ViTs: Teaching Machines to See Time Series Anomalies Like Human Experts
作者: Zexin Wang, Changhua Pei, Yang Liu, Hengyue Jiang, Quan Zhou, Haotian Si, Hang Cui, Jianhui Li, Gaogang Xie, Jingjing Li, Dan Pei
分类: cs.LG
发布日期: 2025-10-06
备注: 13 pages
💡 一句话要点
ViTs:提出基于视觉-语言模型的时序异常检测框架,解决零样本泛化和变长序列处理难题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 时间序列异常检测 视觉-语言模型 零样本学习 变长序列处理 进化算法 知识注入 图像表示
📋 核心要点
- 现有时间序列异常检测模型难以实现“一次训练,跨场景推理”,且对变长序列的处理能力有限,通常依赖固定长度的滑动窗口。
- ViTs将时间序列转换为视觉表示,利用视觉-语言模型处理,通过图像缩放保持时间依赖性,从而支持任意长度序列的异常检测。
- ViTs采用进化算法生成高质量图像-文本对,并设计三阶段训练流程,实验证明其显著提升了VLM对时序数据异常的理解和检测能力。
📝 摘要(中文)
Web服务管理员必须通过及时检测关键性能指标(KPI)中的异常来确保多个系统的稳定性。“一次训练,跨场景推理”仍然是时间序列异常检测模型面临的一个根本挑战。除了提高零样本泛化能力外,此类模型还必须灵活地处理推理过程中不同长度的序列,从一小时到一周,而无需重新训练。传统方法依赖于滑动窗口编码和自监督学习,这限制了推理到固定长度的输入。大型语言模型(LLM)在通用领域表现出了卓越的零样本能力。然而,当应用于时间序列数据时,由于上下文长度的限制,它们面临着固有的局限性。为了解决这个问题,我们提出了ViTs,一个基于视觉-语言模型(VLM)的框架,它将时间序列曲线转换为视觉表示。通过重新缩放时间序列图像,可以保持时间依赖性,同时保持一致的输入大小,从而能够有效地处理任意长度的序列,而没有上下文约束。为此目的训练VLM引入了独特的挑战,主要是由于缺乏对齐的时间序列图像-文本数据。为了克服这个问题,我们采用了一种进化算法来自动生成数千个高质量的图像-文本对,并设计了一个三阶段的训练流程,包括:(1)时间序列知识注入,(2)异常检测增强,以及(3)异常推理细化。大量的实验表明,ViTs大大提高了VLM理解和检测时间序列数据中异常的能力。所有数据集和代码将在以下网址公开发布:https://anonymous.4open.science/r/ViTs-C484/。
🔬 方法详解
问题定义:论文旨在解决时间序列异常检测中零样本泛化能力不足和无法处理变长序列的问题。现有方法如滑动窗口编码和自监督学习,限制了模型只能处理固定长度的输入,无法满足实际应用中序列长度变化的需求。
核心思路:论文的核心思路是将时间序列数据转换为视觉图像,然后利用视觉-语言模型(VLM)进行处理。通过将时间序列曲线转化为图像,并进行缩放,可以在保持时间依赖性的同时,将任意长度的序列转换为统一大小的输入,从而克服了传统方法对固定长度输入的限制。
技术框架:ViTs框架包含三个主要阶段:1) 时间序列知识注入:使用进化算法自动生成高质量的时间序列图像-文本对,用于预训练VLM,使其具备初步的时间序列理解能力。2) 异常检测增强:进一步训练VLM,使其专注于异常检测任务,例如通过对比学习等方法,区分正常和异常的时间序列图像。3) 异常推理细化:对VLM进行微调,使其能够进行更精细的异常推理,例如定位异常发生的时间点或解释异常的原因。
关键创新:最重要的创新点在于将时间序列异常检测问题转化为视觉-语言任务,并利用VLM的强大能力进行处理。通过图像表示,ViTs能够处理任意长度的时间序列,并具备较强的零样本泛化能力。此外,自动生成图像-文本对的方法也解决了训练数据不足的问题。
关键设计:ViTs的关键设计包括:1) 使用进化算法生成图像-文本对,保证数据质量和多样性。2) 三阶段训练流程,逐步提升VLM的时间序列理解和异常检测能力。3) 时间序列图像的缩放策略,保证时间依赖性的同时,统一输入大小。具体的网络结构和损失函数选择取决于所使用的VLM模型,例如可以使用CLIP等预训练模型。
🖼️ 关键图片

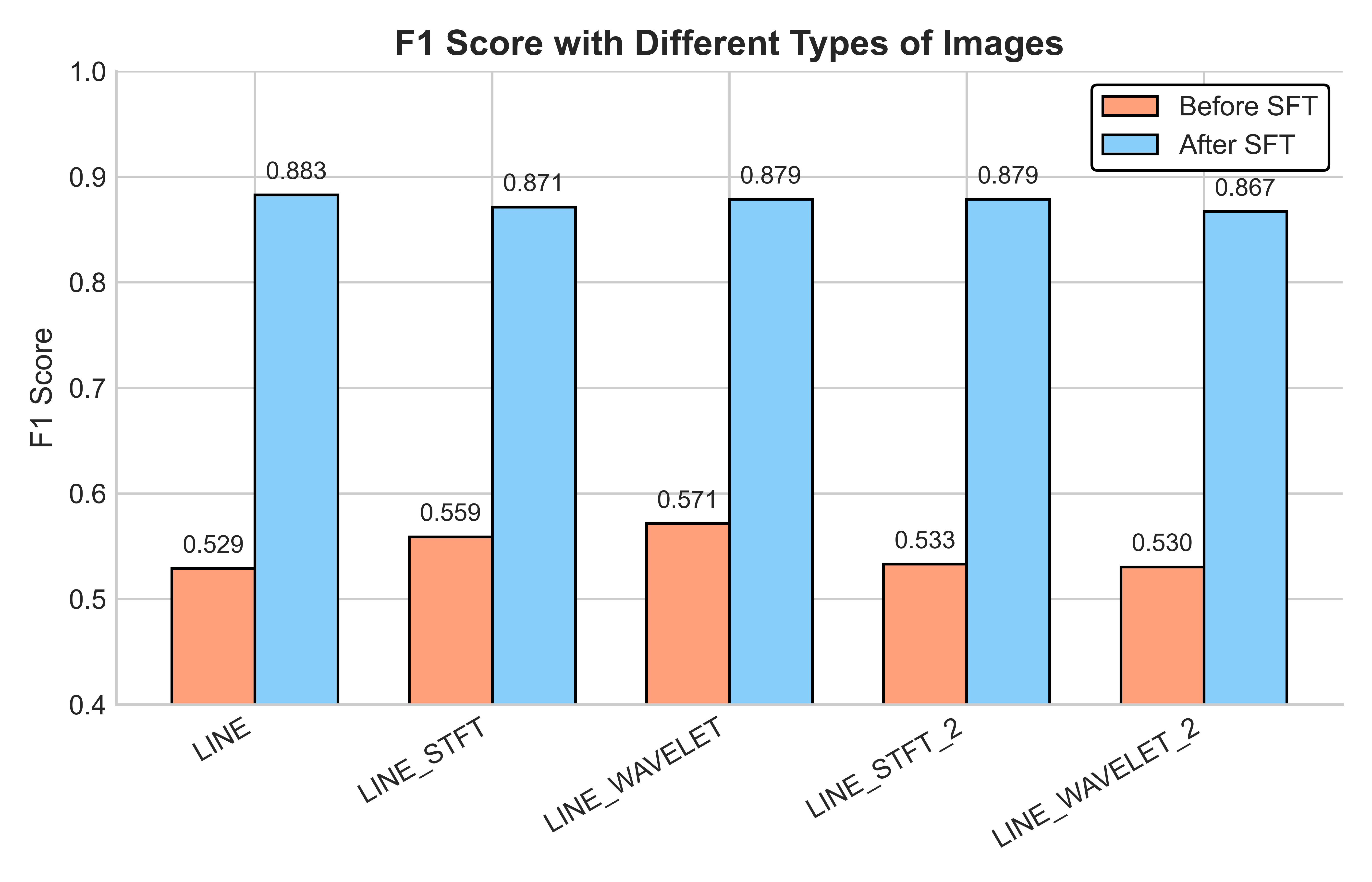

📊 实验亮点
论文通过大量实验验证了ViTs的有效性,证明其显著提升了VLM对时间序列异常的理解和检测能力。具体的性能数据(如准确率、召回率、F1值等)和对比基线(如传统的时间序列异常检测算法、直接使用LLM等)将在论文中详细给出。实验结果表明,ViTs在零样本泛化和变长序列处理方面均优于现有方法。
