Optimizing Fine-Tuning through Advanced Initialization Strategies for Low-Rank Adaptation
作者: Yongfu Xue
分类: cs.LG, cs.CL
发布日期: 2025-10-04 (更新: 2026-01-14)
💡 一句话要点
提出IniLoRA,通过优化低秩适应的初始化策略提升微调性能
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 参数高效微调 低秩适应 LoRA 初始化策略 大型语言模型
📋 核心要点
- LoRA初始化低秩矩阵乘积为零,限制了对原始模型权重的有效利用,成为性能瓶颈。
- IniLoRA通过将低秩矩阵初始化为接近原始模型权重的值,来更有效地激活和利用原始模型。
- 实验表明,IniLoRA及其变体IniLoRA-$α$和IniLoRA-$β$在多个模型和任务上均优于LoRA。
📝 摘要(中文)
参数高效微调方法的快速发展显著提高了大型语言模型的适应效率。其中,LoRA因其在有效性和参数效率之间的强大平衡而广受欢迎。然而,LoRA依赖于初始化两个低秩矩阵,其乘积为零,这限制了其有效激活和利用原始模型权重的能力,从而为最佳性能创造了潜在的瓶颈。为了解决这个限制,我们提出了IniLoRA,一种新颖的初始化策略,它将低秩矩阵初始化为紧密近似原始模型权重。实验结果表明,IniLoRA在各种模型和任务中都优于LoRA。此外,我们还介绍了两个变体,IniLoRA-$α$和IniLoRA-$β$,两者都利用不同的初始化方法来进一步提高性能。
🔬 方法详解
问题定义:LoRA虽然参数高效,但其零初始化的低秩矩阵限制了对预训练模型权重的有效利用,导致微调性能受限。现有方法无法充分激活和利用预训练模型的知识,造成性能瓶颈。
核心思路:IniLoRA的核心思想是改变LoRA的初始化方式,不再使用零初始化,而是将低秩矩阵初始化为能够近似原始模型权重的状态。这样做的目的是为了在微调初期就能更好地利用预训练模型的知识,加速收敛并提升最终性能。
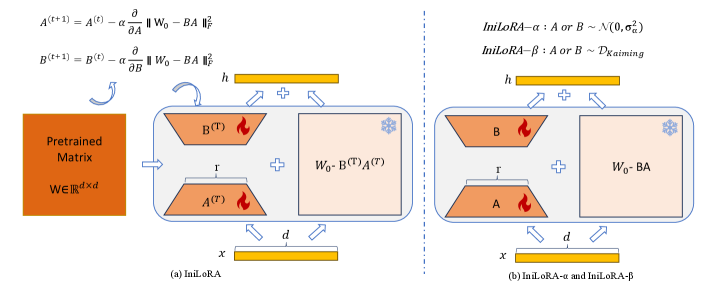
技术框架:IniLoRA沿用了LoRA的整体框架,即在原始预训练模型的基础上,添加两个低秩矩阵A和B。不同之处在于,IniLoRA修改了A和B的初始化方式。具体来说,IniLoRA首先计算一个目标矩阵,该矩阵是对原始模型权重的一种近似,然后根据这个目标矩阵来初始化A和B。IniLoRA-$α$和IniLoRA-$β$是两种不同的初始化策略,用于计算这个目标矩阵。
关键创新:IniLoRA的关键创新在于提出了非零初始化的低秩矩阵。与LoRA的零初始化相比,IniLoRA能够更有效地利用预训练模型的知识,从而提升微调性能。IniLoRA-$α$和IniLoRA-$β$则是在此基础上,探索了不同的初始化策略,进一步优化了性能。
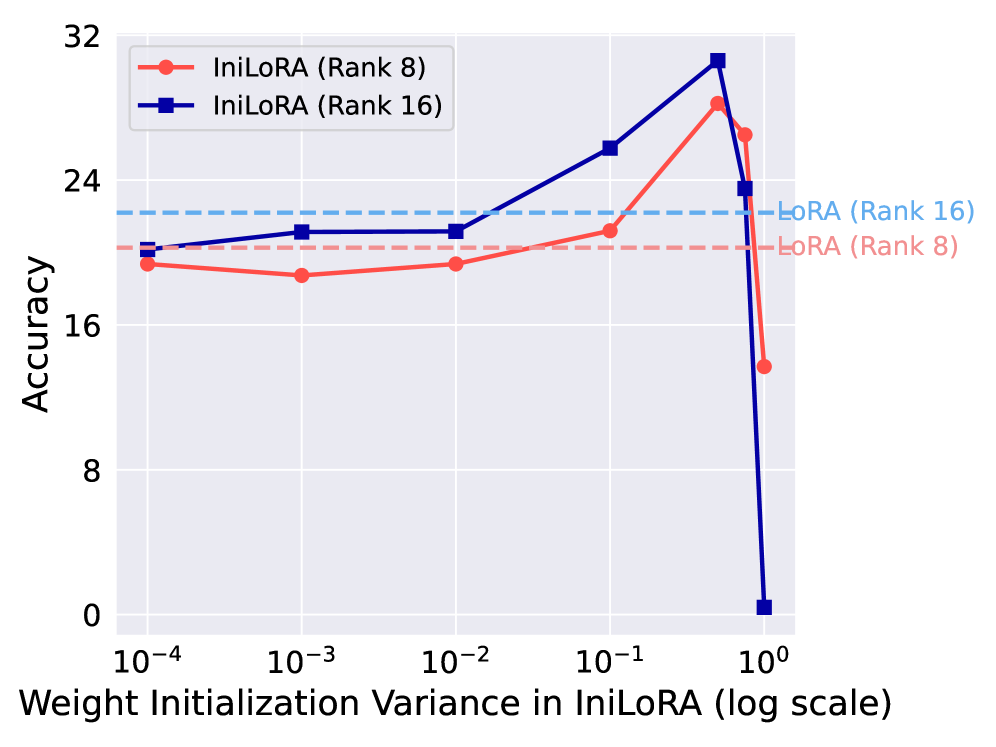
