Does higher interpretability imply better utility? A Pairwise Analysis on Sparse Autoencoders
作者: Xu Wang, Yan Hu, Benyou Wang, Difan Zou
分类: cs.LG, cs.AI, cs.CL, stat.ML
发布日期: 2025-10-04
备注: 24 pages
💡 一句话要点
揭示稀疏自编码器可解释性与操控效用间的差距,提出Delta Token Confidence特征选择方法。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 稀疏自编码器 大型语言模型 可解释性 模型引导 特征选择 Delta Token Confidence 模型操控
📋 核心要点
- 现有方法假设稀疏自编码器的可解释性直接转化为更好的模型操控能力,但缺乏充分验证。
- 论文提出Delta Token Confidence指标,用于选择对LLM行为影响更大的特征,从而提升操控性能。
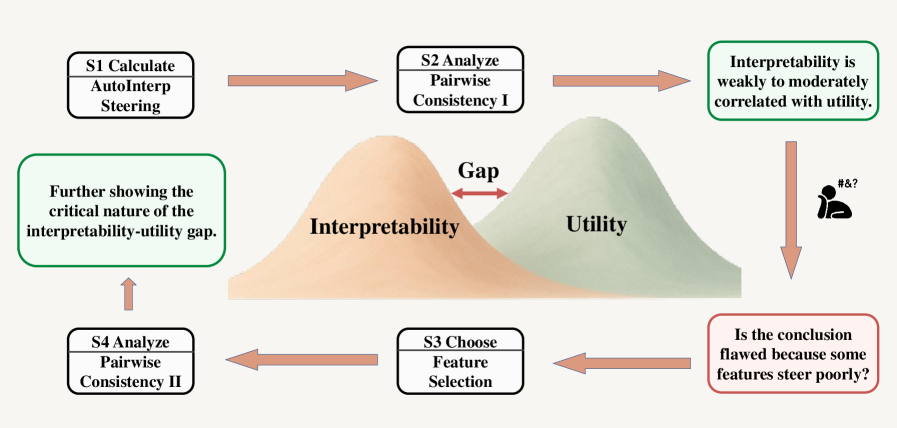
- 实验表明,基于Delta Token Confidence选择的特征,能显著提升LLM操控性能,并揭示可解释性与操控效用间的负相关性。
📝 摘要(中文)
稀疏自编码器(SAEs)被广泛用于引导大型语言模型(LLMs),其依据是可解释的特征自然能够实现有效的模型行为引导。然而,一个根本问题仍未解决:更高的可解释性是否确实意味着更好的引导效用?为了回答这个问题,我们训练了跨越三个LLM(Gemma-2-2B, Qwen-2.5-3B, Gemma-2-9B)的90个SAE,涵盖五种架构和六个稀疏度级别,并分别基于SAEBench和AxBench评估了它们的可解释性和引导效用,并通过Kendall等级相关系数(tau b)进行了等级一致性分析。我们的分析表明,只有相对较弱的正相关关系(tau b约0.298),表明可解释性不足以作为引导性能的代理。我们推测可解释性与效用之间的差距可能源于SAE特征的选择,因为并非所有特征都对引导同样有效。为了进一步找到真正引导LLM行为的特征,我们提出了一种新的选择标准,称为Delta Token Confidence,它衡量放大一个特征对下一个token分布的影响程度。我们表明,与当前最佳的基于输出分数的标准相比,我们的方法将三个LLM的引导性能提高了52.52%。引人注目的是,在使用高Delta Token Confidence选择特征后,可解释性和效用之间的相关性消失了(tau b约0),甚至可能变为负相关。这进一步突出了对于最有效的引导特征,可解释性和效用之间的差异。
🔬 方法详解
问题定义:现有方法依赖稀疏自编码器(SAE)的可解释性来引导大型语言模型(LLM)的行为,但缺乏对“可解释性越高,引导效果越好”这一假设的验证。现有方法主要依赖人工定义的特征或简单的输出分数来选择SAE特征,忽略了特征对LLM行为的真实影响,导致可解释性好的特征不一定具有良好的引导效果。
核心思路:论文的核心思路是直接衡量SAE特征对LLM下一个token预测的影响,提出Delta Token Confidence指标。该指标量化了放大某个SAE特征后,LLM预测下一个token的概率分布变化。通过选择具有高Delta Token Confidence的特征,可以更有效地引导LLM的行为。这种方法避免了依赖于可解释性的主观判断,直接关注特征对模型行为的实际影响。
技术框架:论文的技术框架主要包含以下几个步骤:1) 训练多个不同架构和稀疏度的SAE;2) 使用SAEBench和AxBench评估SAE的可解释性和引导效用;3) 计算每个SAE特征的Delta Token Confidence;4) 基于Delta Token Confidence选择特征子集;5) 使用选择的特征子集引导LLM,并评估引导效果。
关键创新:论文的关键创新在于提出了Delta Token Confidence这一新的特征选择标准。与现有方法相比,Delta Token Confidence直接衡量特征对LLM行为的影响,避免了依赖于可解释性的主观判断。此外,论文还通过实验揭示了可解释性与引导效用之间的差距,并证明了基于Delta Token Confidence选择的特征能够显著提升LLM的引导性能。
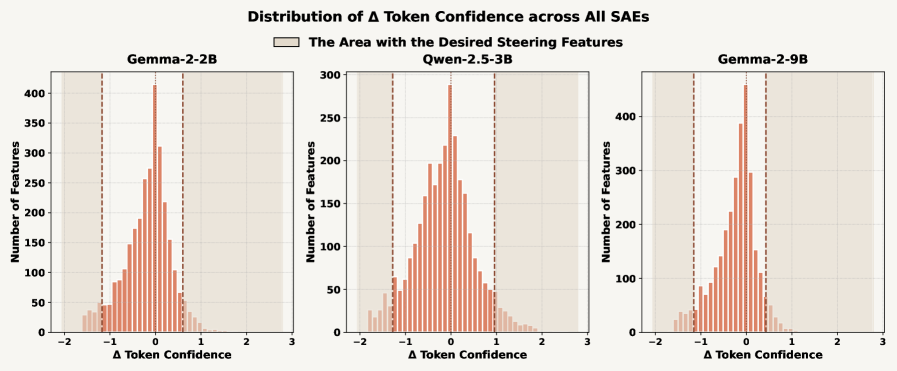
关键设计:Delta Token Confidence的计算方式为:首先,计算原始LLM在给定上下文下的下一个token概率分布;然后,放大某个SAE特征,并重新计算下一个token概率分布;最后,计算两个概率分布之间的差异,例如KL散度或JS散度。论文中具体使用了哪种差异度量方式未知。此外,如何确定放大的幅度也是一个关键设计,论文中可能使用了启发式方法或优化算法来确定最佳的放大幅度。
