Curiosity-Driven Development of Action and Language in Robots Through Self-Exploration
作者: Theodore Jerome Tinker, Kenji Doya, Jun Tani
分类: stat.ML, cs.LG
发布日期: 2025-10-06 (更新: 2025-12-16)
备注: 20 pages, 19 pages of supplementary material
💡 一句话要点
提出基于好奇心驱动的机器人动作与语言学习框架,实现自主探索和组合泛化。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 好奇心驱动学习 主动推理 强化学习 机器人语言学习 组合泛化
📋 核心要点
- 现有语言模型需要大量数据,而人类婴儿仅需少量经验即可泛化学习语言,存在效率差异。
- 该研究提出一种基于好奇心驱动的机器人学习框架,结合主动推理和强化学习,实现自主探索。
- 实验表明,该框架能有效提升组合泛化能力,并模拟了人类语言学习中的一些典型现象。
📝 摘要(中文)
本研究探讨了人类婴儿如何通过少量经验泛化学习语言,而大型语言模型需要数十亿的训练token。为了理解人类高效学习的机制,我们通过实验研究了机器人代理如何通过好奇心驱动的自我探索来学习执行与祈使句相关的动作(例如,推动红色立方体)。我们的方法将主动推理与强化学习相结合,从而实现内驱的开发性学习。仿真结果揭示了与发展心理学观察结果相对应的关键发现:i) 随着组合元素规模的增加,泛化能力显著提高;ii) 好奇心通过自我探索提高学习效果;iii) 句子和动作的机械配对先于组合泛化;iv) 简单的动作在依赖它们的复杂动作之前发展;v) 异常处理会引起U型发展性能,类似于儿童语言学习中的表征重述模式。这些结果表明,好奇心驱动的主动推理可以解释内驱的感知运动-语言学习如何支持人类和人工智能代理中的可扩展组合泛化和异常处理。
🔬 方法详解
问题定义:论文旨在解决机器人如何像人类婴儿一样,通过少量经验进行泛化学习,特别是学习将自然语言指令与相应的动作联系起来的问题。现有方法通常需要大量标注数据,且泛化能力有限,无法模拟人类语言学习的效率和灵活性。
核心思路:论文的核心思路是利用好奇心驱动的自我探索,结合主动推理和强化学习,使机器人能够自主地发现和学习新的动作和语言组合。通过内在动机引导探索,避免了对大量外部监督数据的依赖,从而提高学习效率和泛化能力。
技术框架:整体框架包含以下几个主要模块:1) 感知模块:负责接收环境中的视觉和语言信息;2) 动作模块:负责执行机器人控制指令;3) 好奇心模块:基于预测误差或信息增益来驱动探索;4) 主动推理模块:利用概率模型来推断当前状态和未来动作;5) 强化学习模块:根据奖励信号来优化动作策略。整个流程是机器人首先根据好奇心选择一个动作,执行后观察环境变化,计算奖励信号,并更新模型参数。
关键创新:最重要的技术创新点在于将好奇心驱动的探索与主动推理和强化学习相结合,形成一个内驱的学习循环。这种方法允许机器人自主地发现和学习新的动作和语言组合,而无需依赖大量的外部监督数据。与传统的监督学习方法相比,该方法更具灵活性和泛化能力。
关键设计:论文中可能涉及的关键设计包括:1) 好奇心度量方式:例如,使用预测误差或信息增益来量化好奇心;2) 奖励函数设计:如何设计奖励函数来鼓励机器人探索新的动作和语言组合;3) 网络结构设计:如何设计感知模块和动作模块的网络结构,以便有效地提取特征和执行动作;4) 主动推理模型的选择:例如,使用变分自编码器(VAE)或生成对抗网络(GAN)来构建主动推理模型。
