Learning on the Job: Test-Time Curricula for Targeted Reinforcement Learning
作者: Jonas Hübotter, Leander Diaz-Bone, Ido Hakimi, Andreas Krause, Moritz Hardt
分类: cs.LG, cs.AI
发布日期: 2025-10-06
💡 一句话要点
提出测试时课程强化学习(TTC-RL),解决模型在特定任务上的持续学习问题。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 强化学习 持续学习 课程学习 测试时学习 任务适应 自动化课程构建 Qwen3-8B 代码生成
📋 核心要点
- 现有模型在面对特定任务时,缺乏持续学习和适应能力,难以充分利用已有数据。
- TTC-RL通过自动构建任务相关的课程,并利用强化学习持续训练模型,提升其在目标任务上的表现。
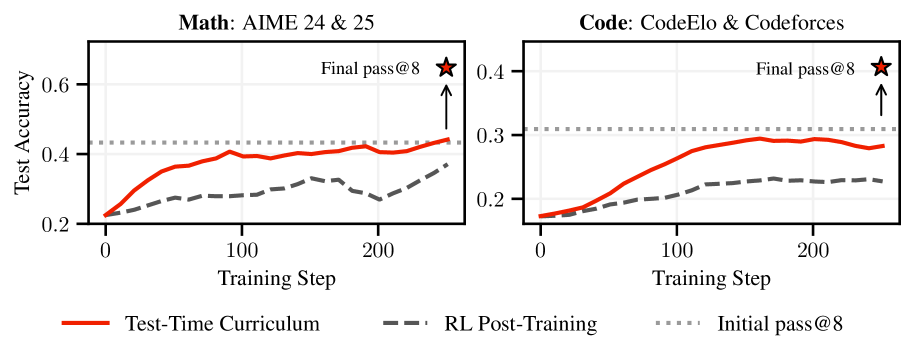
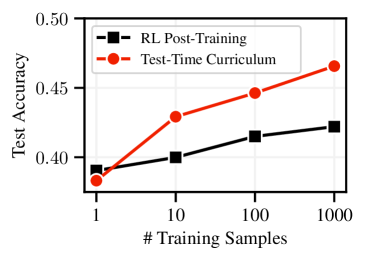
- 实验表明,TTC-RL在数学和编程任务上显著提升了模型性能,提高了pass@k指标,并突破了性能上限。
📝 摘要(中文)
本文提出了一种名为测试时课程强化学习(TTC-RL)的智能体,该智能体能够构建特定于任务的课程,并应用强化学习来持续训练模型以完成目标任务。测试时课程通过自动从大量可用训练数据中选择与任务最相关的数据,避免了耗时的人工数据集管理。实验结果表明,在各种评估和模型中,测试时课程强化学习始终能够提高模型在目标任务上的性能。值得注意的是,在具有挑战性的数学和编码基准测试中,TTC-RL将Qwen3-8B在AIME25上的pass@1提高了约1.8倍,在CodeElo上提高了2.1倍。此外,研究发现TTC-RL显著提高了性能上限,将AIME25上的pass@8从40%提高到62%,将CodeElo上的pass@8从28%提高到43%。这些发现表明,测试时课程具有将测试时扩展范式扩展到测试时数千次任务相关经验的持续训练的潜力。
🔬 方法详解
问题定义:论文旨在解决模型在测试阶段如何持续学习并提升特定任务性能的问题。现有方法通常依赖于预训练模型和固定的数据集,无法根据实际任务动态调整训练策略,导致模型在特定任务上的表现受限。人工构建数据集耗时耗力,且难以覆盖所有可能的任务场景。
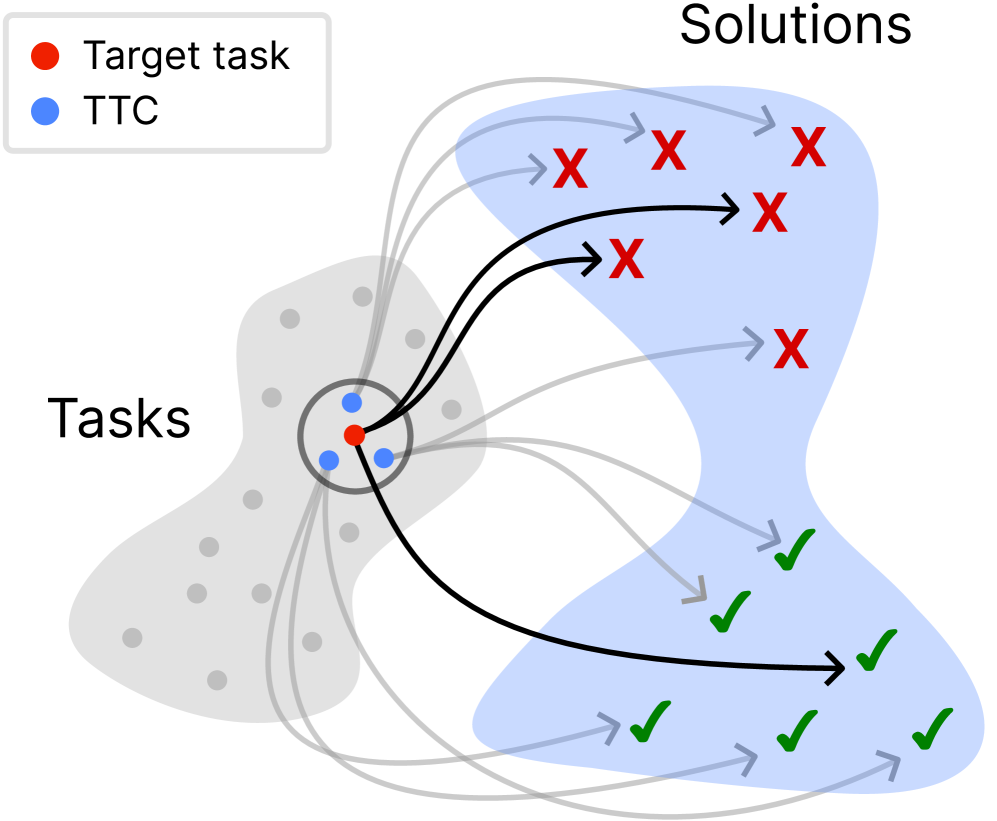
核心思路:论文的核心思路是利用强化学习自动构建一个针对特定任务的课程(Test-Time Curriculum)。该课程选择与当前任务最相关的训练数据,并利用这些数据对模型进行持续训练,从而使模型能够更好地适应目标任务。这种方法避免了人工干预,并能够根据任务的实际情况动态调整训练策略。
技术框架:TTC-RL的整体框架包含以下几个主要模块:1) 数据池:包含大量可用的训练数据。2) 课程选择器:使用强化学习智能体从数据池中选择与当前任务最相关的数据,构建课程。3) 模型训练器:使用选择的课程数据对模型进行持续训练。4) 奖励函数:根据模型在目标任务上的表现,为课程选择器提供奖励信号,指导其选择更有效的课程。整个流程是一个循环迭代的过程,课程选择器不断优化课程,模型不断提升性能。
关键创新:最重要的技术创新点在于将强化学习应用于课程选择,实现了自动化的任务特定课程构建。与传统的静态数据集或人工设计的课程相比,TTC-RL能够根据模型的实际表现动态调整课程,从而更有效地提升模型性能。这种方法将测试时学习与课程学习相结合,充分利用了测试阶段的反馈信息。
