DoRAN: Stabilizing Weight-Decomposed Low-Rank Adaptation via Noise Injection and Auxiliary Networks
作者: Nghiem T. Diep, Hien Dang, Tuan Truong, Tan Dinh, Huy Nguyen, Nhat Ho
分类: cs.LG, cs.CV
发布日期: 2025-10-05
备注: Nghiem T. Diep, Hien Dang, and Tuan Truong contributed equally to this work
💡 一句话要点
DoRAN:通过噪声注入和辅助网络稳定权重分解低秩适应
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 参数高效微调 低秩适应 权重分解 噪声注入 辅助网络 模型稳定 样本效率
📋 核心要点
- 现有PEFT方法,如LoRA,在训练稳定性和学习能力上存在局限性,尤其是在大规模模型微调时。
- DoRAN通过在DoRA的权重分解中引入噪声注入和辅助网络,实现自适应正则化和跨层参数耦合,从而提升训练稳定性和样本效率。
- 实验结果表明,DoRAN在视觉和语言任务上显著优于LoRA、DoRA等基线方法,验证了其有效性。
📝 摘要(中文)
参数高效微调(PEFT)方法已成为适配大规模模型的标准范式。在这些技术中,权重分解低秩适应(DoRA)通过将预训练权重显式分解为幅度和方向分量,已被证明可以提高原始低秩适应(LoRA)方法的学习能力和训练稳定性。本文提出DoRAN,一种DoRA的新变体,旨在进一步稳定训练并提高DoRA的样本效率。我们的方法包括两个关键阶段:(i)将噪声注入到DoRA权重分解的分母中,作为一种自适应正则化器,以减轻不稳定性;(ii)用动态生成低秩矩阵的辅助网络替换静态低秩矩阵,从而实现跨层的参数耦合,并在理论和实践中产生更好的样本效率。在视觉和语言基准上的综合实验表明,DoRAN始终优于LoRA、DoRA和其他PEFT基线。这些结果强调了通过基于噪声的正则化进行稳定与基于网络的参数生成相结合的有效性,为基础模型的稳健和高效微调提供了一个有希望的方向。
🔬 方法详解
问题定义:论文旨在解决权重分解低秩适应(DoRA)在训练过程中可能出现的不稳定问题,以及样本效率相对较低的问题。现有的DoRA方法虽然相较于LoRA有所改进,但在某些情况下仍然存在训练波动,并且参数利用率有待提高。
