CMT-Benchmark: A Benchmark for Condensed Matter Theory Built by Expert Researchers
作者: Haining Pan, James V. Roggeveen, Erez Berg, Juan Carrasquilla, Debanjan Chowdhury, Surya Ganguli, Federico Ghimenti, Juraj Hasik, Henry Hunt, Hong-Chen Jiang, Mason Kamb, Ying-Jer Kao, Ehsan Khatami, Michael J. Lawler, Di Luo, Titus Neupert, Xiaoliang Qi, Michael P. Brenner, Eun-Ah Kim
分类: cs.LG, cs.AI
发布日期: 2025-10-06
备注: 19 pages, 3 figures
💡 一句话要点
提出CMT-Benchmark:一个由专家构建的凝聚态理论基准,用于评估LLM的物理推理能力。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 凝聚态理论 大型语言模型 基准数据集 物理推理 自动评估
📋 核心要点
- 现有大型语言模型在硬科学领域,特别是凝聚态理论研究问题上的评估数据匮乏,无法准确衡量其物理推理能力。
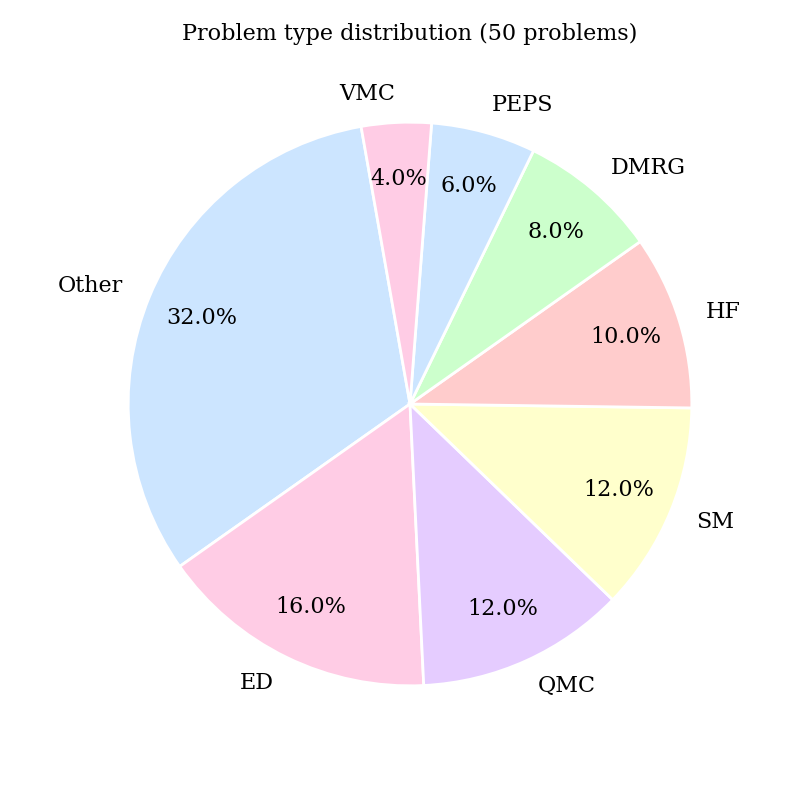
- CMT-Benchmark数据集由专家设计,包含50个凝聚态理论问题,涵盖多种计算和分析方法,并提供专家标准答案进行程序化评估。
- 实验结果表明,现有前沿LLM在CMT-Benchmark上表现不佳,突显了其在物理推理方面的不足,为未来AI研究助理的开发指明方向。
📝 摘要(中文)
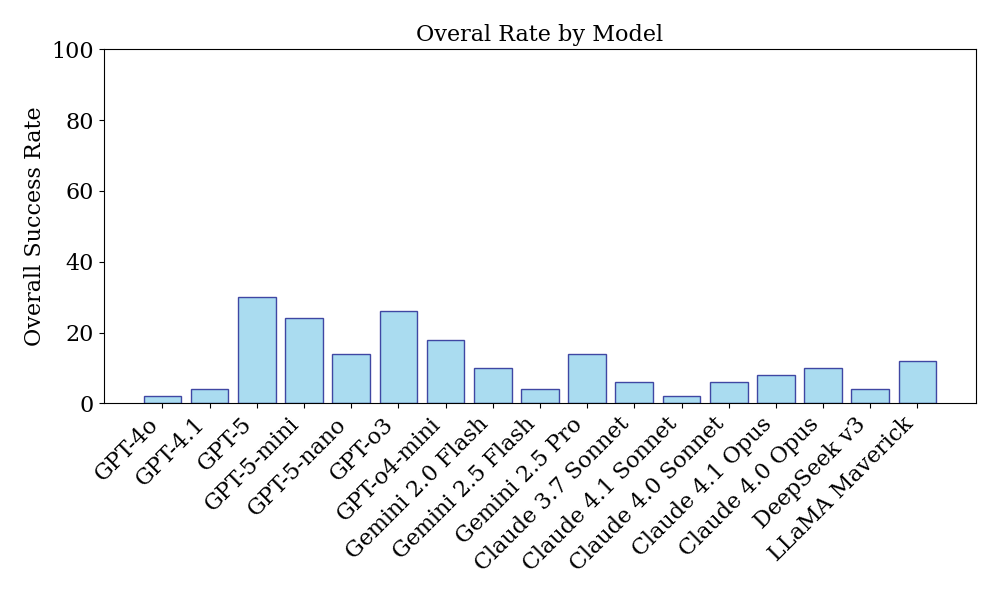
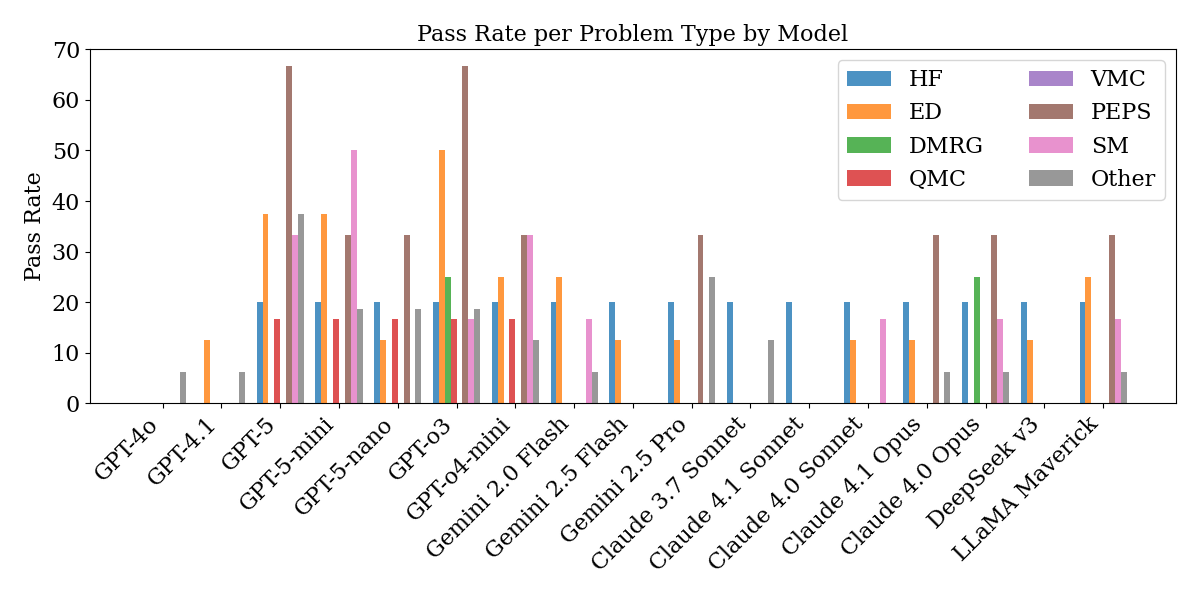
大型语言模型(LLM)在编码和数学问题解决方面取得了显著进展,但在硬科学领域高级研究问题的评估仍然不足。为了填补这一空白,我们提出了CMT-Benchmark,这是一个包含50个问题的凝聚态理论(CMT)数据集,难度达到专家研究员水平。主题涵盖量子多体和经典统计力学中的分析和计算方法。该数据集由来自世界各地的专家研究员小组设计和验证。我们通过一个协作环境构建数据集,该环境挑战专家小组编写和完善他们希望研究助理解决的问题,包括Hartree-Fock、精确对角化、量子/变分蒙特卡罗、密度矩阵重整化群(DMRG)、量子/经典统计力学和模型构建。我们通过程序化地将解决方案与专家提供的标准答案进行比较来评估LLM。我们开发了机器评分,包括通过正规排序对非对易算符的符号处理。它们也可以推广到各种任务。我们的评估表明,前沿模型在数据集中的所有问题上都表现不佳,突显了当前LLM在物理推理技能方面的差距。值得注意的是,专家们通过与LLM互动并利用常见的失败模式,确定了创建越来越难的问题的策略。最好的模型GPT5解决了30%的问题;17个模型(GPT、Gemini、Claude、DeepSeek、Llama)的平均值为11.4±2.1%。此外,18个问题没有被17个模型中的任何一个解决,26个问题最多被一个模型解决。这些未解决的问题涵盖量子蒙特卡罗、变分蒙特卡罗和DMRG。答案有时违反基本对称性或具有非物理的尺度维度。我们相信这个基准将指导开发出有能力的AI研究助理和导师。
🔬 方法详解
