Distribution Preference Optimization: A Fine-grained Perspective for LLM Unlearning
作者: Kai Qin, Jiaqi Wu, Jianxiang He, Haoyuan Sun, Yifei Zhao, Bin Liang, Yongzhe Chang, Tiantian Zhang, Houde Liu
分类: cs.LG, cs.AI
发布日期: 2025-10-06
备注: 20 pages
💡 一句话要点
提出DiPO:一种基于分布偏好优化的LLM非学习方法,提升遗忘质量和模型效用。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: LLM非学习 分布偏好优化 数据隐私 模型安全 遗忘质量 模型效用 logits操作
📋 核心要点
- 现有基于优化的LLM非学习方法,如NPO,缺乏显式的正偏好信号,限制了其遗忘效果。
- DiPO通过直接优化下一个token的概率分布,构建偏好分布对,克服了NPO的局限性。
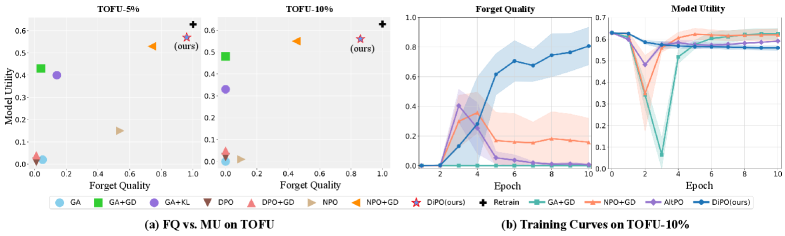
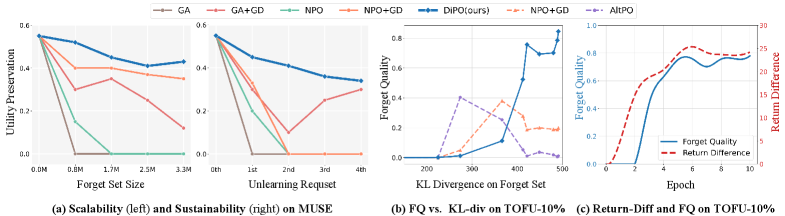
- 实验表明,DiPO在遗忘质量和模型效用之间取得了良好平衡,并在TOFU和MUSE基准上表现出色。
📝 摘要(中文)
随着大型语言模型(LLMs)从海量语料库中学习到卓越能力,数据隐私和安全问题日益受到关注。LLM非学习旨在消除特定数据的影响,同时保持模型的整体效用,正成为一个重要的研究领域。主流的非学习方法之一是基于优化的方法,通过微调直接实现遗忘,例如负偏好优化(NPO)。然而,NPO的有效性受到其缺乏显式正偏好信号的限制。通过构建首选响应来引入此类信号的尝试通常需要特定领域的知识或精心设计的提示,从根本上限制了它们的泛化性。在本文中,我们将重点转移到分布层面,直接针对下一个token的概率分布,而不是整个响应,并推导出一种新的非学习算法,称为分布偏好优化(DiPO)。我们表明,DiPO所需的偏好分布对(即模型输出token的分布)可以通过选择性地放大或抑制模型的高置信度输出logits来构建,从而有效地克服NPO的局限性。我们从理论上证明了DiPO的损失函数与期望的非学习方向的一致性。大量的实验表明,DiPO在模型效用和遗忘质量之间取得了很好的平衡。值得注意的是,DiPO在TOFU基准测试中获得了最高的遗忘质量,并在MUSE基准测试中保持了领先的可扩展性和效用保持能力。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLMs)的非学习问题,即如何在移除特定数据影响的同时,保持模型的整体性能。现有基于优化的方法,如负偏好优化(NPO),主要通过负样本进行微调,缺乏正向引导,导致遗忘效果不佳,且依赖领域知识或复杂prompt工程。
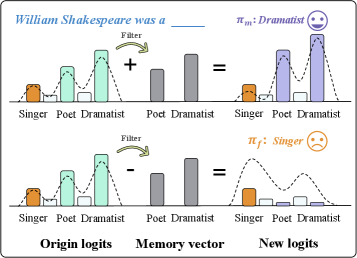
核心思路:DiPO的核心思路是将非学习过程聚焦于模型输出的概率分布层面,而非整个文本响应。通过直接操纵模型对下一个token的预测概率,构建正负偏好分布对,引导模型遗忘目标信息。这种方法避免了对特定领域知识的依赖,提高了泛化能力。
技术框架:DiPO的整体框架包括以下步骤:1)确定需要遗忘的目标数据;2)利用原始模型生成目标数据的输出概率分布;3)通过放大或抑制高置信度logits,构建正负偏好分布对;4)使用DiPO损失函数对模型进行微调,使模型倾向于负偏好分布,从而实现遗忘。
关键创新:DiPO的关键创新在于将非学习目标从整个文本响应转移到下一个token的概率分布。通过直接操纵logits,可以更精细地控制模型的输出,实现更有效的遗忘。此外,DiPO避免了对领域知识的依赖,提高了方法的通用性。
关键设计:DiPO的关键设计包括:1)偏好分布的构建方式:通过对原始模型输出的logits进行缩放,生成正负偏好分布。具体来说,正偏好分布可以通过放大高置信度logits得到,负偏好分布可以通过抑制高置信度logits得到。2)DiPO损失函数:该损失函数旨在最小化模型预测分布与负偏好分布之间的差异,同时最大化与正偏好分布之间的差异。损失函数的具体形式未知,但目标是引导模型远离目标数据的影响。
🖼️ 关键图片
📊 实验亮点
