Deep Reinforcement Learning for Multi-Agent Coordination
作者: Kehinde O. Aina, Sehoon Ha
分类: cs.LG, cs.AI, cs.MA, cs.RO
发布日期: 2025-10-04
备注: 11 pages, 8 figures, 1 table, presented at SWARM 2022, to be published in Journal of Artificial Life and Robotics
💡 一句话要点
提出基于虚拟信息素的S-MADRL框架,解决拥挤环境中多智能体高效协作问题
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 多智能体系统 深度强化学习 信息素算法 课程学习 去中心化协作
📋 核心要点
- 现有MADQN、MADDPG和MAPPO等算法在复杂多智能体协作任务中存在收敛性和可扩展性瓶颈。
- S-MADRL框架借鉴生物信息素机制,通过虚拟信息素建模智能体间的局部交互,实现去中心化协作。
- 采用课程学习策略,将复杂任务分解为多个难度递增的子任务,加速算法收敛并提升性能。
📝 摘要(中文)
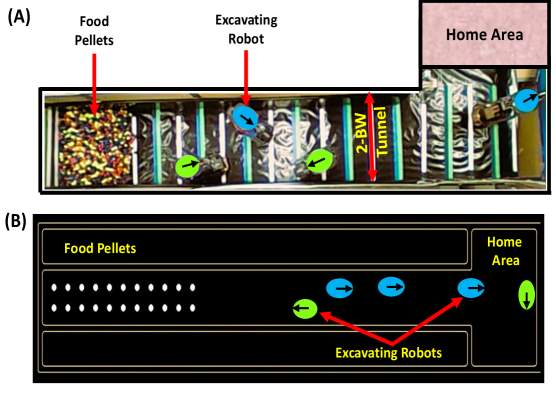
本文旨在解决狭窄和受限环境中多机器人协作的挑战,拥堵和干扰通常会阻碍集体任务的完成。受昆虫群体通过信息素(修改和解释环境痕迹)实现稳健协作的启发,我们提出了一个基于信息素的多智能体深度强化学习(S-MADRL)框架,该框架利用虚拟信息素来建模局部和社交互动,从而实现无需显式通信的去中心化涌现式协作。为了克服现有算法(如MADQN、MADDPG和MAPPO)的收敛性和可扩展性限制,我们利用课程学习将复杂任务分解为逐渐变难的子问题。仿真结果表明,我们的框架实现了最多八个智能体的最有效协作,机器人自组织成不对称的工作负载分布,从而减少拥堵并调节群体性能。这种类似于自然界观察到的策略的涌现行为,展示了一种可扩展的解决方案,用于在具有通信约束的拥挤环境中进行去中心化多智能体协作。
🔬 方法详解
问题定义:论文旨在解决多智能体在狭窄拥挤环境中协作效率低下的问题。现有方法如MADQN、MADDPG和MAPPO等,在智能体数量增加或环境复杂度提高时,面临收敛困难和扩展性不足的挑战,难以实现高效的去中心化协作。
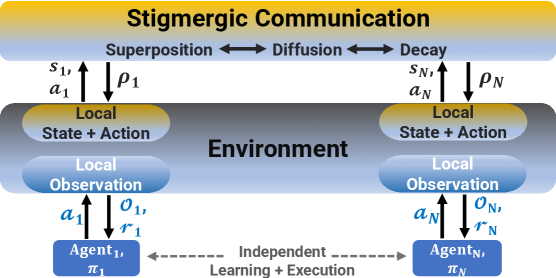
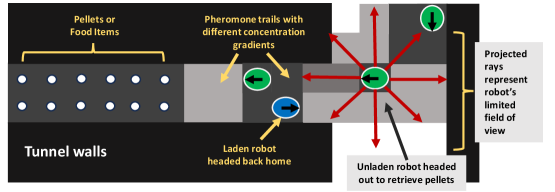
核心思路:论文的核心思路是模仿昆虫群体的信息素协作机制,利用虚拟信息素作为智能体之间交互的媒介。每个智能体通过感知环境中的虚拟信息素浓度,并根据自身状态释放信息素,从而影响其他智能体的行为,实现间接的协作。这种方法避免了显式的通信,降低了通信开销,提高了系统的鲁棒性。
技术框架:S-MADRL框架包含以下主要模块:1)环境建模模块,用于模拟多智能体协作的环境,包括智能体的位置、速度、障碍物等信息;2)信息素交互模块,负责虚拟信息素的释放、扩散和衰减;3)策略学习模块,采用深度强化学习算法(如MADDPG),学习每个智能体的最优策略,目标是最大化全局奖励;4)课程学习模块,将复杂任务分解为多个难度递增的子任务,逐步训练智能体。
关键创新:论文的关键创新在于将信息素机制引入到多智能体深度强化学习中,提出了一种基于虚拟信息素的去中心化协作方法。与现有方法相比,S-MADRL无需显式通信,降低了通信开销,提高了系统的鲁棒性和可扩展性。此外,课程学习策略的引入,加速了算法的收敛,提升了性能。
关键设计:信息素的释放和衰减速率是关键参数,需要根据具体任务进行调整。损失函数采用MADDPG的集中式训练、分布式执行框架,每个智能体根据全局状态和动作信息进行策略更新。网络结构采用多层感知机或循环神经网络,用于提取智能体的状态特征和信息素特征。
🖼️ 关键图片
📊 实验亮点
实验结果表明,S-MADRL框架在多智能体协作任务中取得了显著的性能提升。在八个智能体的仿真环境中,S-MADRL能够使机器人自组织成不对称的工作负载分布,有效减少拥堵,并显著提升群体性能。与MADDPG等基线方法相比,S-MADRL在任务完成时间和成功率方面均有明显优势。
🎯 应用场景
该研究成果可应用于仓库机器人、自动驾驶车队、无人机集群等领域,解决拥挤环境下的多智能体协作问题。通过虚拟信息素机制,可以实现智能体之间的自组织和协同,提高任务完成效率,降低通信成本,具有重要的实际应用价值和广阔的应用前景。
📄 摘要(原文)
We address the challenge of coordinating multiple robots in narrow and confined environments, where congestion and interference often hinder collective task performance. Drawing inspiration from insect colonies, which achieve robust coordination through stigmergy -- modifying and interpreting environmental traces -- we propose a Stigmergic Multi-Agent Deep Reinforcement Learning (S-MADRL) framework that leverages virtual pheromones to model local and social interactions, enabling decentralized emergent coordination without explicit communication. To overcome the convergence and scalability limitations of existing algorithms such as MADQN, MADDPG, and MAPPO, we leverage curriculum learning, which decomposes complex tasks into progressively harder sub-problems. Simulation results show that our framework achieves the most effective coordination of up to eight agents, where robots self-organize into asymmetric workload distributions that reduce congestion and modulate group performance. This emergent behavior, analogous to strategies observed in nature, demonstrates a scalable solution for decentralized multi-agent coordination in crowded environments with communication constraints.