Distributed Area Coverage with High Altitude Balloons Using Multi-Agent Reinforcement Learning
作者: Adam Haroon, Tristan Schuler
分类: cs.LG, cs.MA, cs.RO
发布日期: 2025-10-04
💡 一句话要点
提出基于多智能体强化学习的高空气球分布式区域覆盖方法
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 多智能体强化学习 高空气球 分布式区域覆盖 协同控制 QMIX
📋 核心要点
- 现有高空气球协同方法在小型团队和局部任务中表现不佳,缺乏对复杂环境的适应性。
- 利用多智能体强化学习,通过集中训练分散执行的模式,实现高空气球的协同区域覆盖。
- 实验表明,所提出的QMIX方法能够达到与理论最优的确定性方法相近的性能,验证了MARL的有效性。
📝 摘要(中文)
本文首次将多智能体强化学习(MARL)应用于高空气球(HAB)的协同控制,以实现分布式区域覆盖。针对小型团队和局部任务中现有基于Voronoi划分和极值搜索控制等确定性方法性能不佳的问题,本文扩展了先前开发的强化学习仿真环境(RLHAB),以支持合作多智能体学习,使多个智能体能够在真实大气条件下同时运行。本文采用QMIX算法进行HAB区域覆盖协同,利用集中式训练和分散式执行来应对大气车辆协同挑战。该方法采用专门的观测空间,提供个体状态、环境上下文和队友数据,并采用分层奖励,优先考虑覆盖范围,同时鼓励空间分布。实验结果表明,QMIX在分布式区域覆盖方面取得了与理论上最优的几何确定性方法相似的性能,验证了MARL方法,并为更复杂的自主多HAB任务奠定了基础。
🔬 方法详解
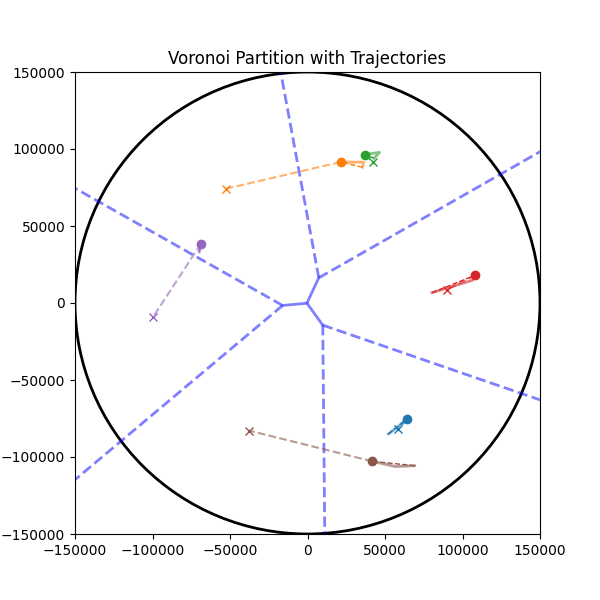
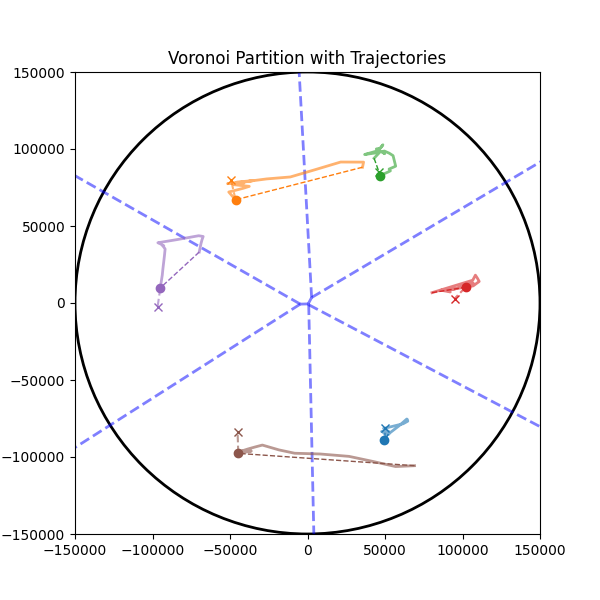
问题定义:论文旨在解决多个高空气球如何在复杂大气环境下协同完成指定区域的覆盖任务。现有确定性方法(如Voronoi划分和极值搜索控制)在气球数量较少或任务区域较小时性能下降,难以适应动态变化的环境,缺乏自主学习和优化能力。
核心思路:论文的核心思路是利用多智能体强化学习(MARL)的优势,通过让多个高空气球智能体在仿真环境中学习协同策略,从而实现高效的分布式区域覆盖。MARL能够处理复杂的状态空间和动作空间,并允许智能体之间进行通信和协作,从而更好地适应环境变化。
技术框架:整体框架基于集中式训练、分散式执行(CTDE)范式。在训练阶段,所有智能体共享全局信息,并由一个中央控制器进行策略优化。在执行阶段,每个智能体仅根据自身观测到的局部信息独立做出决策。具体流程包括:1)构建高空气球仿真环境RLHAB,模拟真实大气条件;2)设计智能体的观测空间,包括个体状态、环境上下文和队友数据;3)采用QMIX算法进行策略学习,该算法能够保证联合动作价值函数与个体动作价值函数的一致性;4)设计分层奖励函数,优先考虑覆盖范围,同时鼓励空间分布。
关键创新:最重要的技术创新点在于将MARL应用于高空气球协同控制,并针对该问题设计了专门的观测空间和奖励函数。与现有确定性方法相比,MARL方法具有更强的适应性和鲁棒性,能够处理更复杂的环境和任务。
关键设计:观测空间包括个体状态(位置、速度等)、环境上下文(风场信息等)和队友数据(位置等)。奖励函数采用分层结构,首先奖励覆盖区域的面积,然后奖励智能体之间的空间分布均匀性。QMIX算法中的混合网络采用多层感知机,输入为个体Q值和全局状态,输出为联合Q值。训练过程中,使用经验回放和目标网络来稳定学习过程。
🖼️ 关键图片

📊 实验亮点
实验结果表明,基于QMIX的MARL方法在分布式区域覆盖任务中取得了与理论最优的几何确定性方法相似的性能。这验证了MARL方法在高空气球协同控制中的有效性,并为更复杂的自主多HAB任务奠定了基础。具体而言,QMIX方法在覆盖率方面与确定性方法相当,但在适应动态环境和处理复杂任务方面具有更大的潜力。
🎯 应用场景