关键设计:IniLoRA-$α$和IniLoRA-$β$的关键设计在于如何计算目标矩阵。具体细节未知,但摘要中提到它们使用了不同的初始化方法。论文中应该会详细描述这两种初始化策略的具体公式和实现方法。此外,低秩矩阵的秩(rank)的选择也是一个重要的参数,需要根据具体的任务和模型进行调整。
🖼️ 关键图片
📊 实验亮点
实验结果表明,IniLoRA在多个模型和任务上均优于LoRA。具体性能提升数据未知,但摘要强调了IniLoRA及其变体在不同模型和任务上的普遍适用性。IniLoRA-$α$和IniLoRA-$β$作为IniLoRA的变体,进一步提升了性能,表明了初始化策略优化的有效性。
🎯 应用场景
IniLoRA可广泛应用于各种大型语言模型的参数高效微调场景,尤其适用于资源受限但对性能要求较高的应用,如移动设备上的自然语言处理、边缘计算环境下的智能助手等。该方法能够提升模型在特定任务上的表现,降低部署成本,并加速模型迭代。
📄 摘要(原文)
The rapid development of parameter-efficient fine-tuning methods has noticeably improved the efficiency of adapting large language models. Among these, LoRA has gained widespread popularity due to its strong balance of effectiveness and parameter efficiency. However, LoRA relies on initializing two low-rank matrices whose product is zero, which limits its ability to effectively activate and leverage the original model weights-creating a potential bottleneck for optimal performance. To address this limitation, we propose \textbf{IniLoRA}, a novel initialization strategy that initializes the low-rank matrices to closely approximate the original model weights. Experimental results indicate that IniLoRA achieves better performance than LoRA across a range of models and tasks. Additionally, we introduce two variants, IniLoRA-$α$ and IniLoRA-$β$, both leveraging distinct initialization methods to enhance performance further.