🎯 应用场景
ViTs可应用于Web服务监控、金融风险预警、工业设备故障诊断等领域。通过一次训练,即可在不同场景下检测各种长度的时间序列异常,降低了部署和维护成本,提高了系统的稳定性和可靠性。该研究为时间序列分析提供了一种新的思路,具有广阔的应用前景。
📄 摘要(原文)
Web service administrators must ensure the stability of multiple systems by promptly detecting anomalies in Key Performance Indicators (KPIs). Achieving the goal of "train once, infer across scenarios" remains a fundamental challenge for time series anomaly detection models. Beyond improving zero-shot generalization, such models must also flexibly handle sequences of varying lengths during inference, ranging from one hour to one week, without retraining. Conventional approaches rely on sliding-window encoding and self-supervised learning, which restrict inference to fixed-length inputs. Large Language Models (LLMs) have demonstrated remarkable zero-shot capabilities across general domains. However, when applied to time series data, they face inherent limitations due to context length. To address this issue, we propose ViTs, a Vision-Language Model (VLM)-based framework that converts time series curves into visual representations. By rescaling time series images, temporal dependencies are preserved while maintaining a consistent input size, thereby enabling efficient processing of arbitrarily long sequences without context constraints. Training VLMs for this purpose introduces unique challenges, primarily due to the scarcity of aligned time series image-text data. To overcome this, we employ an evolutionary algorithm to automatically generate thousands of high-quality image-text pairs and design a three-stage training pipeline consisting of: (1) time series knowledge injection, (2) anomaly detection enhancement, and (3) anomaly reasoning refinement. Extensive experiments demonstrate that ViTs substantially enhance the ability of VLMs to understand and detect anomalies in time series data. All datasets and code will be publicly released at: https://anonymous.4open.science/r/ViTs-C484/.