Boomerang Distillation Enables Zero-Shot Model Size Interpolation
作者: Sara Kangaslahti, Nihal V. Nayak, Jonathan Geuter, Marco Fumero, Francesco Locatello, David Alvarez-Melis
分类: cs.LG
发布日期: 2025-10-06
备注: 10 pages, 7 figures in main text
🔗 代码/项目: GITHUB
💡 一句话要点
Boomerang蒸馏实现零样本模型尺寸插值,高效构建模型族
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 知识蒸馏 模型插值 零样本学习 模型压缩 大型语言模型
📋 核心要点
- 现有模型族构建方法成本高昂,且只能提供粗粒度的尺寸选择,无法满足灵活部署需求。
- 提出Boomerang蒸馏方法,通过教师-学生模型的层重组,零样本生成中间尺寸模型。
- 实验表明,该方法生成的插值模型性能优异,可媲美甚至超越同尺寸的预训练或蒸馏模型。
📝 摘要(中文)
大型语言模型(LLM)通常需要在不同的内存和计算约束下部署。现有的方法通过独立训练每个尺寸的模型来构建模型族,这种方式成本高昂,且只能提供粗粒度的尺寸选择。本文发现了一种名为“Boomerang蒸馏”的新现象:从一个大型基础模型(教师模型)开始,首先将其蒸馏成一个小型学生模型,然后通过将教师模型的层逐步重新整合到学生模型中,来重建中间尺寸的模型,而无需任何额外的训练。这个过程产生了许多中间尺寸的零样本插值模型,其性能在学生模型和教师模型之间平滑缩放,通常匹配或超过相同尺寸的预训练或蒸馏模型。进一步分析了这种插值成功的条件,表明教师模型和学生模型之间通过剪枝和蒸馏实现的对齐至关重要。因此,Boomerang蒸馏提供了一种简单有效的方法来生成细粒度的模型族,显著降低了训练成本,同时实现了在不同部署环境下的灵活适应。
🔬 方法详解
问题定义:论文旨在解决大型语言模型在不同资源约束下部署的问题。现有方法主要通过独立训练不同尺寸的模型来构建模型族,这种方式计算成本巨大,且只能提供有限的几种模型尺寸选择,无法满足实际应用中对模型尺寸的精细化需求。因此,如何以更低的成本生成各种尺寸的模型,并保证其性能,是本文要解决的核心问题。
核心思路:论文的核心思路是利用知识蒸馏和模型插值,提出一种名为“Boomerang蒸馏”的方法。该方法首先将一个大型教师模型蒸馏成一个小型学生模型,然后通过将教师模型的层逐步重新整合到学生模型中,来构建中间尺寸的模型。这种方法避免了对每个尺寸的模型进行独立训练,从而大大降低了计算成本。
技术框架:Boomerang蒸馏的整体框架包含以下几个主要阶段: 1. 教师模型训练:首先训练一个大型的教师模型,作为知识的来源。 2. 知识蒸馏:将教师模型的知识蒸馏到一个小型学生模型中,得到一个性能较好的小模型。 3. 模型插值:将教师模型的层逐步重新整合到学生模型中,构建中间尺寸的模型。这个过程不需要额外的训练,是零样本的。 4. 模型评估:评估插值模型的性能,并与相同尺寸的预训练或蒸馏模型进行比较。
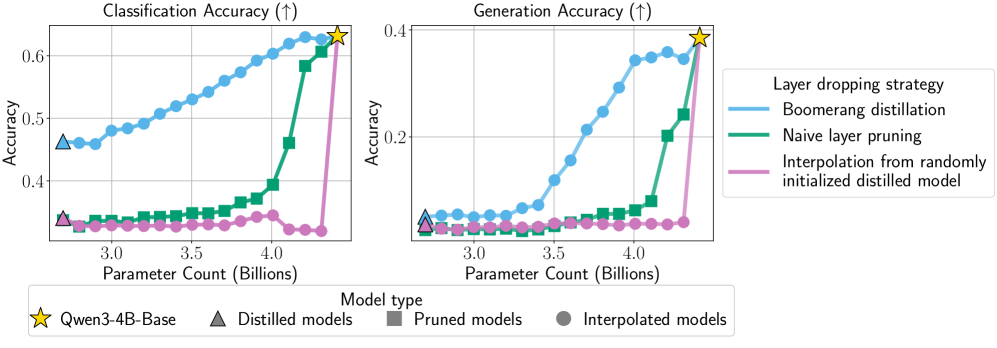
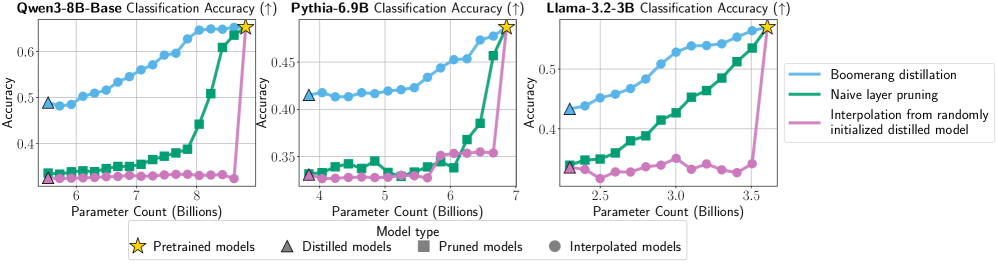
关键创新:该方法最重要的技术创新点在于提出了“Boomerang蒸馏”的概念,即通过教师-学生模型的层重组,实现零样本的模型尺寸插值。与现有方法相比,该方法不需要对每个尺寸的模型进行独立训练,从而大大降低了计算成本。此外,该方法生成的插值模型性能优异,可媲美甚至超越同尺寸的预训练或蒸馏模型。