🖼️ 关键图片

📊 实验亮点
实验结果表明,基于Delta Token Confidence选择的特征,能够将三个LLM(Gemma-2-2B, Qwen-2.5-3B, Gemma-2-9B)的引导性能提升52.52%,显著优于当前最佳的基于输出分数的特征选择方法。此外,实验还发现,在使用高Delta Token Confidence选择特征后,可解释性和效用之间的相关性消失,甚至可能变为负相关。
🎯 应用场景
该研究成果可应用于提升大型语言模型的可控性和安全性。通过选择对模型行为影响更大的特征,可以更有效地引导模型生成符合预期或避免有害内容的文本。此外,该方法还可以用于分析和理解LLM的内部机制,揭示哪些特征对模型的决策起关键作用。
📄 摘要(原文)
Sparse Autoencoders (SAEs) are widely used to steer large language models (LLMs), based on the assumption that their interpretable features naturally enable effective model behavior steering. Yet, a fundamental question remains unanswered: does higher interpretability indeed imply better steering utility? To answer this question, we train 90 SAEs across three LLMs (Gemma-2-2B, Qwen-2.5-3B, Gemma-2-9B), spanning five architectures and six sparsity levels, and evaluate their interpretability and steering utility based on SAEBench (arXiv:2501.12345) and AxBench (arXiv:2502.23456) respectively, and perform a rank-agreement analysis via Kendall's rank coefficients (tau b). Our analysis reveals only a relatively weak positive association (tau b approx 0.298), indicating that interpretability is an insufficient proxy for steering performance. We conjecture the interpretability utility gap may stem from the selection of SAE features, as not all of them are equally effective for steering. To further find features that truly steer the behavior of LLMs, we propose a novel selection criterion called Delta Token Confidence, which measures how much amplifying a feature changes the next token distribution. We show that our method improves the steering performance of three LLMs by 52.52 percent compared to the current best output score based criterion (arXiv:2503.34567). Strikingly, after selecting features with high Delta Token Confidence, the correlation between interpretability and utility vanishes (tau b approx 0), and can even become negative. This further highlights the divergence between interpretability and utility for the most effective steering features.