Stratum: System-Hardware Co-Design with Tiered Monolithic 3D-Stackable DRAM for Efficient MoE Serving
作者: Yue Pan, Zihan Xia, Po-Kai Hsu, Lanxiang Hu, Hyungyo Kim, Janak Sharda, Minxuan Zhou, Nam Sung Kim, Shimeng Yu, Tajana Rosing, Mingu Kang
分类: cs.AR, cs.ET, cs.LG
发布日期: 2025-10-06
💡 一句话要点
Stratum:面向高效MoE Serving的单片3D堆叠DRAM系统硬件协同设计
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 混合专家模型 MoE Serving 单片3D DRAM 近内存处理 系统硬件协同设计 GPU加速 大语言模型
📋 核心要点
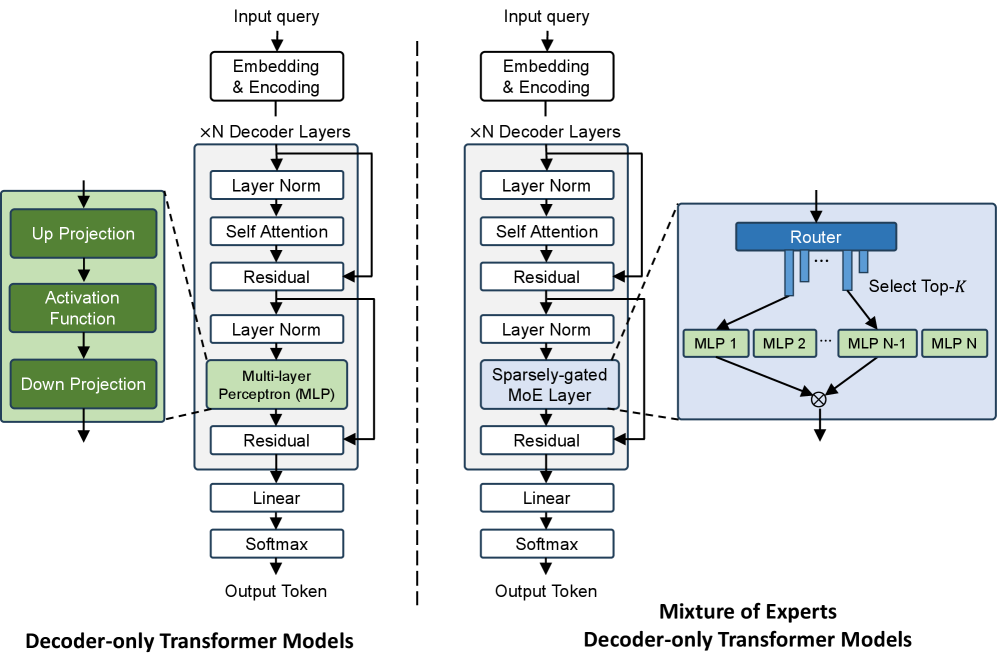
- MoE模型参数量巨大,但硬件部署面临数据量挑战,现有方案难以兼顾性能与效率。
- Stratum采用系统硬件协同设计,结合Mono3D DRAM、近内存处理和GPU加速,优化MoE Serving。
- 实验表明,Stratum在解码吞吐量和能效方面,相比GPU基线分别提升高达8.29倍和7.66倍。
📝 摘要(中文)
随着大型语言模型(LLMs)的不断发展,混合专家(MoE)架构已成为在各种任务中实现最先进性能的主流设计。MoE模型使用稀疏门控,每个输入仅激活少数几个专家子网络,从而以类似于小得多的模型的推理成本实现数十亿参数的容量。然而,由于MoE层引入的海量数据量,此类模型通常对硬件部署构成挑战。为了解决服务MoE模型的挑战,我们提出Stratum,一种系统硬件协同设计方法,它结合了新型存储技术单片3D堆叠DRAM(Mono3D DRAM)、近内存处理(NMP)和GPU加速。逻辑芯片和Mono3D DRAM芯片通过混合键合连接,而Mono3D DRAM堆栈和GPU通过硅中介层互连。Mono3D DRAM由于其单片结构实现的密集垂直互连间距,提供比HBM更高的内部带宽,这支持更高性能的近内存处理的实现。此外,我们通过构建内部存储层并根据访问可能性跨层分配数据来解决Mono3D DRAM沿z轴的激进垂直缩放引入的延迟差异,并通过基于主题的专家使用预测来指导,从而提高NMP吞吐量。与GPU基线相比,Stratum系统在各种基准测试中实现了高达8.29倍的解码吞吐量提升和7.66倍的能效提升。
🔬 方法详解
问题定义:论文旨在解决大型语言模型中混合专家(MoE)模型在硬件部署时面临的挑战,特别是由于MoE层引入的海量数据量导致的性能瓶颈和能效问题。现有方法,如使用传统GPU或HBM,难以充分利用MoE模型的稀疏性,导致计算资源浪费和延迟增加。