DiPO在TOFU基准测试中取得了最高的遗忘质量,表明其能够有效移除目标数据的影响。同时,在MUSE基准测试中,DiPO保持了领先的可扩展性和效用保持能力,证明其在实现有效遗忘的同时,能够最大程度地保留模型的通用能力。具体性能数据未知,但结果表明DiPO优于现有方法。
🎯 应用场景
DiPO在数据隐私保护、模型安全和版权保护等领域具有广泛的应用前景。例如,可以用于移除LLM中包含的个人身份信息(PII)或有害内容,确保模型符合法规要求。此外,DiPO还可以用于保护知识产权,防止模型泄露商业机密或专有信息。该研究对提升LLM的可控性和安全性具有重要意义。
📄 摘要(原文)
As Large Language Models (LLMs) demonstrate remarkable capabilities learned from vast corpora, concerns regarding data privacy and safety are receiving increasing attention. LLM unlearning, which aims to remove the influence of specific data while preserving overall model utility, is becoming an important research area. One of the mainstream unlearning classes is optimization-based methods, which achieve forgetting directly through fine-tuning, exemplified by Negative Preference Optimization (NPO). However, NPO's effectiveness is limited by its inherent lack of explicit positive preference signals. Attempts to introduce such signals by constructing preferred responses often necessitate domain-specific knowledge or well-designed prompts, fundamentally restricting their generalizability. In this paper, we shift the focus to the distribution-level, directly targeting the next-token probability distribution instead of entire responses, and derive a novel unlearning algorithm termed \textbf{Di}stribution \textbf{P}reference \textbf{O}ptimization (DiPO). We show that the requisite preference distribution pairs for DiPO, which are distributions over the model's output tokens, can be constructed by selectively amplifying or suppressing the model's high-confidence output logits, thereby effectively overcoming NPO's limitations. We theoretically prove the consistency of DiPO's loss function with the desired unlearning direction. Extensive experiments demonstrate that DiPO achieves a strong trade-off between model utility and forget quality. Notably, DiPO attains the highest forget quality on the TOFU benchmark, and maintains leading scalability and sustainability in utility preservation on the MUSE benchmark.