Simple Policy Gradients for Reasoning with Diffusion Language Models
作者: Anthony Zhan
分类: cs.LG, cs.AI, cs.CL
发布日期: 2025-10-05 (更新: 2026-02-01)
备注: 17 pages. Code at https://github.com/probablyabot/agrpo
💡 一句话要点
提出AGRPO算法,用于扩散语言模型推理的策略梯度优化
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 扩散语言模型 强化学习 策略梯度 后训练 推理 数学问题求解 序列生成
📋 核心要点
- 扩散语言模型缺乏有效的序列级似然性,难以应用强化学习进行后训练,限制了其在实际问题中的应用。
- AGRPO算法利用扩散语言模型生成过程的多步马尔可夫性质,优化每个去噪步骤的策略梯度,而非优化整个序列。
- 实验表明,AGRPO在数学和推理任务上显著提升了扩散语言模型的性能,并能加速推理过程。
📝 摘要(中文)
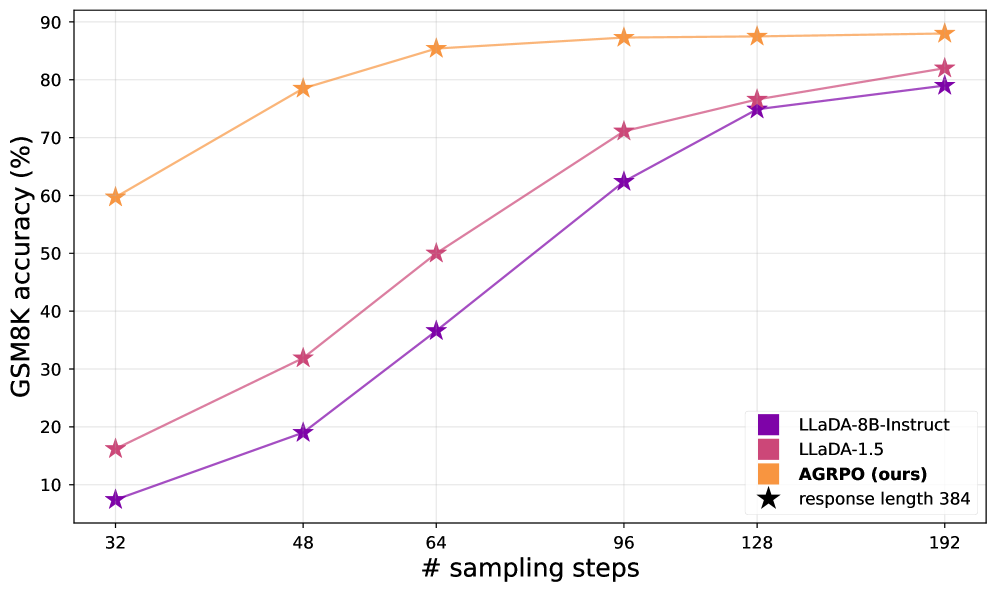
扩散大型语言模型(dLLMs)为传统自回归LLM提供了一种有前景的替代方案,并在预训练中表现出强大的结果。然而,由于缺乏易于处理的序列级似然性,它们尚未受益于现代LLM后训练技术,如强化学习(RL),限制了它们的实际应用。现有的dLLM后训练尝试依赖于启发式近似或真实似然的下界。本文提出了一种摊销分组相对策略优化(AGRPO)算法,该算法利用dLLM生成的多步马尔可夫性质,优化单个去噪步骤,而不是整个序列。我们在不同的数学和推理任务上证明了AGRPO的有效性,在GSM8K上实现了+9.9%的绝对增益,在MATH-500上实现了+4.6%,在Countdown上实现了+59.4%,在Sudoku上实现了+69.7%,超过了基础LLaDA模型,并改进了可比的dLLM RL方法,如diffu-GRPO。此外,我们分析了后训练增益如何在不同的推理配置中持续存在,表明使用AGRPO训练的模型可以更快地采样4倍,而性能牺牲最小。
🔬 方法详解
问题定义:论文旨在解决扩散语言模型(dLLMs)难以进行有效后训练的问题。由于dLLMs缺乏可追踪的序列级似然性,传统的强化学习方法难以直接应用,现有的后训练方法依赖于启发式近似或似然下界,效果有限。
核心思路:论文的核心思路是将整个序列的优化问题分解为多个独立的去噪步骤的优化问题。利用dLLM生成过程的马尔可夫性质,将策略梯度优化应用于每个去噪步骤,从而避免了对整个序列似然的直接计算。
技术框架:AGRPO算法的核心框架是基于策略梯度的强化学习。它将dLLM的每个去噪步骤视为一个独立的策略,并使用强化学习来优化每个策略。具体流程如下:1) 从dLLM中采样生成序列;2) 对每个去噪步骤,计算其对应的奖励;3) 使用策略梯度算法更新每个去噪步骤的策略。
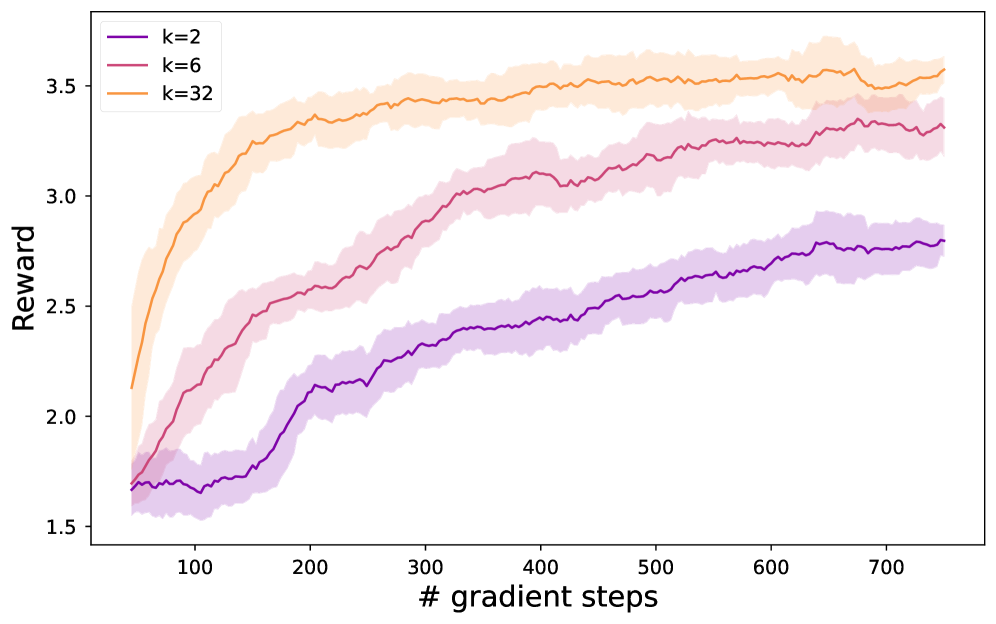
关键创新:AGRPO的关键创新在于将策略梯度优化应用于dLLM的每个去噪步骤,而不是整个序列。这种方法避免了对整个序列似然的直接计算,从而使得强化学习能够有效地应用于dLLMs的后训练。此外,AGRPO还采用了摊销分组相对策略优化,进一步提高了训练效率。
关键设计:AGRPO的关键设计包括:1) 奖励函数的设计,需要根据具体的任务进行调整,以反映生成序列的质量;2) 策略梯度算法的选择,可以选择常见的策略梯度算法,如REINFORCE或PPO;3) 摊销分组相对策略优化的具体实现,需要选择合适的分组策略和相对策略优化方法。
