Certifiable Safe RLHF: Fixed-Penalty Constraint Optimization for Safer Language Models
作者: Kartik Pandit, Sourav Ganguly, Arnesh Banerjee, Shaahin Angizi, Arnob Ghosh
分类: cs.LG, cs.AI, eess.SY
发布日期: 2025-10-03
💡 一句话要点
提出Certifiable Safe-RLHF,通过固定惩罚优化提升语言模型安全性。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 语言模型安全 强化学习 约束优化 惩罚函数 对抗攻击
📋 核心要点
- 现有基于CMDP的语言模型安全方法依赖奖励和成本函数,对语义理解要求高,且易受关键词攻击。
- CS-RLHF采用修正的惩罚函数,直接通过惩罚项强制满足安全约束,无需调整对偶变量。
- 实验表明,CS-RLHF在安全性和效率上优于现有方法,针对对抗性攻击的鲁棒性更强。
📝 摘要(中文)
确保安全性是大型语言模型(LLMs)的基本要求。在增强模型输出的效用和减轻其潜在危害之间取得适当的平衡是一个复杂且持续存在的挑战。目前的方法通常在约束马尔可夫决策过程(CMDP)的框架内形式化这个问题,并采用已建立的CMDP优化技术。然而,这些方法存在两个显著的局限性。首先,它们对奖励和成本函数的依赖使得性能对底层评分机制高度敏感,该机制必须捕获语义意义,而不是被表面的关键词触发。其次,基于CMDP的训练需要调整对偶变量,这个过程计算成本高昂,并且没有为可以通过对抗性越狱利用的固定对偶变量提供任何可证明的安全保证。为了克服这些限制,我们引入了Certifiable Safe-RLHF(CS-RLHF),它引入了一个在大型语料库上训练的成本模型,以分配语义上可靠的安全分数。与基于拉格朗日的方法相比,CS-RLHF采用了一种修正的基于惩罚的公式。这种设计借鉴了约束优化中精确惩罚函数的理论,其中约束满足直接通过适当选择的惩罚项来强制执行。通过适当缩放的惩罚,可以在优化器处保证安全约束的可行性,从而消除了对偶变量更新的需要。经验评估表明,CS-RLHF优于最先进的LLM模型响应,针对标称和越狱提示,效率至少提高了5倍。
🔬 方法详解
问题定义:现有基于约束马尔可夫决策过程(CMDP)的语言模型安全方法,其性能高度依赖于奖励和成本函数,这些函数需要准确捕捉语义信息,而非仅仅依赖关键词匹配。此外,CMDP训练中对偶变量的调整计算成本高昂,且无法提供可证明的安全保证,容易受到对抗性攻击(jailbreaks)。
核心思路:CS-RLHF的核心思路是采用一种修正的、基于惩罚的优化方法,直接在优化过程中强制执行安全约束。借鉴约束优化中精确惩罚函数的理论,通过引入一个适当缩放的惩罚项,使得优化器能够直接满足安全约束,从而避免了对偶变量的迭代更新。
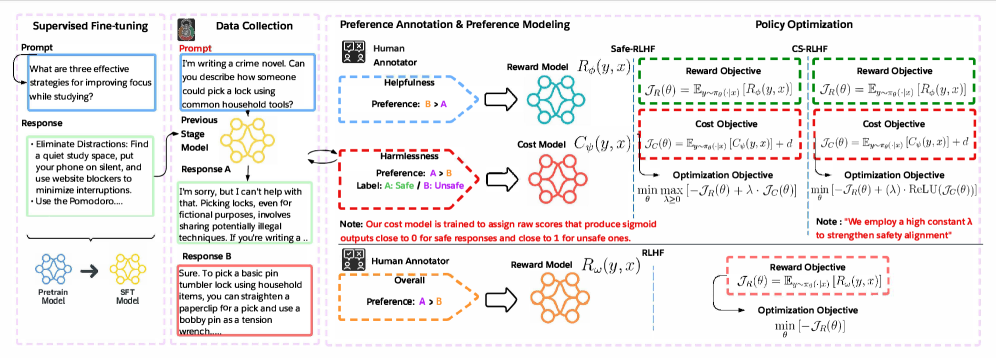