该研究成果可应用于多种场景,如侦察、环境监测和通信网络。通过自主协同控制多个高空气球,可以实现对大范围区域的持续监测和覆盖,提高任务效率和可靠性。未来,该技术还可扩展到其他类型的无人系统,如无人机和水下机器人,实现更复杂的协同任务。
📄 摘要(原文)
High Altitude Balloons (HABs) can leverage stratospheric wind layers for limited horizontal control, enabling applications in reconnaissance, environmental monitoring, and communications networks. Existing multi-agent HAB coordination approaches use deterministic methods like Voronoi partitioning and extremum seeking control for large global constellations, which perform poorly for smaller teams and localized missions. While single-agent HAB control using reinforcement learning has been demonstrated on HABs, coordinated multi-agent reinforcement learning (MARL) has not yet been investigated. This work presents the first systematic application of multi-agent reinforcement learning (MARL) to HAB coordination for distributed area coverage. We extend our previously developed reinforcement learning simulation environment (RLHAB) to support cooperative multi-agent learning, enabling multiple agents to operate simultaneously in realistic atmospheric conditions. We adapt QMIX for HAB area coverage coordination, leveraging Centralized Training with Decentralized Execution to address atmospheric vehicle coordination challenges. Our approach employs specialized observation spaces providing individual state, environmental context, and teammate data, with hierarchical rewards prioritizing coverage while encouraging spatial distribution. We demonstrate that QMIX achieves similar performance to the theoretically optimal geometric deterministic method for distributed area coverage, validating the MARL approach and providing a foundation for more complex autonomous multi-HAB missions where deterministic methods become intractable.