核心思路:DoRAN的核心思路是通过两个关键机制来稳定训练并提高样本效率:一是通过噪声注入实现自适应正则化,二是通过辅助网络动态生成低秩矩阵,实现跨层参数耦合。噪声注入可以平滑损失函数,辅助网络则可以更好地利用参数,从而提高模型的泛化能力。
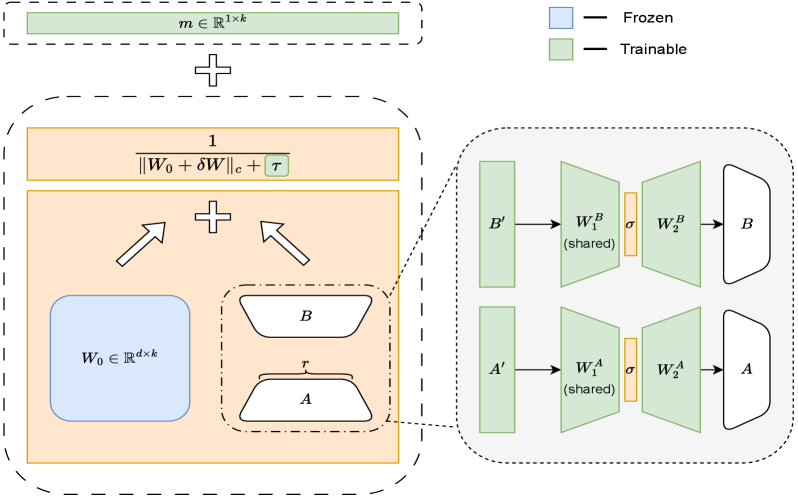
技术框架:DoRAN方法主要包含两个阶段:首先,在DoRA的权重分解过程中,对分母项注入噪声,这相当于一个自适应的正则化项。其次,将DoRA中静态的低秩矩阵替换为辅助网络,这些网络可以动态地生成低秩矩阵,从而实现跨层的参数共享和耦合。整体流程是在预训练模型的基础上,使用DoRAN进行微调,以适应特定任务。
关键创新:DoRAN的关键创新在于将噪声注入和辅助网络相结合,用于稳定DoRA的训练过程并提高样本效率。噪声注入提供了一种自适应的正则化方式,而辅助网络则允许参数在不同层之间共享信息,从而提高了参数的利用率。这种结合是现有PEFT方法所不具备的。
关键设计:在噪声注入方面,噪声的方差可以根据训练的进展进行调整,以实现更好的正则化效果。辅助网络可以使用简单的MLP结构,其输入可以是层索引或其他与层相关的信息。损失函数通常采用交叉熵损失或均方误差损失,具体取决于任务类型。关键在于如何设计辅助网络的输入和结构,使其能够有效地生成低秩矩阵。
🖼️ 关键图片
📊 实验亮点
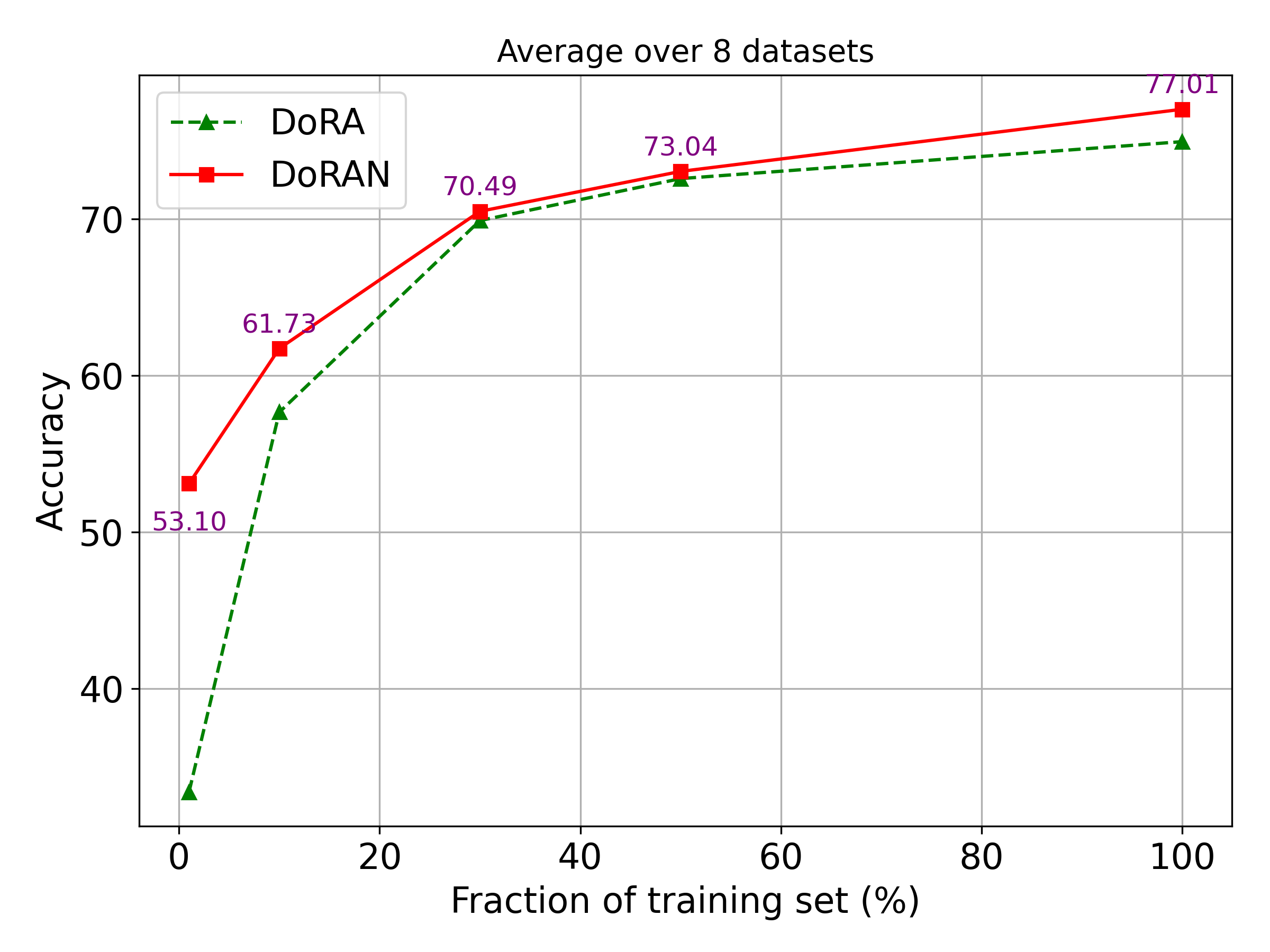
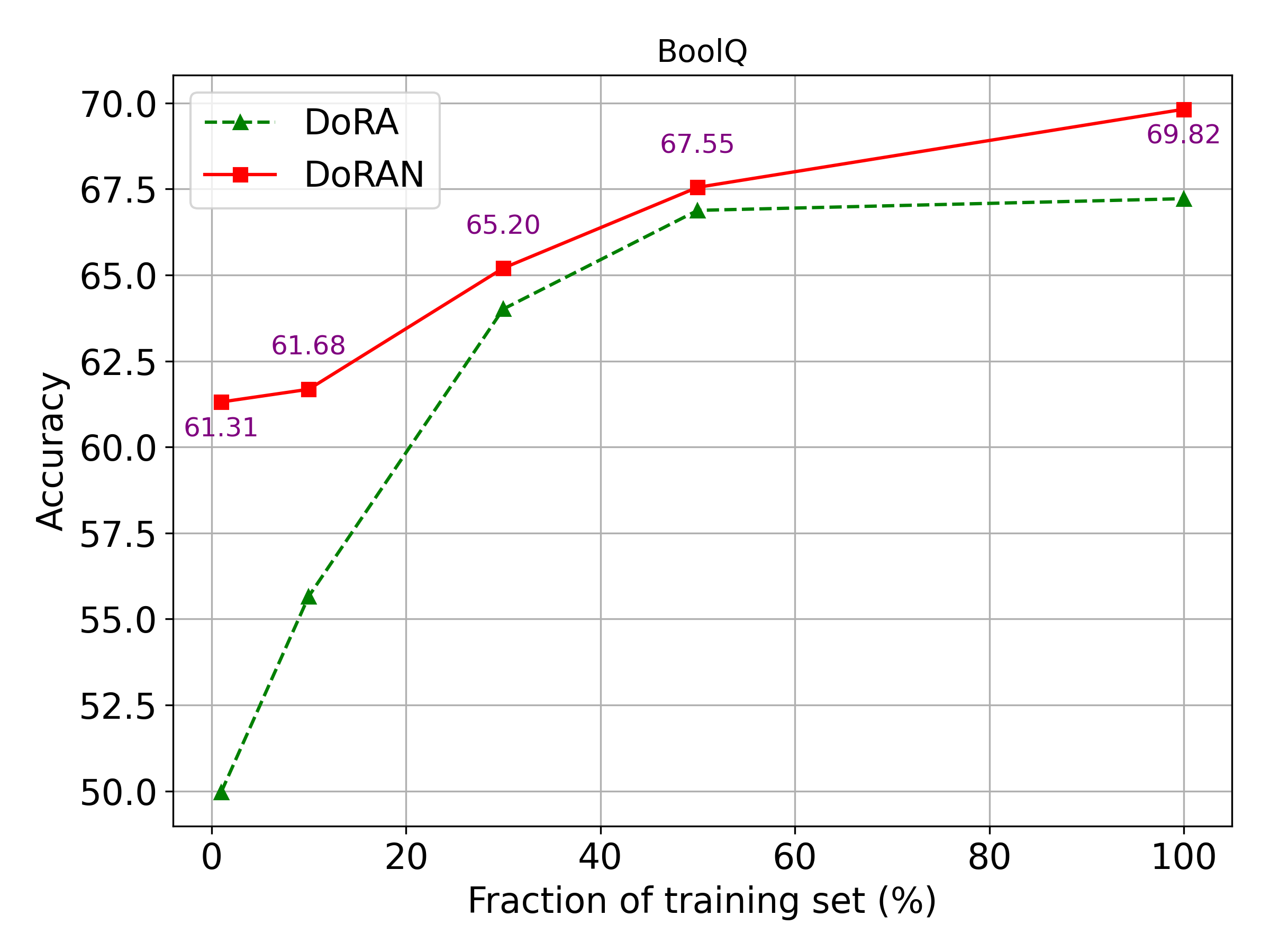
实验结果表明,DoRAN在多个视觉和语言基准测试中均优于LoRA、DoRA和其他PEFT基线。例如,在图像分类任务上,DoRAN相比DoRA取得了显著的性能提升,同时保持了较低的参数量。在自然语言处理任务上,DoRAN也展现出更快的收敛速度和更高的精度。
🎯 应用场景
DoRAN可应用于各种需要高效微调大型预训练模型的场景,例如自然语言处理中的文本分类、机器翻译,以及计算机视觉中的图像识别、目标检测等。该方法能够降低微调成本,提高模型在资源受限环境下的部署能力,并加速新任务的适配过程。未来,DoRAN有望成为一种通用的PEFT方法,广泛应用于各个领域。
📄 摘要(原文)
Parameter-efficient fine-tuning (PEFT) methods have become the standard paradigm for adapting large-scale models. Among these techniques, Weight-Decomposed Low-Rank Adaptation (DoRA) has been shown to improve both the learning capacity and training stability of the vanilla Low-Rank Adaptation (LoRA) method by explicitly decomposing pre-trained weights into magnitude and directional components. In this work, we propose DoRAN, a new variant of DoRA designed to further stabilize training and boost the sample efficiency of DoRA. Our approach includes two key stages: (i) injecting noise into the denominator of DoRA's weight decomposition, which serves as an adaptive regularizer to mitigate instabilities; and (ii) replacing static low-rank matrices with auxiliary networks that generate them dynamically, enabling parameter coupling across layers and yielding better sample efficiency in both theory and practice. Comprehensive experiments on vision and language benchmarks show that DoRAN consistently outperforms LoRA, DoRA, and other PEFT baselines. These results underscore the effectiveness of combining stabilization through noise-based regularization with network-based parameter generation, offering a promising direction for robust and efficient fine-tuning of foundation models.