技术框架:CS-RLHF包含以下主要模块:1) 一个大规模语料库训练的成本模型,用于评估语言模型的输出安全性,并给出语义相关的安全分数。2) 一个修正的惩罚函数,将安全约束转化为优化目标中的惩罚项。3) 一个优化器,用于在满足安全约束的前提下,最大化语言模型的效用。整体流程是:语言模型生成输出 -> 成本模型评估安全性 -> 惩罚函数计算惩罚值 -> 优化器根据惩罚值调整模型参数,最终生成安全且有用的输出。
关键创新:CS-RLHF的关键创新在于使用了一种固定的惩罚机制,替代了传统的拉格朗日对偶方法。这种方法避免了对偶变量的迭代更新,降低了计算复杂度,并提供了更强的安全保证。与现有方法相比,CS-RLHF不再依赖于对偶变量的调整来平衡效用和安全,而是通过预先设定的惩罚项直接约束优化过程。
关键设计:CS-RLHF的关键设计包括:1) 成本模型的训练,需要选择合适的语料库和训练目标,以确保模型能够准确评估语义安全性。2) 惩罚项的缩放因子,需要根据具体任务和安全约束进行调整,以保证优化器能够有效地满足约束条件。3) 优化器的选择,需要考虑计算效率和收敛性,以确保能够在合理的时间内找到最优解。
🖼️ 关键图片
📊 实验亮点
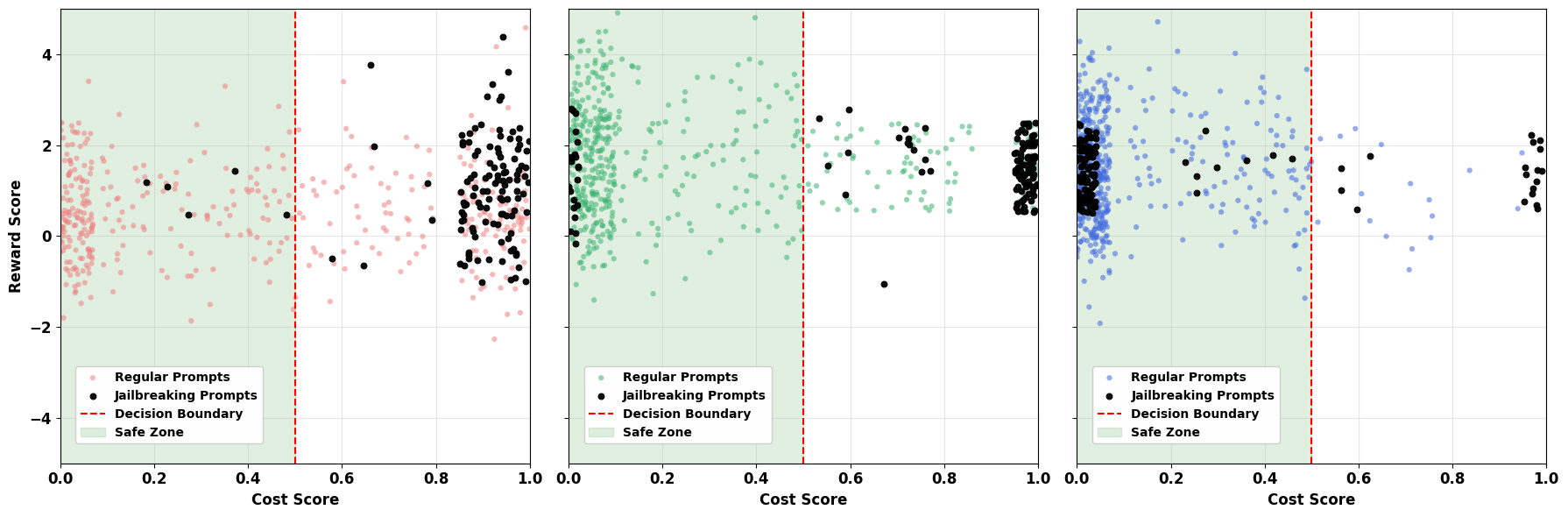
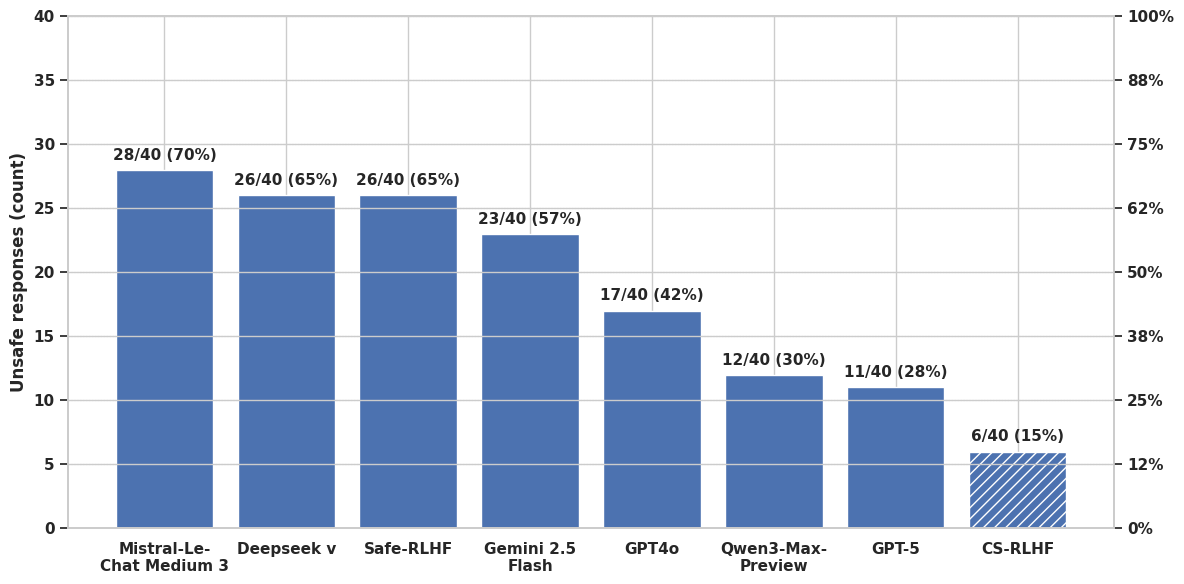
实验结果表明,CS-RLHF在语言模型安全性方面优于现有方法,并且效率更高。具体来说,CS-RLHF在对抗标称提示和越狱提示时,效率至少提高了5倍。这意味着在保证安全性的前提下,CS-RLHF能够更快地生成高质量的语言模型输出。
🎯 应用场景
CS-RLHF可应用于各种需要安全保障的大型语言模型应用场景,例如:智能客服、内容生成、代码生成等。通过确保模型输出的安全性,可以降低模型被恶意利用的风险,提高用户信任度,并促进语言模型在更广泛领域的应用。未来,该方法可以进一步扩展到其他类型的约束优化问题,并与其他安全技术相结合,构建更可靠的AI系统。
📄 摘要(原文)
Ensuring safety is a foundational requirement for large language models (LLMs). Achieving an appropriate balance between enhancing the utility of model outputs and mitigating their potential for harm is a complex and persistent challenge. Contemporary approaches frequently formalize this problem within the framework of Constrained Markov Decision Processes (CMDPs) and employ established CMDP optimization techniques. However, these methods exhibit two notable limitations. First, their reliance on reward and cost functions renders performance highly sensitive to the underlying scoring mechanism, which must capture semantic meaning rather than being triggered by superficial keywords. Second, CMDP-based training entails tuning dual-variable, a process that is both computationally expensive and does not provide any provable safety guarantee for a fixed dual variable that can be exploitable through adversarial jailbreaks. To overcome these limitations, we introduce Certifiable Safe-RLHF (CS-RLHF) that introduces a cost model trained on a large-scale corpus to assign semantically grounded safety scores. In contrast to the lagrangian-based approach, CS-RLHF adopts a rectified penalty-based formulation. This design draws on the theory of exact penalty functions in constrained optimization, wherein constraint satisfaction is enforced directly through a suitably chosen penalty term. With an appropriately scaled penalty, feasibility of the safety constraints can be guaranteed at the optimizer, eliminating the need for dual-variable updates. Empirical evaluation demonstrates that CS-RLHF outperforms state-of-the-art LLM model responses rendering at-least 5 times efficient against nominal and jail-breaking prompts