问题定义:论文旨在解决缺乏针对大型语言模型(LLM)在凝聚态理论(CMT)领域进行有效评估的问题。现有方法无法准确衡量LLM在解决复杂物理问题时的推理能力,尤其是在涉及量子多体、统计力学等高级概念时。这阻碍了LLM在科学研究中的应用,也难以发现LLM在物理理解上的局限性。
核心思路:论文的核心思路是构建一个高质量、高难度的CMT基准数据集,该数据集由领域专家设计,涵盖广泛的理论和计算方法。通过程序化的自动评估,可以客观地衡量LLM在解决CMT问题时的能力,并识别其在物理推理方面的不足。这种方法能够为LLM的改进提供明确的目标和方向。
技术框架:CMT-Benchmark的构建流程主要包括以下几个阶段: 1. 问题设计:邀请凝聚态理论领域的专家设计具有挑战性的问题,涵盖Hartree-Fock、精确对角化、量子/变分蒙特卡罗、DMRG等多种方法。 2. 答案验证:专家提供问题的标准答案,并进行验证,确保答案的正确性和可靠性。 3. 自动评估:开发自动评估系统,能够程序化地比较LLM的答案与标准答案,并进行评分。 4. 结果分析:分析LLM在不同问题上的表现,识别其常见的错误和不足,并为未来的改进提供建议。
关键创新:该论文的关键创新在于: 1. 专家构建的数据集:CMT-Benchmark由领域专家设计,保证了问题的难度和专业性,能够有效评估LLM的物理推理能力。 2. 程序化的自动评估:自动评估系统能够客观地衡量LLM的答案,避免了人为因素的干扰。 3. 非对易算符的符号处理:评估系统能够处理非对易算符,这对于评估LLM在量子力学问题上的能力至关重要。 4. 难度递增的问题设计策略:专家通过与LLM互动,识别其弱点,并设计更具挑战性的问题,从而不断提高基准的难度。
关键设计: 1. 问题类型:涵盖分析和计算方法,包括Hartree-Fock、精确对角化、量子/变分蒙特卡罗、DMRG等。 2. 评估指标:采用程序化的自动评估,比较LLM的答案与标准答案,并进行评分。 3. 难度控制:通过专家设计和迭代,确保问题的难度达到专家研究员水平。 4. 错误分析:分析LLM的常见错误,例如违反基本对称性或具有非物理的尺度维度。
🖼️ 关键图片
📊 实验亮点
实验结果表明,即使是当前最先进的LLM(如GPT5)在CMT-Benchmark上的表现也远低于专家水平。GPT5仅解决了30%的问题,而其他模型(GPT、Gemini、Claude、DeepSeek、Llama)的平均解决率仅为11.4±2.1%。此外,有18个问题没有被任何模型解决,26个问题最多被一个模型解决,突显了LLM在解决复杂物理问题方面的巨大挑战。
🎯 应用场景
该研究成果可应用于开发更智能的AI研究助手,辅助科学家进行凝聚态物理研究,加速新材料的发现和理论发展。此外,该基准也可用于评估和提升LLM在其他科学领域的推理能力,推动AI在科学研究中的更广泛应用。未来,该基准可以扩展到其他物理领域,例如高能物理和天体物理。
📄 摘要(原文)
Large language models (LLMs) have shown remarkable progress in coding and math problem-solving, but evaluation on advanced research-level problems in hard sciences remains scarce. To fill this gap, we present CMT-Benchmark, a dataset of 50 problems covering condensed matter theory (CMT) at the level of an expert researcher. Topics