Token Hidden Reward: Steering Exploration-Exploitation in Group Relative Deep Reinforcement Learning
作者: Wenlong Deng, Yi Ren, Yushu Li, Boying Gong, Danica J. Sutherland, Xiaoxiao Li, Christos Thrampoulidis
分类: cs.LG, cs.CL
发布日期: 2025-10-04 (更新: 2025-11-11)
备注: Full version of submission to 2nd AI for Math Workshop@ ICML 2025 (best paper)
💡 一句话要点
提出Token Hidden Reward,用于在群体相对深度强化学习中引导探索-利用。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 强化学习 大语言模型 探索-利用 群体相对策略优化 Token Hidden Reward
📋 核心要点
- 现有基于可验证奖励的强化学习方法在提升大语言模型的推理能力方面取得了显著进展,但如何显式地引导训练偏向探索或利用仍然是一个开放性问题。
- 本文提出Token Hidden Reward (THR)指标,通过量化每个token对正确响应概率的影响,指导群体相对策略优化(GRPO)的探索-利用平衡。
- 实验表明,通过THR引导的重加权算法,可以有效提升贪婪解码准确率(偏向利用)和Pass@K准确率(偏向探索),且能与GSPO等目标及Llama等架构集成。
📝 摘要(中文)
本文提出了一种名为Token Hidden Reward (THR)的token级别指标,用于量化每个token在群体相对策略优化(GRPO)下对正确响应可能性的影响。研究发现,训练动态主要由具有高绝对THR值的token子集主导。正THR值的token增强了对正确输出的信心,从而有利于利用;而负THR值的token保留了替代输出的概率质量,从而实现了探索。基于此,提出了一种THR引导的重加权算法,该算法调节GRPO的学习信号,以明确地偏向于利用或探索。在多种数学推理基准上验证了该算法的有效性。通过放大正THR值的token并削弱负THR值的token,该算法提高了贪婪解码的准确性,从而有利于利用。相反的策略在Pass@K准确率方面产生了持续的提升,从而有利于探索。该算法可以与GSPO等其他RL目标无缝集成,并推广到包括Llama在内的各种架构。这些发现表明,THR是一种原则性的、细粒度的机制,用于动态控制RL调优的LLM中的探索和利用,为推理密集型应用中的有针对性的微调提供了新的工具。
🔬 方法详解
问题定义:现有强化学习方法在训练大语言模型时,难以有效控制探索和利用之间的平衡。虽然可以通过调整奖励函数来间接影响,但缺乏一种细粒度的、可解释的机制来显式地引导模型偏向于探索或利用。这限制了模型在复杂推理任务中的性能。
核心思路:本文的核心思路是识别并量化每个token对模型输出结果的影响,特别是对正确答案概率的影响。通过分析每个token对最终结果的贡献,可以区分出促进“利用”(增强正确答案信心)和促进“探索”(保留其他可能答案)的token。然后,通过调整这些token的学习信号,可以显式地控制模型的探索-利用行为。这样设计的目的是提供一种更精细、更可控的训练方式。
技术框架:该方法基于群体相对策略优化(GRPO)框架。首先,计算每个token的Token Hidden Reward (THR)值,该值反映了该token对正确响应概率的影响。然后,使用THR值来重新加权GRPO的学习信号,从而偏向于利用(放大正THR值的token)或探索(放大负THR值的token)。该框架可以与其他强化学习目标(如GSPO)集成,并应用于不同的语言模型架构(如Llama)。
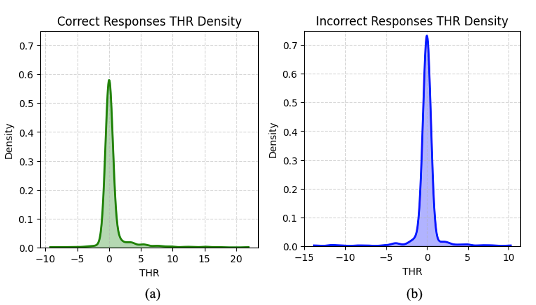
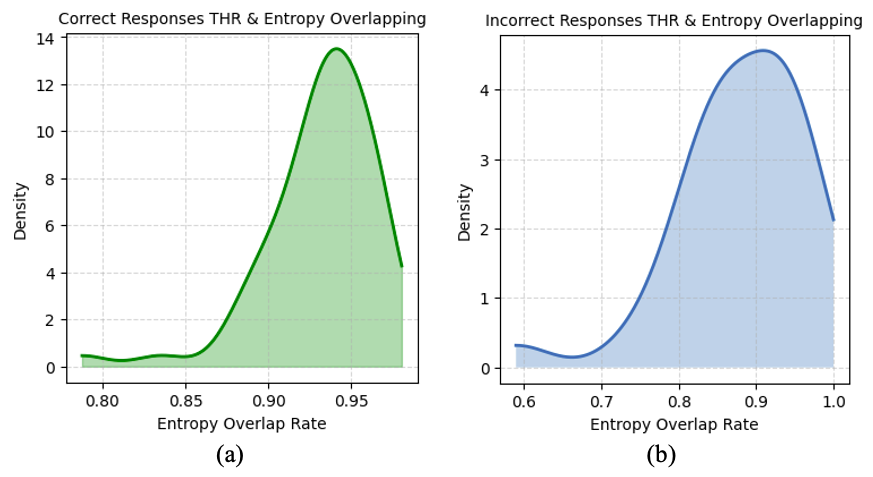
关键创新:该方法最重要的创新点在于提出了Token Hidden Reward (THR)的概念,并将其作为一种细粒度的、可解释的机制来控制强化学习中的探索-利用平衡。与传统的通过调整奖励函数来间接影响探索-利用的方法不同,THR直接作用于每个token的学习信号,从而实现了更精确的控制。此外,该方法还提供了一种新的视角来理解语言模型的训练动态,即训练过程主要由一小部分具有高绝对THR值的token主导。
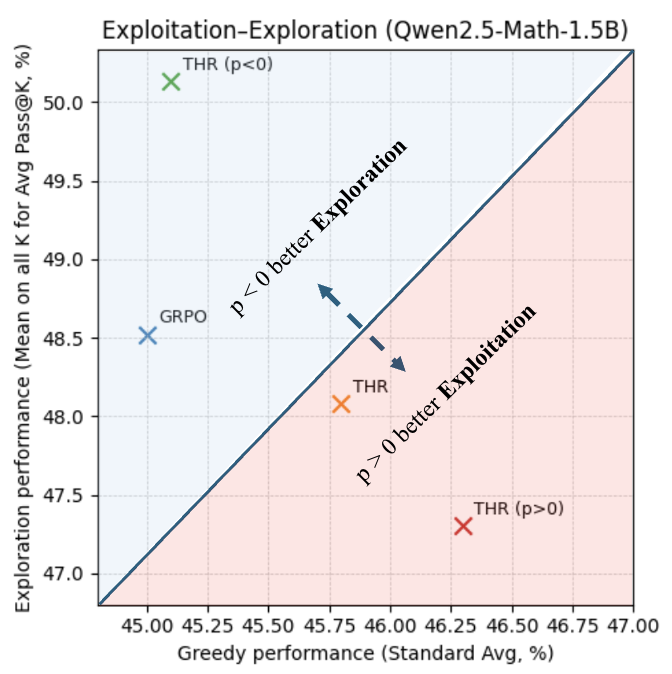
