实例级别的细粒度控制。
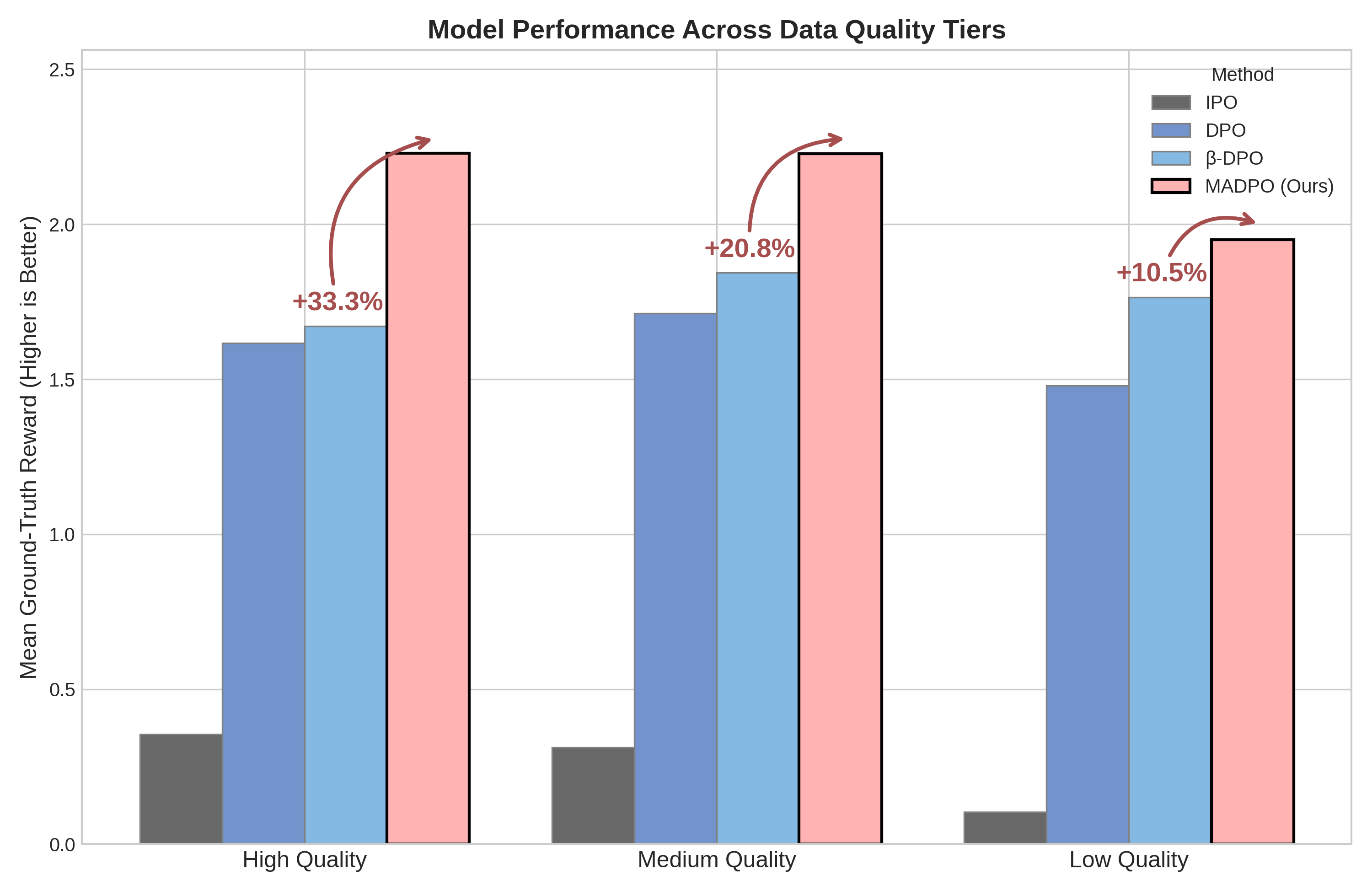
- 实验表明,MADPO在不同质量数据集上均显著优于现有方法,高质量数据上提升高达33.3%,低质量数据上提升10.5%。
📝 摘要(中文)
直接偏好优化(DPO)已成为对齐大型语言模型的一种简单有效的方法。然而,它依赖于固定的温度参数,导致在多样化的偏好数据上进行次优训练,造成在简单样本上的过拟合和从信息丰富的样本中学习不足。最近出现了一些方法来解决这个问题。虽然IPO解决了普遍的过拟合问题,但其统一的正则化可能过于保守。$β$-DPO这种更有针对性的方法也有其自身的局限性:其批次级别的自适应对混合边距对应用单一的、折衷的温度,其线性更新规则可能产生不稳定的负$β$值,并且其过滤机制丢弃了潜在有用的训练信号。在这项工作中,我们引入了Margin-Adaptive Direct Preference Optimization (MADPO),这是一种提供稳定、数据保留和实例级别解决方案的方法。MADPO采用了一种实用的两步方法:它首先训练一个奖励模型来估计偏好边距,然后使用这些边距来对每个单独的训练样本的DPO损失应用连续的、自适应的权重。这种重新加权方案创建了一个有效的目标边距,该边距对于困难的pair被放大,对于简单的pair被抑制,从而可以对学习信号进行细粒度控制。我们提供了全面的理论分析,证明MADPO具有良好的优化前景,并且对奖励模型估计误差具有鲁棒性。我们通过情感生成任务的实验验证了我们的理论,其中MADPO在不同质量的数据集上始终显著优于强大的基线。在高质量数据上,它比次优方法实现了高达+33.3%的性能提升,在低质量数据上实现了高达+10.5%的性能提升。我们的结果表明MADPO是一种更稳健和有原则的偏好对齐方法。
🔬 方法详解
问题定义:DPO方法在对齐大型语言模型时,使用固定的温度参数,无法根据样本的难易程度自适应调整学习强度。这导致模型容易在简单样本上过拟合,而对信息量大的困难样本学习不足。现有方法如IPO和β-DPO虽然尝试解决这个问题,但存在正则化过于保守、更新不稳定、丢弃训练信号等问题。