span analytical and computational approaches in quantum many-body, and classical statistical mechanics. The dataset was designed and verified by a panel of expert researchers from around the world. We built the dataset through a collaborative environment that challenges the panel to write and refine problems they would want a research assistant to solve, including Hartree-Fock, exact diagonalization, quantum/variational Monte Carlo, density matrix renormalization group (DMRG), quantum/classical statistical mechanics, and model building. We evaluate LLMs by programmatically checking solutions against expert-supplied ground truth. We developed machine-grading, including symbolic handling of non-commuting operators via normal ordering. They generalize across tasks too. Our evaluations show that frontier models struggle with all of the problems in the dataset, highlighting a gap in the physical reasoning skills of current LLMs. Notably, experts identified strategies for creating increasingly difficult problems by interacting with the LLMs and exploiting common failure modes. The best model, GPT5, solves 30\% of the problems; average across 17 models (GPT, Gemini, Claude, DeepSeek, Llama) is 11.4$\pm$2.1\%. Moreover, 18 problems are solved by none of the 17 models, and 26 by at most one. These unsolved problems span Quantum Monte Carlo, Variational Monte Carlo, and DMRG. Answers sometimes violate fundamental symmetries or have unphysical scaling dimensions. We believe this benchmark will guide development toward capable AI research assistants and tutors.