关键设计:THR的计算方式是衡量token对正确响应概率的影响。具体来说,正THR值的token增强了模型对正确输出的信心,而负THR值的token保留了其他可能输出的概率质量。THR引导的重加权算法通过调整GRPO的学习信号来实现探索-利用的偏向。具体来说,通过放大正THR值的token并削弱负THR值的token,可以提高贪婪解码的准确性,从而有利于利用。相反的策略可以提高Pass@K准确率,从而有利于探索。具体的重加权函数形式和参数选择需要根据具体任务进行调整。
🖼️ 关键图片
📊 实验亮点
实验结果表明,通过THR引导的重加权算法,可以有效提升大语言模型在数学推理基准上的性能。具体来说,放大正THR值的token可以提高贪婪解码的准确性,而放大负THR值的token可以提高Pass@K准确率。该方法可以与GSPO等其他RL目标无缝集成,并推广到包括Llama在内的各种架构,展示了其通用性和有效性。
🎯 应用场景
该研究成果可应用于各种需要精细控制探索-利用平衡的推理密集型任务,例如数学问题求解、代码生成、知识图谱推理等。通过THR引导的微调,可以显著提升大语言模型在这些任务上的性能,并为开发更智能、更可靠的AI系统提供新的工具。
📄 摘要(原文)
Reinforcement learning with verifiable rewards has significantly advanced the reasoning capabilities of large language models, yet how to explicitly steer training toward exploration or exploitation remains an open problem. We introduce Token Hidden Reward (THR), a token-level metric that quantifies each token's influence on the likelihood of correct responses under Group Relative Policy Optimization (GRPO). We find that training dynamics are dominated by a small subset of tokens with high absolute THR values. Most interestingly, tokens with positive THR strengthen confidence in correct outputs, thus favoring exploitation, while tokens with negative THR preserve probability mass for alternative outputs, enabling exploration. This insight suggests a natural intervention: a THR-guided reweighting algorithm that modulates GRPO's learning signals to explicitly bias training toward exploitation or exploration. We validate the efficacy of this algorithm on diverse math reasoning benchmarks. By amplifying tokens with positive THR value and weakening negative ones, our algorithm improves greedy-decoding accuracy, favoring exploitation. The reverse strategy yields consistent gains in Pass@K accuracy, favoring exploration. We further demonstrate that our algorithm integrates seamlessly with other RL objectives such as GSPO and generalizes across architectures including Llama. These findings establish THR as a principled and fine-grained mechanism for dynamically controlling exploration and exploitation in RL-tuned LLMs, providing new tools for targeted fine-tuning in reasoning-intensive applications.