Machine Unlearning Meets Adversarial Robustness via Constrained Interventions on LLMs
作者: Fatmazohra Rezkellah, Ramzi Dakhmouche
分类: cs.LG, cs.CL, cs.CR, cs.CY, math.OC
发布日期: 2025-10-03 (更新: 2025-10-16)
💡 一句话要点
提出基于约束干预的大语言模型不可学习与对抗鲁棒性统一方法
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 不可学习 对抗鲁棒性 约束优化 权重干预
📋 核心要点
- 现有大语言模型在处理隐私数据和防御对抗攻击方面存在不足,需要更有效的定制化方法。
- 论文提出通过约束优化,对LLM权重进行最小干预,实现敏感信息不可学习和对抗鲁棒性的统一。
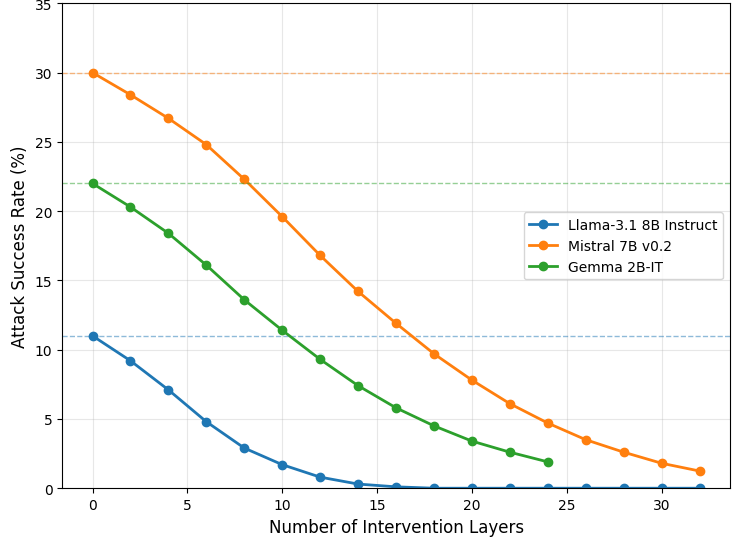
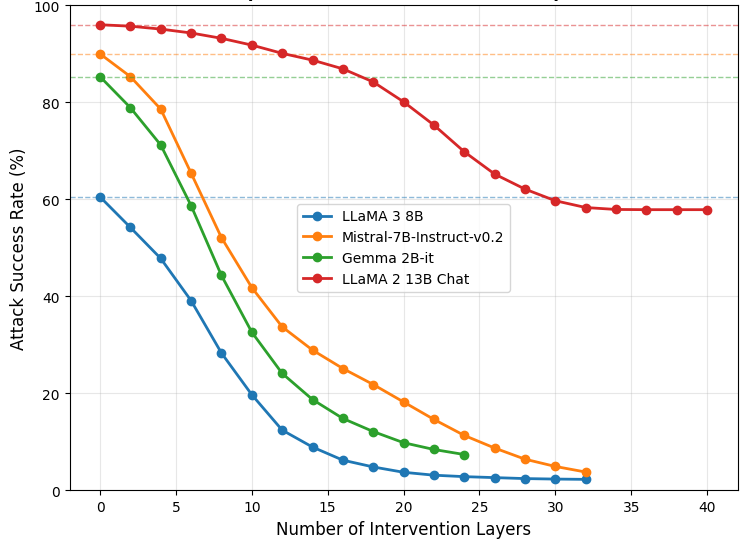
- 实验表明,简单的点式约束干预方法优于复杂的最大-最小干预,且计算成本更低,性能优于现有防御方法。
📝 摘要(中文)
随着大语言模型(LLMs)的日益普及,对隐私保护和安全生成的需求也日益增长。本文从两个关键方面着手解决这一问题:敏感信息的不可学习和对抗攻击的鲁棒性。我们研究了各种约束优化公式,通过在LLM权重上进行尽可能小的干预,以统一的方式解决这两个问题,使得给定的词汇集无法访问,或者通过将部分权重转移到“更安全”的区域,使LLM嵌入对定制攻击的鲁棒性。除了统一两个关键属性外,这种方法与之前的工作不同之处在于,它不需要通常不可用或代表计算开销的oracle分类器。令人惊讶的是,我们发现我们提出的最简单的基于点式约束的干预比最大-最小干预产生更好的性能,同时具有更低的计算成本。与最先进的防御方法相比,该方法表现出卓越的性能。
🔬 方法详解
问题定义:论文旨在解决大语言模型(LLMs)中两个关键问题:一是如何有效地不可学习(unlearn)模型中存在的敏感信息,防止模型泄露隐私;二是如何提高LLM对抗恶意攻击(如jail-breaking攻击)的鲁棒性。现有方法通常需要额外的oracle分类器来识别敏感信息或对抗样本,这增加了计算开销,并且oracle分类器本身可能难以获得或不够准确。
核心思路:论文的核心思路是通过对LLM的权重进行约束性干预,寻找最小的权重调整,使得模型既能遗忘特定信息(即无法生成包含敏感词汇的文本),又能抵抗对抗攻击。这种方法旨在通过统一的框架解决不可学习和鲁棒性问题,避免使用额外的分类器。
技术框架:该方法的核心是一个约束优化问题,目标是在满足特定约束条件(例如,使某些词汇无法生成)下,最小化对LLM权重的修改。具体流程包括:1) 定义需要不可学习的词汇集或需要防御的对抗攻击类型;2) 构建约束优化问题,其中约束条件确保模型无法生成包含敏感词汇的文本或能够抵抗对抗攻击;3) 使用优化算法求解该问题,得到修改后的LLM权重。
关键创新:该方法的主要创新在于:1) 统一了不可学习和对抗鲁棒性两个目标,通过单一的约束优化框架同时实现;2) 避免了对额外oracle分类器的依赖,降低了计算复杂度和对外部资源的依赖;3) 提出了一种简单的点式约束干预方法,该方法在性能上优于更复杂的最大-最小干预方法。