核心思路:MADPO的核心思路是利用奖励模型估计偏好边距,并根据边距大小自适应地调整DPO损失函数中每个样本的权重。对于困难样本,放大其损失权重,促使模型更多地关注;对于简单样本,则降低权重,避免过拟合。这种实例级别的权重调整能够更有效地利用训练数据,提升模型性能。
技术框架:MADPO包含两个主要步骤:1) 训练奖励模型:使用偏好数据训练一个奖励模型,用于估计每个样本对的偏好边距。2) 自适应权重DPO:使用奖励模型估计的边距,为每个训练样本计算一个自适应权重,然后使用加权后的DPO损失函数进行训练。整体流程是先训练奖励模型,再利用奖励模型指导DPO训练。
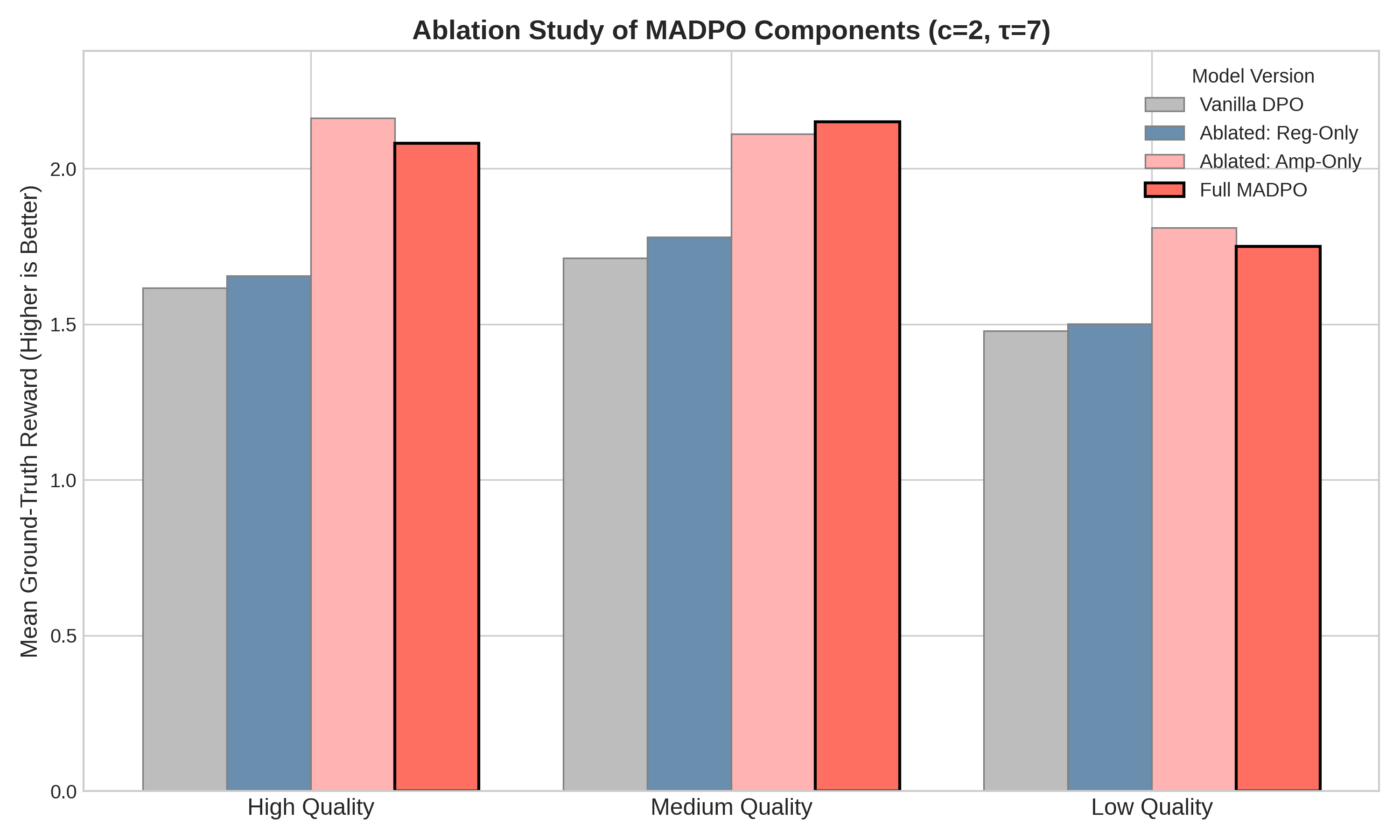
关键创新:MADPO的关键创新在于提出了基于奖励模型边距的实例级别自适应权重调整机制。与现有方法相比,MADPO能够更精细地控制每个样本的学习信号,避免了全局统一调整带来的问题。此外,MADPO的理论分析表明其优化前景良好,且对奖励模型误差具有鲁棒性。
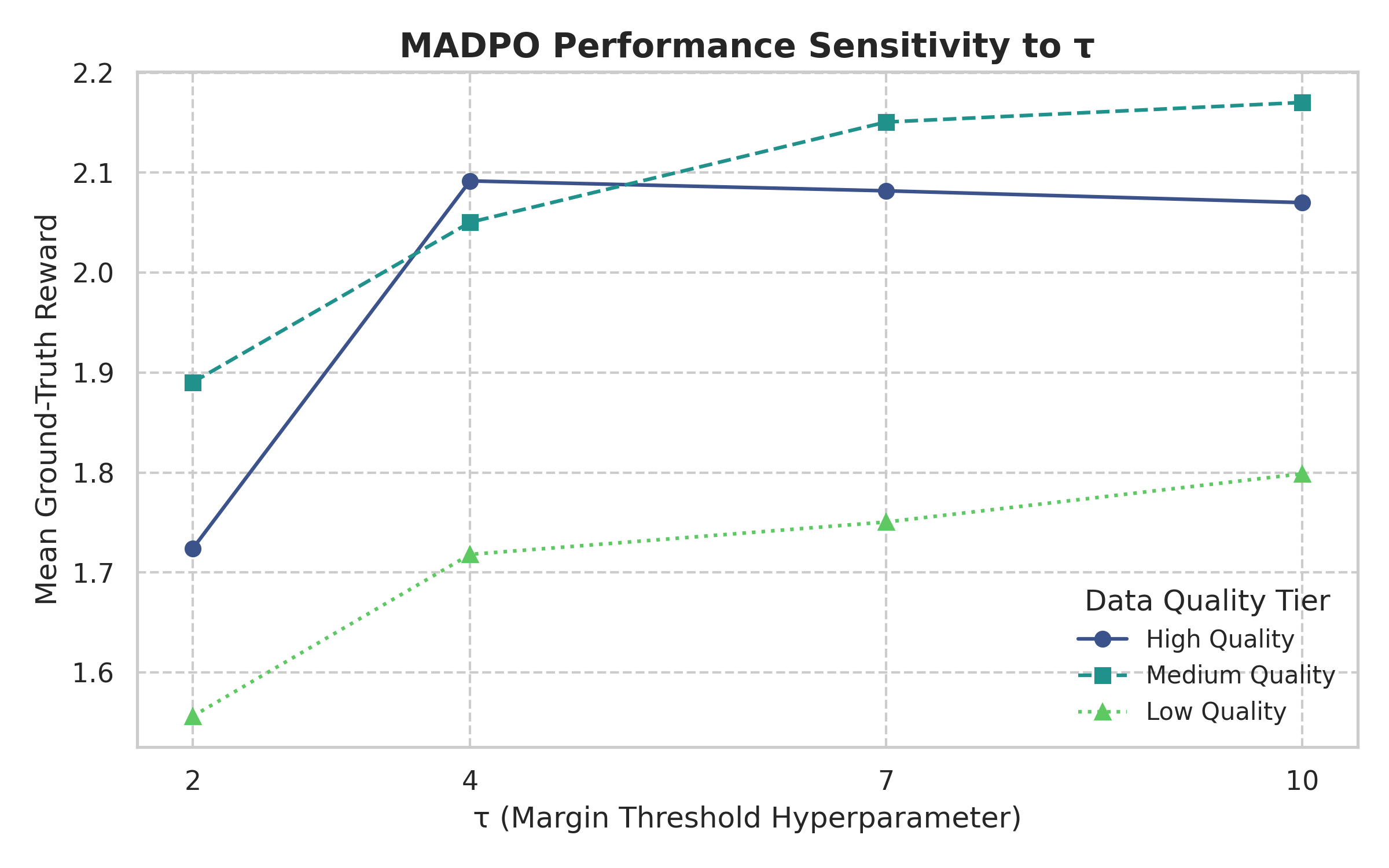
关键设计:MADPO的关键设计包括:1) 奖励模型的设计:奖励模型用于估计偏好边距,其结构和训练方式会影响边距估计的准确性。2) 自适应权重的计算方式:如何将奖励模型估计的边距转化为DPO损失函数的权重,需要仔细设计,以保证训练的稳定性和有效性。论文中采用了一种连续的、自适应的权重计算方法,具体细节未知。
🖼️ 关键图片
📊 实验亮点
MADPO在情感生成任务上取得了显著的性能提升。在高质量数据集上,MADPO比次优方法提升了高达33.3%,在低质量数据集上提升了10.5%。实验结果表明,MADPO能够更有效地利用偏好数据,提升模型的生成质量,并且对数据质量具有较强的鲁棒性。这些结果验证了MADPO的有效性和优越性。
🎯 应用场景
MADPO可应用于各种需要偏好对齐的场景,例如对话系统、文本生成、推荐系统等。通过更有效地利用偏好数据,MADPO能够提升模型的生成质量、用户满意度和整体性能。该方法在高质量和低质量数据集上均表现出优异的性能,表明其具有广泛的适用性和鲁棒性。未来,MADPO有望成为偏好对齐领域的重要技术。
