Slow-Fast Policy Optimization: Reposition-Before-Update for LLM Reasoning
作者: Ziyan Wang, Zheng Wang, Jie Fu, Xingwei Qu, Qi Cheng, Shengpu Tang, Minjia Zhang, Xiaoming Huo
分类: cs.LG, cs.AI, cs.CL, stat.ML
发布日期: 2025-10-05 (更新: 2025-10-08)
💡 一句话要点
SFPO:面向LLM推理,通过重定位-更新机制提升强化学习训练效率与稳定性
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 强化学习 大型语言模型 策略优化 推理 重定位 稳定性 训练效率
📋 核心要点
- 现有基于强化学习的LLM推理方法,如GRPO,在训练初期受噪声梯度影响,导致更新不稳定和探索效率低下。
- SFPO通过短快速轨迹、重定位机制和慢速校正三个阶段,实现更稳定和高效的策略优化,同时保持与现有流程的兼容性。
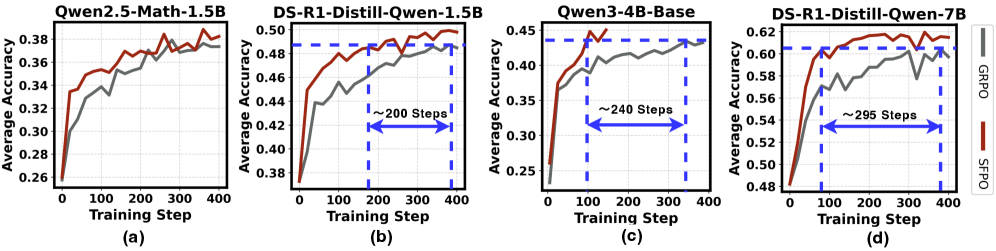
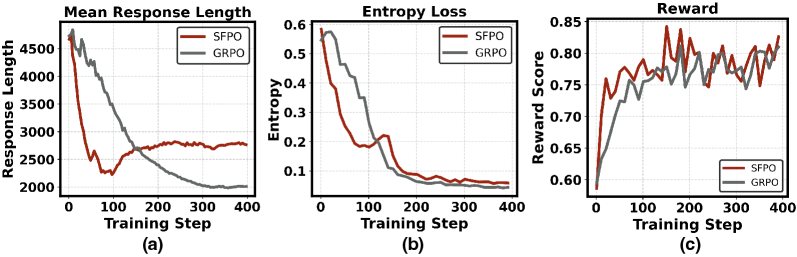
- 实验结果表明,SFPO在数学推理任务上显著优于GRPO,减少了rollout次数和训练时间,提升了训练效率。
📝 摘要(中文)
强化学习(RL)已成为增强大型语言模型(LLM)推理能力的关键。然而,诸如Group Relative Policy Optimization (GRPO)等on-policy算法在早期训练中常常表现不佳:来自低质量rollout的噪声梯度导致不稳定的更新和低效的探索。我们提出了Slow-Fast Policy Optimization (SFPO),一个简单而高效的框架,通过将每个步骤分解为三个阶段来解决这些限制:在同一批次上的短快速轨迹的内部步骤,控制off-policy漂移的重定位机制,以及最终的慢速校正。这种重定位-更新的设计保持了目标和rollout过程不变,使得SFPO可以与现有的策略梯度流程即插即用。大量的实验表明,SFPO能够持续提高推理RL训练的稳定性,减少rollout次数,并加速收敛。具体而言,在数学推理基准测试中,SFPO的平均性能比GRPO高出2.80个点。为了达到GRPO的最佳精度,SFPO的rollout次数最多减少了4.93倍,wall-clock时间最多减少了4.19倍。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)在强化学习(RL)训练中,由于早期rollout质量低导致梯度噪声大、训练不稳定、探索效率低下的问题。现有方法,如GRPO,在训练初期容易受到这些问题的影响,从而限制了LLM推理能力的提升。
核心思路:SFPO的核心思路是将每个训练步骤分解为“快-慢”两个阶段,并引入重定位机制。快速阶段在同一批次数据上进行多次内部更新,以加速学习;重定位机制用于控制快速阶段可能引入的off-policy漂移;慢速阶段进行最终的校正,以确保策略的稳定性。这种设计旨在平衡探索和利用,提高训练效率和稳定性。
技术框架:SFPO框架包含三个主要阶段:1) 快速轨迹(Fast Trajectory):在同一批次数据上执行多个内部策略更新步骤,以快速学习策略。2) 重定位(Reposition):使用重定位机制来控制由于快速轨迹导致的off-policy漂移,确保策略更新的稳定性。3) 慢速校正(Slow Correction):执行最终的策略更新步骤,以校正快速轨迹和重定位可能引入的误差。整个框架与现有的策略梯度流程兼容,可以即插即用。
关键创新:SFPO的关键创新在于其“重定位-更新”的设计。传统的策略优化方法通常直接使用rollout数据进行更新,容易受到噪声的影响。SFPO通过在更新前进行重定位,有效地控制了off-policy漂移,提高了训练的稳定性。此外,快慢阶段的设计允许在同一批次数据上进行多次更新,从而加速了学习过程。
关键设计:SFPO的关键设计包括:1) 内部更新步数:控制快速轨迹的长度,需要在加速学习和控制off-policy漂移之间进行权衡。2) 重定位机制:具体实现方式未知,但其目标是使策略回到一个更“安全”的状态,以避免过度探索。3) 学习率:需要针对快慢阶段进行调整,以平衡学习速度和稳定性。
🖼️ 关键图片

📊 实验亮点
实验结果表明,SFPO在数学推理基准测试中,平均性能比GRPO高出2.80个点。为了达到GRPO的最佳精度,SFPO的rollout次数最多减少了4.93倍,wall-clock时间最多减少了4.19倍。这些数据表明,SFPO在提高训练效率和稳定性方面具有显著优势。
🎯 应用场景
SFPO可应用于各种需要强化学习来提升LLM推理能力的场景,例如数学问题求解、代码生成、知识图谱推理等。该方法能够提高训练效率和稳定性,降低训练成本,并提升LLM在复杂推理任务中的性能。未来,SFPO有望被应用于更广泛的LLM训练和优化中,推动人工智能技术的发展。
📄 摘要(原文)
Reinforcement learning (RL) has become central to enhancing reasoning in large language models (LLMs). Yet on-policy algorithms such as Group Relative Policy Optimization (GRPO) often suffer in early training: noisy gradients from low-quality rollouts lead to unstable updates and inefficient exploration. We introduce Slow-Fast Policy Optimization (SFPO), a simple yet efficient framework to address these limitations via decomposing each step into three stages: a short fast trajectory of inner steps on the same batch, a reposition mechanism to control off-policy drift, and a final slow correction. This reposition-before-update design preserves the objective and rollout process unchanged, making SFPO plug-compatible with existing policy-gradient pipelines. Extensive experiments demonstrate that SFPO consistently improves stability, reduces rollouts, and accelerates convergence of reasoning RL training. Specifically, it outperforms GRPO by up to 2.80 points in average on math reasoning benchmarks. It also achieves up to 4.93\texttimes{} fewer rollouts and an up to 4.19\texttimes{} reduction in wall-clock time to match GRPO's best accuracy.