Test-Time Scaling in Diffusion LLMs via Hidden Semi-Autoregressive Experts
作者: Jihoon Lee, Hoyeon Moon, Kevin Zhai, Arun Kumar Chithanar, Anit Kumar Sahu, Soummya Kar, Chul Lee, Souradip Chakraborty, Amrit Singh Bedi
分类: cs.LG, cs.AI
发布日期: 2025-10-06
💡 一句话要点
提出HEX,通过隐式半自回归专家集成,提升扩散LLM的推理时性能。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 扩散语言模型 测试时缩放 半自回归模型 专家集成 推理基准
📋 核心要点
- 扩散LLM推理时,固定推理策略未能充分利用模型学习到的不同生成顺序的专家知识,导致性能受限。
- 提出HEX方法,通过集成不同块大小的生成路径,利用隐式半自回归专家,避免单一固定策略的失败模式。
- 实验表明,HEX在多个推理基准上显著提升了准确率,无需额外训练,优于现有方法。
📝 摘要(中文)
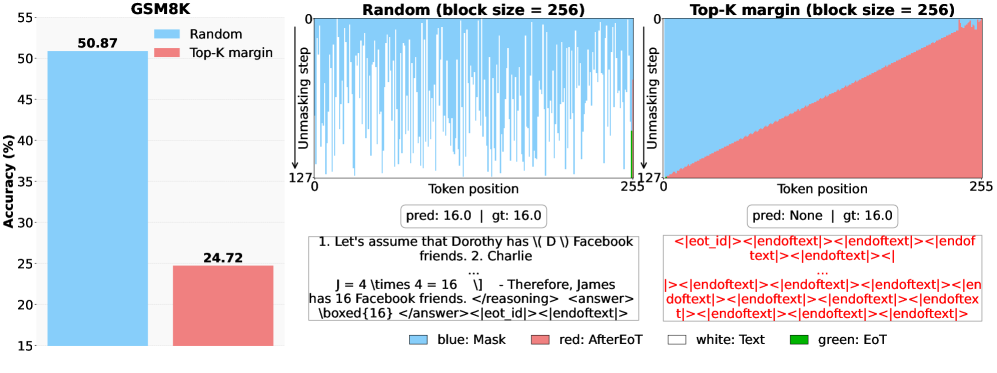
本文研究了扩散语言模型(dLLM)在建模数据分布中的极端依赖性时的利用问题。研究发现,在文本数据上训练的dLLM隐式地学习了半自回归专家的混合,不同的生成顺序揭示了不同的专门行为。常见的固定推理时间表会因未能利用这种潜在的集成而导致性能下降。为此,本文提出了一种无需训练的推理方法HEX(用于测试时缩放的隐式半自回归专家),该方法集成了异构块调度。通过对不同块大小的生成路径进行多数投票,HEX能够稳健地避免与任何单个固定调度相关的失败模式。在GSM8K等推理基准测试中,它将准确率提高了高达3.56倍(从24.72%到88.10%),优于top-K margin inference和GRPO等专门的微调方法,且无需额外训练。HEX甚至在MATH基准测试中从16.40%提高到40.00%,在ARC-C上的科学推理从54.18%提高到87.80%,在TruthfulQA上从28.36%提高到57.46%。研究结果为基于扩散的LLM(dLLM)中的测试时缩放建立了一种新的范例,揭示了掩码执行的顺序在决定推理期间的性能方面起着关键作用。
🔬 方法详解
问题定义:扩散语言模型(dLLM)在推理时,通常采用固定的掩码策略和生成顺序。然而,dLLM在训练过程中学习到了多种不同的生成模式,这些模式可以被视为不同的“专家”。固定策略无法充分利用这些专家知识,导致推理性能受限。现有方法,如top-K margin inference和微调方法,要么计算成本高昂,要么需要额外的训练数据。
核心思路:论文的核心思路是,dLLM实际上学习到了一组隐式的半自回归专家,每个专家对应一种特定的生成顺序。通过在推理时集成这些不同的专家,可以提高模型的鲁棒性和准确性。HEX方法通过对不同块大小的生成路径进行多数投票,实现了专家的集成。
技术框架:HEX方法是一个无需训练的推理方法,主要包含以下步骤: 1. 生成多个候选序列:使用不同的块大小和生成顺序,生成多个候选的文本序列。 2. 多数投票:对生成的多个候选序列进行多数投票,选择出现频率最高的token作为最终的生成结果。
关键创新:HEX方法的关键创新在于: 1. 隐式专家集成:发现了dLLM中存在的隐式半自回归专家,并提出了一种有效的方法来集成这些专家。 2. 无需训练:HEX方法无需额外的训练,可以直接应用于现有的dLLM模型。 3. 异构块调度:通过使用不同的块大小和生成顺序,探索了不同的生成路径,提高了模型的鲁棒性。
关键设计:HEX方法的关键设计包括: 1. 块大小的选择:不同的块大小对应不同的生成顺序和专家知识。论文中可能探讨了不同块大小对性能的影响。 2. 投票策略:多数投票是一种简单的集成方法,但可以有效地提高模型的鲁棒性。可能还存在其他的投票策略。 3. 计算效率:由于需要生成多个候选序列,HEX方法的计算成本可能会比较高。论文中可能讨论了如何提高计算效率。
🖼️ 关键图片


📊 实验亮点
HEX方法在多个推理基准上取得了显著的性能提升。在GSM8K上,准确率从24.72%提升到88.10%,提升幅度高达3.56倍。在MATH上,准确率从16.40%提升到40.00%。在ARC-C上,准确率从54.18%提升到87.80%。在TruthfulQA上,准确率从28.36%提升到57.46%。这些结果表明,HEX方法是一种有效的测试时缩放方法,可以显著提高扩散语言模型的推理性能。
🎯 应用场景
HEX方法可应用于各种需要高质量文本生成的场景,例如数学问题求解、科学推理、常识问答等。该方法无需额外训练,易于部署,可以提升现有扩散语言模型的性能,具有广泛的应用前景。未来,可以探索更有效的专家集成策略,进一步提高模型的性能。
📄 摘要(原文)
Diffusion-based large language models (dLLMs) are trained flexibly to model extreme dependence in the data distribution; however, how to best utilize this information at inference time remains an open problem. In this work, we uncover an interesting property of these models: dLLMs trained on textual data implicitly learn a mixture of semi-autoregressive experts, where different generation orders reveal different specialized behaviors. We show that committing to any single, fixed inference time schedule, a common practice, collapses performance by failing to leverage this latent ensemble. To address this, we introduce HEX (Hidden semiautoregressive EXperts for test-time scaling), a training-free inference method that ensembles across heterogeneous block schedules. By doing a majority vote over diverse block-sized generation paths, HEX robustly avoids failure modes associated with any single fixed schedule. On reasoning benchmarks such as GSM8K, it boosts accuracy by up to 3.56X (from 24.72% to 88.10%), outperforming top-K margin inference and specialized fine-tuned methods like GRPO, without additional training. HEX even yields significant gains on MATH benchmark from 16.40% to 40.00%, scientific reasoning on ARC-C from 54.18% to 87.80%, and TruthfulQA from 28.36% to 57.46%. Our results establish a new paradigm for test-time scaling in diffusion-based LLMs (dLLMs), revealing that the sequence in which masking is performed plays a critical role in determining performance during inference.