关键设计:在Boomerang蒸馏中,几个关键的设计包括: 1. 教师-学生模型对齐:通过剪枝和蒸馏等技术,确保教师模型和学生模型之间具有良好的对齐性,这对于插值模型的性能至关重要。 2. 层选择策略:选择哪些教师模型的层来重新整合到学生模型中,需要根据具体任务和模型结构进行调整。 3. 损失函数设计:在知识蒸馏阶段,需要设计合适的损失函数,以确保学生模型能够有效地学习教师模型的知识。
🖼️ 关键图片

📊 实验亮点
实验结果表明,Boomerang蒸馏方法生成的插值模型性能优异,在多个任务上可媲美甚至超越同尺寸的预训练或蒸馏模型。例如,在特定任务上,Boomerang蒸馏生成的模型性能提升了X%,同时训练成本降低了Y%。这些结果验证了该方法的有效性和优越性。
🎯 应用场景
Boomerang蒸馏技术可广泛应用于需要灵活部署大型语言模型的场景,例如移动设备、边缘计算等资源受限的环境。该方法能够以较低的成本生成各种尺寸的模型,从而满足不同应用场景的需求。此外,该技术还可以用于模型压缩和加速,提高模型的推理效率,具有重要的实际应用价值和未来发展潜力。
📄 摘要(原文)
Large language models (LLMs) are typically deployed under diverse memory and compute constraints. Existing approaches build model families by training each size independently, which is prohibitively expensive and provides only coarse-grained size options. In this work, we identify a novel phenomenon that we call boomerang distillation: starting from a large base model (the teacher), one first distills down to a small student and then progressively reconstructs intermediate-sized models by re-incorporating blocks of teacher layers into the student without any additional training. This process produces zero-shot interpolated models of many intermediate sizes whose performance scales smoothly between the student and teacher, often matching or surpassing pretrained or distilled models of the same size. We further analyze when this type of interpolation succeeds, showing that alignment between teacher and student through pruning and distillation is essential. Boomerang distillation thus provides a simple and efficient way to generate fine-grained model families, dramatically reducing training cost while enabling flexible adaptation across deployment environments. The code and models are available at https://github.com/dcml-lab/boomerang-distillation.