关键设计:课程选择器通常使用一个强化学习智能体,例如Q-learning或Policy Gradient方法。奖励函数的设计至关重要,需要能够准确反映模型在目标任务上的表现。例如,在代码生成任务中,可以使用pass@k指标作为奖励信号。数据池的选择也需要仔细考虑,需要包含足够多样化的数据,以便课程选择器能够找到与目标任务相关的数据。
🖼️ 关键图片
📊 实验亮点
实验结果表明,TTC-RL在数学和编程任务上取得了显著的性能提升。在AIME25数据集上,TTC-RL将Qwen3-8B的pass@1提高了约1.8倍,pass@8从40%提高到62%。在CodeElo数据集上,pass@1提高了2.1倍,pass@8从28%提高到43%。这些结果表明,TTC-RL能够有效地提升模型在特定任务上的性能,并突破了模型的性能上限。
🎯 应用场景
TTC-RL可应用于各种需要模型在特定任务上持续学习和优化的场景,例如:个性化推荐系统、智能客服、自动驾驶、机器人控制等。通过自动构建任务相关的课程,TTC-RL能够使模型更好地适应用户的需求和环境变化,从而提供更优质的服务和更高效的解决方案。该方法还可以用于提升预训练模型在特定领域的性能,降低模型部署和维护的成本。
📄 摘要(原文)
Humans are good at learning on the job: We learn how to solve the tasks we face as we go along. Can a model do the same? We propose an agent that assembles a task-specific curriculum, called test-time curriculum (TTC-RL), and applies reinforcement learning to continue training the model for its target task. The test-time curriculum avoids time-consuming human curation of datasets by automatically selecting the most task-relevant data from a large pool of available training data. Our experiments demonstrate that reinforcement learning on a test-time curriculum consistently improves the model on its target tasks, across a variety of evaluations and models. Notably, on challenging math and coding benchmarks, TTC-RL improves the pass@1 of Qwen3-8B by approximately 1.8x on AIME25 and 2.1x on CodeElo. Moreover, we find that TTC-RL significantly raises the performance ceiling compared to the initial model, increasing pass@8 on AIME25 from 40% to 62% and on CodeElo from 28% to 43%. Our findings show the potential of test-time curricula in extending the test-time scaling paradigm to continual training on thousands of task-relevant experiences during test-time.