核心思路:论文的核心思路是采用系统硬件协同设计,将新型存储技术Mono3D DRAM与近内存处理(NMP)相结合,并利用GPU进行加速。通过Mono3D DRAM提供高带宽和低延迟的内存访问,NMP负责处理部分计算任务,从而减轻GPU的负担,提高整体系统的吞吐量和能效。这种设计充分利用了MoE模型的稀疏性,只激活少量专家子网络,减少了数据传输和计算量。
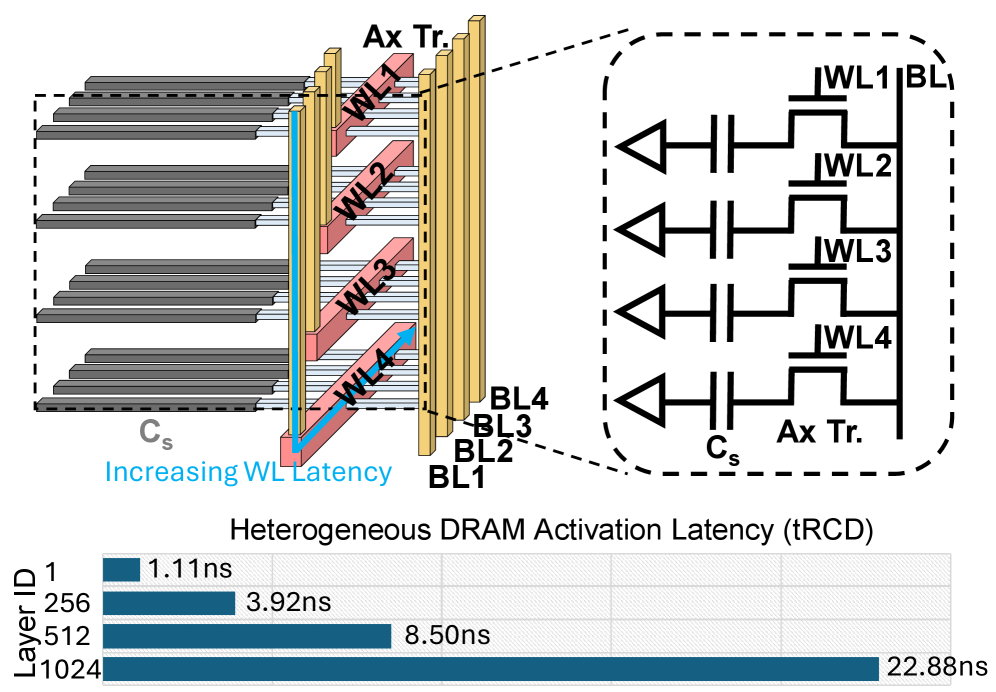
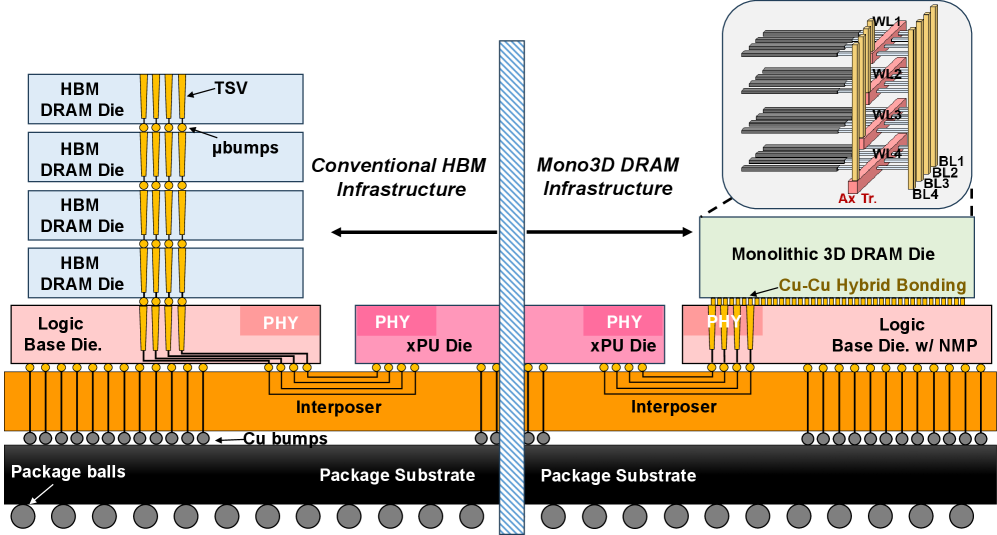
技术框架:Stratum系统的整体架构包括:1)逻辑芯片和Mono3D DRAM芯片通过混合键合连接;2)Mono3D DRAM堆栈和GPU通过硅中介层互连。系统内部,Mono3D DRAM被划分为多个层级(tiers),数据根据访问频率分配到不同的层级,高频数据存储在更靠近计算单元的层级,以减少延迟。同时,系统利用基于主题的专家使用预测来指导数据分配,进一步优化NMP的吞吐量。
关键创新:论文的关键创新在于:1)采用了Mono3D DRAM技术,相比HBM,Mono3D DRAM具有更高的内部带宽和更低的延迟,更适合NMP;2)提出了基于主题的专家使用预测方法,能够更准确地预测哪些专家会被激活,从而优化数据在Mono3D DRAM不同层级之间的分配;3)系统硬件协同设计,充分利用了Mono3D DRAM、NMP和GPU的优势,实现了更高的性能和能效。
关键设计:Mono3D DRAM的层级划分是关键设计之一,需要根据实际应用场景和数据访问模式进行优化。基于主题的专家使用预测模型的准确性直接影响数据分配的效果,需要仔细选择特征和训练算法。此外,NMP的具体实现方式,例如选择哪些计算任务在NMP上执行,也需要根据硬件资源和计算复杂度进行权衡。
🖼️ 关键图片
📊 实验亮点
实验结果表明,Stratum系统在各种基准测试中,相比GPU基线,实现了高达8.29倍的解码吞吐量提升和7.66倍的能效提升。这些显著的性能提升证明了Stratum系统硬件协同设计的有效性,以及Mono3D DRAM和近内存处理在MoE模型Serving中的潜力。
🎯 应用场景
Stratum系统适用于需要高效处理大型MoE模型的各种应用场景,例如大规模语言模型的推理服务、推荐系统、以及其他需要处理海量数据的AI应用。该研究成果有望降低MoE模型的部署成本,提高推理速度,并推动AI技术在更多领域的应用。
📄 摘要(原文)
As Large Language Models (LLMs) continue to evolve, Mixture of Experts (MoE) architecture has emerged as a prevailing design for achieving state-of-the-art performance across a wide range of tasks. MoE models use sparse gating to activate only a handful of expert sub-networks per input, achieving billion-parameter capacity with inference costs akin to much smaller models. However, such models often pose challenges for hardware deployment due to the massive data volume introduced by the MoE layers. To address the challenges of serving MoE models, we propose Stratum, a system-hardware co-design approach that combines the novel memory technology Monolithic 3D-Stackable DRAM (Mono3D DRAM), near-memory processing (NMP), and GPU acceleration. The logic and Mono3D DRAM dies are connected through hybrid bonding, whereas the Mono3D DRAM stack and GPU are interconnected via silicon interposer. Mono3D DRAM offers higher internal bandwidth than HBM thanks to the dense vertical interconnect pitch enabled by its monolithic structure, which supports implementations of higher-performance near-memory processing. Furthermore, we tackle the latency differences introduced by aggressive vertical scaling of Mono3D DRAM along the z-dimension by constructing internal memory tiers and assigning data across layers based on access likelihood, guided by topic-based expert usage prediction to boost NMP throughput. The Stratum system achieves up to 8.29x improvement in decoding throughput and 7.66x better energy efficiency across various benchmarks compared to GPU baselines.