📄 摘要(原文)
Direct Preference Optimization (DPO) has emerged as a simple and effective method for aligning large language models. However, its reliance on a fixed temperature parameter leads to suboptimal training on diverse preference data, causing overfitting on easy examples and under-learning from informative ones. Recent methods have emerged to counter this. While IPO addresses general overfitting, its uniform regularization can be overly conservative. The more targeted approach of $β$-DPO suffers from its own limitations: its batch-level adaptation applies a single, compromised temperature to mixed-margin pairs, its linear update rule can produce unstable negative $β$ values, and its filtering mechanism discards potentially useful training signals. In this work, we introduce Margin-Adaptive Direct Preference Optimization (MADPO), a method that provides a stable, data-preserving, and instance-level solution. MADPO employs a practical two-step approach: it first trains a reward model to estimate preference margins and then uses these margins to apply a continuous, adaptive weight to the DPO loss for each individual training sample. This re-weighting scheme creates an effective target margin that is amplified for hard pairs and dampened for easy pairs, allowing for granular control over the learning signal. We provide a comprehensive theoretical analysis, proving that MADPO has a well-behaved optimization landscape and is robust to reward model estimation errors. We validate our theory with experiments on a sentiment generation task, where MADPO consistently and significantly outperforms strong baselines across datasets of varying quality. It achieves performance gains of up to +33.3\% on High Quality data and +10.5\% on Low Quality data over the next-best method. Our results establish MADPO as a more robust and principled approach to preference alignment.