🖼️ 关键图片

📊 实验亮点
AGRPO在GSM8K上实现了+9.9%的绝对增益,在MATH-500上实现了+4.6%,在Countdown上实现了+59.4%,在Sudoku上实现了+69.7%,超过了基础LLaDA模型,并改进了可比的dLLM RL方法,如diffu-GRPO。此外,使用AGRPO训练的模型可以更快地采样4倍,而性能牺牲最小。
🎯 应用场景
该研究成果可应用于各种需要复杂推理和生成能力的场景,例如数学问题求解、代码生成、逻辑推理等。通过强化学习对扩散语言模型进行后训练,可以显著提高其在这些任务上的性能,使其更具实用价值。此外,该方法还可以加速扩散语言模型的推理过程,降低计算成本。
📄 摘要(原文)
Diffusion large language models (dLLMs), which offer a promising alternative to traditional autoregressive LLMs, have recently shown strong results in pretraining. However, due to their lack of tractable sequence-level likelihoods, they have yet to benefit from modern LLM post-training techniques such as reinforcement learning (RL), limiting their real-world applicability. Existing attempts at dLLM post-training rely on heuristic approximations or lower bounds of the true likelihood. In this work, we propose Amortized Group Relative Policy Optimization (AGRPO), a policy gradient algorithm that leverages the multi-step Markovian nature of dLLM generation, optimizing individual denoising steps rather than entire sequences. We demonstrate AGRPO's effectiveness on different math and reasoning tasks, achieving +9.9\% absolute gain on GSM8K, +4.6\% on MATH-500, +59.4\% on Countdown, and +69.7\% on Sudoku over the base LLaDA model, improving upon comparable dLLM RL methods such as diffu-GRPO. Furthermore, we analyze how post-training gains persist across different inference configurations, revealing that models trained with AGRPO can sample 4x faster with minimal performance sacrifices.