关键设计:论文提出了不同的约束优化公式,包括点式约束和最大-最小约束。点式约束直接限制特定权重的值,以防止模型生成敏感词汇。最大-最小约束则旨在提高模型对对抗攻击的鲁棒性。具体的损失函数和优化算法的选择取决于具体的应用场景和约束条件。关键参数包括约束强度和优化算法的学习率等。
🖼️ 关键图片
📊 实验亮点
实验结果表明,论文提出的点式约束干预方法在不可学习和对抗鲁棒性方面均优于现有方法。尤其是在计算成本方面,该方法显著低于最大-最小干预方法,同时取得了更好的性能。与最先进的防御方法相比,该方法也表现出卓越的性能提升,具体提升幅度未知。
🎯 应用场景
该研究成果可应用于各种需要保护用户隐私和确保模型安全的场景,例如:金融领域的风险评估模型、医疗领域的诊断模型、以及涉及个人身份信息的聊天机器人等。通过该方法,可以有效防止模型泄露敏感信息,并提高模型在实际应用中的安全性,降低被恶意利用的风险。未来,该方法可以进一步扩展到更复杂的模型和更广泛的应用领域。
📄 摘要(原文)
With the increasing adoption of Large Language Models (LLMs), more customization is needed to ensure privacy-preserving and safe generation. We address this objective from two critical aspects: unlearning of sensitive information and robustness to jail-breaking attacks. We investigate various constrained optimization formulations that address both aspects in a \emph{unified manner}, by finding the smallest possible interventions on LLM weights that either make a given vocabulary set unreachable or embed the LLM with robustness to tailored attacks by shifting part of the weights to a \emph{safer} region. Beyond unifying two key properties, this approach contrasts with previous work in that it doesn't require an oracle classifier that is typically not available or represents a computational overhead. Surprisingly, we find that the simplest point-wise constraint-based intervention we propose leads to better performance than max-min interventions, while having a lower computational cost. Comparison against state-of-the-art defense methods demonstrates superior performance of the proposed approach.