🖼️ 关键图片
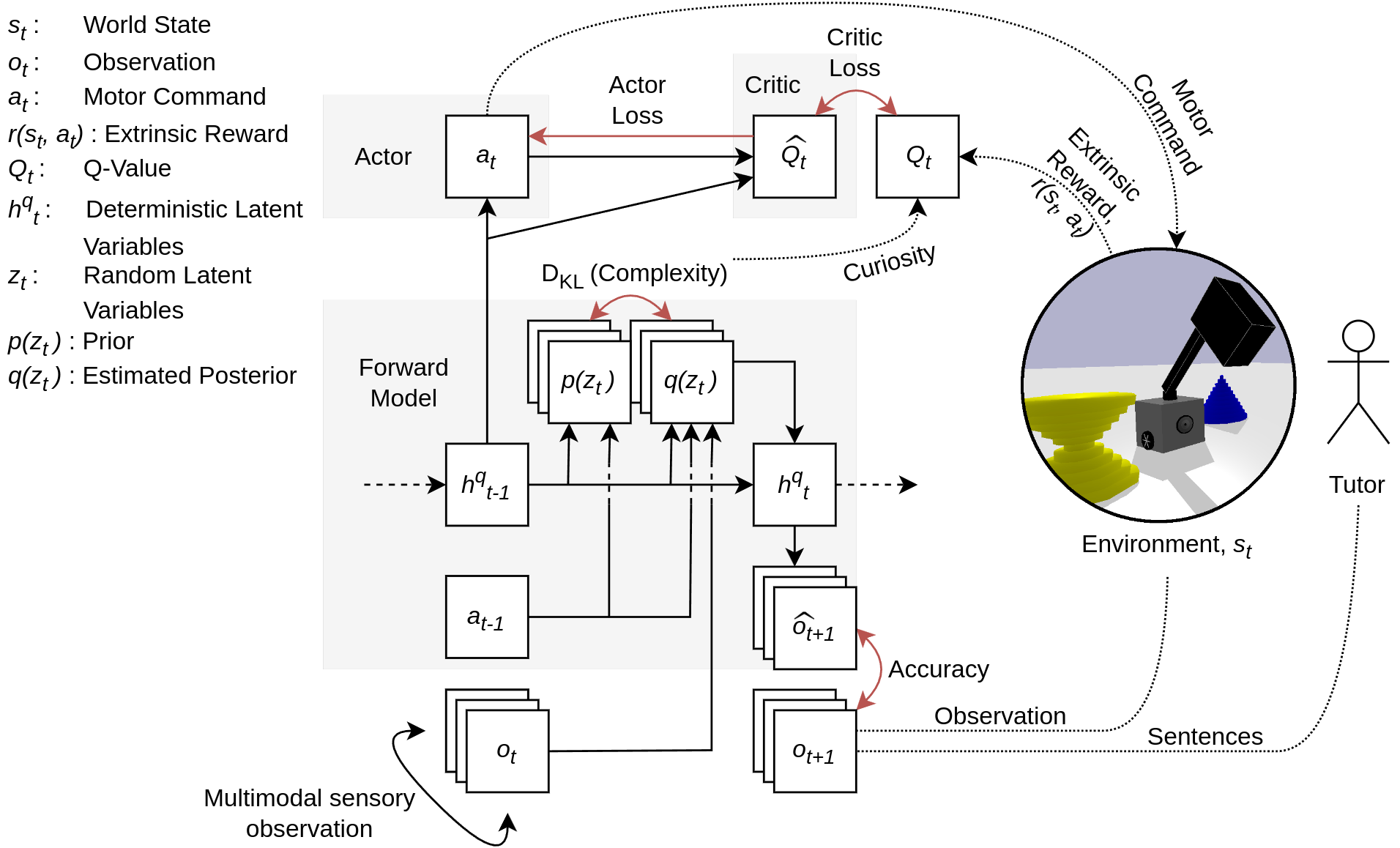


📊 实验亮点
实验结果表明,随着组合元素规模的增加,泛化能力显著提高。好奇心驱动的自我探索能够有效提高学习效率。此外,该模型还模拟了人类语言学习中的一些典型现象,如句子和动作的机械配对先于组合泛化,以及异常处理引起的U型发展性能。
🎯 应用场景
该研究成果可应用于开发更智能、更自主的机器人系统,使其能够在复杂环境中学习和执行各种任务。例如,可用于家庭服务机器人、工业机器人、医疗机器人等,使其能够理解人类指令并完成相应的操作。此外,该研究对于理解人类语言学习机制也具有重要意义。
📄 摘要(原文)
Infants acquire language with generalization from minimal experience, whereas large language models require billions of training tokens. What underlies efficient development in humans? We investigated this problem through experiments wherein robotic agents learn to perform actions associated with imperative sentences (e.g., push red cube) via curiosity-driven self-exploration. Our approach integrates active inference with reinforcement learning, enabling intrinsically motivated developmental learning. The simulations reveal key findings corresponding to observations in developmental psychology. i) Generalization improves drastically as the scale of compositional elements increases. ii) Curiosity improves learning through self-exploration. iii) Rote pairing of sentences and actions precedes compositional generalization. iv) Simpler actions develop before complex actions depending on them. v) Exception-handling induces U-shaped developmental performance, a pattern like representational redescription in child language learning. These results suggest that curiosity-driven active inference accounts for how intrinsically motivated sensorimotor-linguistic learning supports scalable compositional generalization and exception handling in humans and artificial agents.