Density-Ratio Weighted Behavioral Cloning: Learning Control Policies from Corrupted Datasets
作者: Shriram Karpoora Sundara Pandian, Ali Baheri
分类: cs.LG, eess.SY
发布日期: 2025-10-01
💡 一句话要点
提出密度比加权行为克隆以解决数据污染问题
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 离线强化学习 行为克隆 数据污染 密度比 模仿学习 策略优化 鲁棒性
📋 核心要点
- 现有的离线强化学习方法在面对数据污染时,策略性能显著下降,无法有效利用受污染的数据集。
- 本文提出的Weighted BC方法通过使用干净参考集估计密度比,优先考虑高质量数据,从而提高了策略学习的鲁棒性。
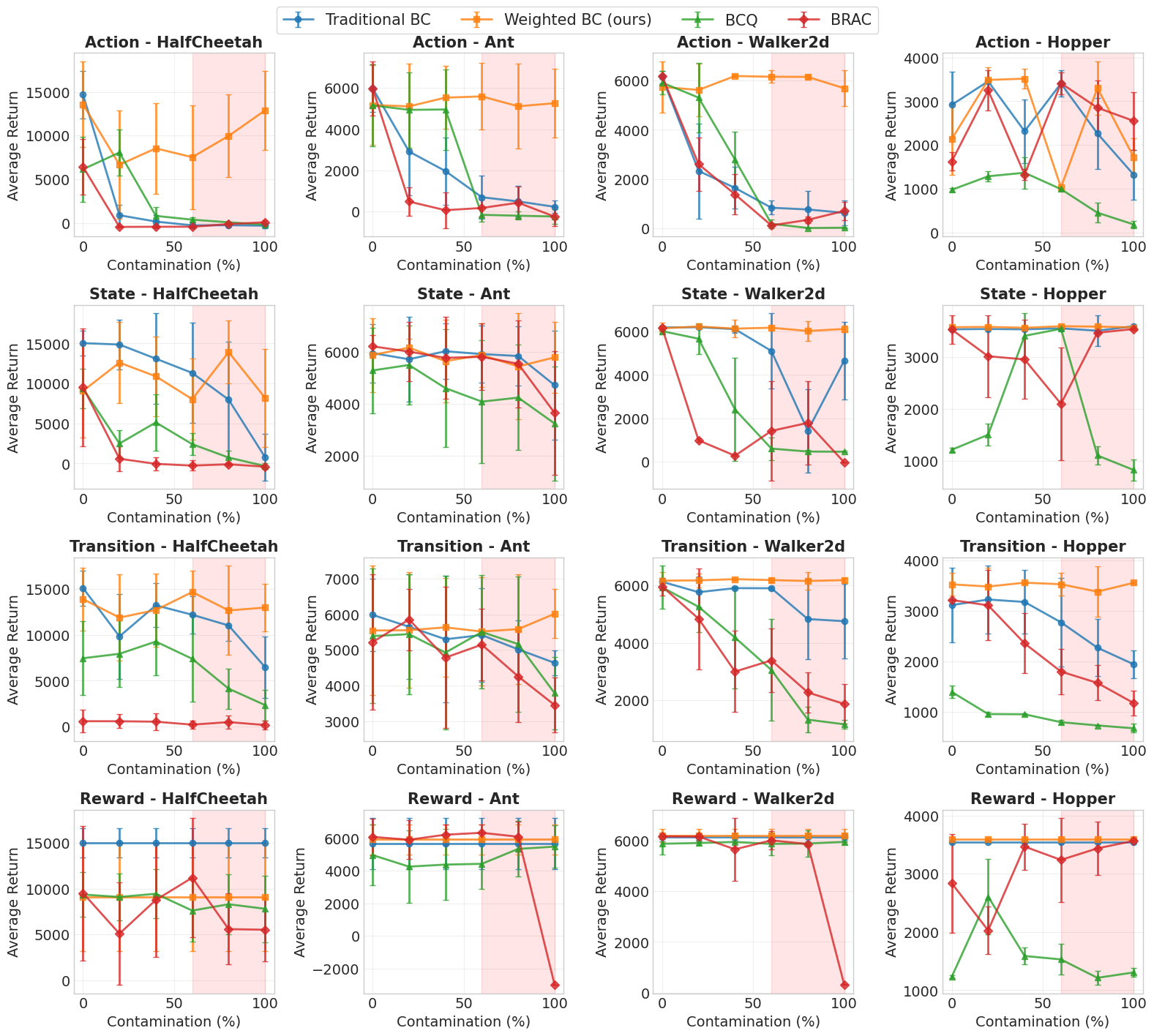
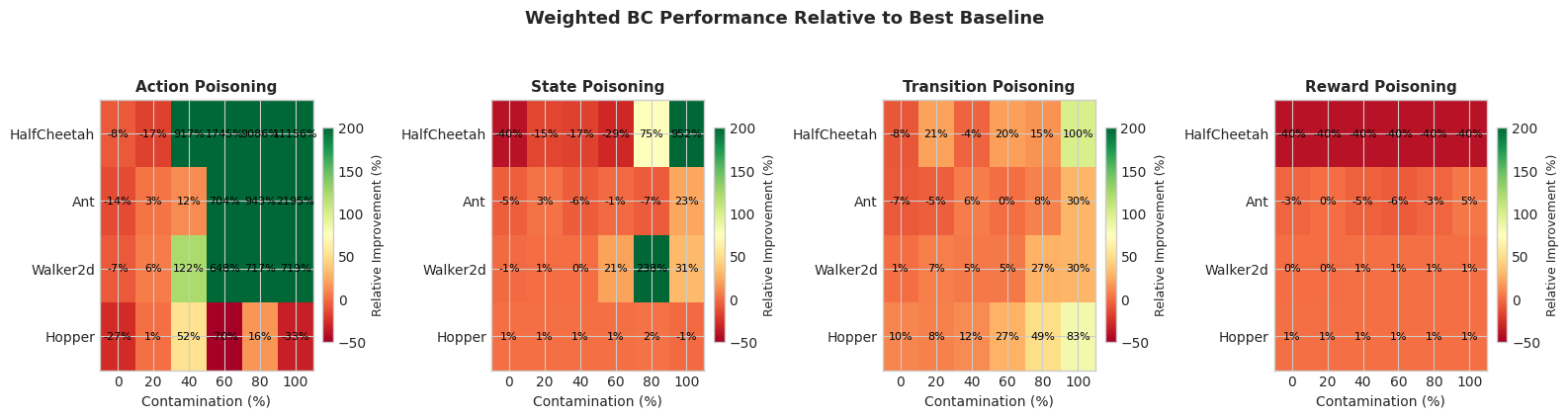
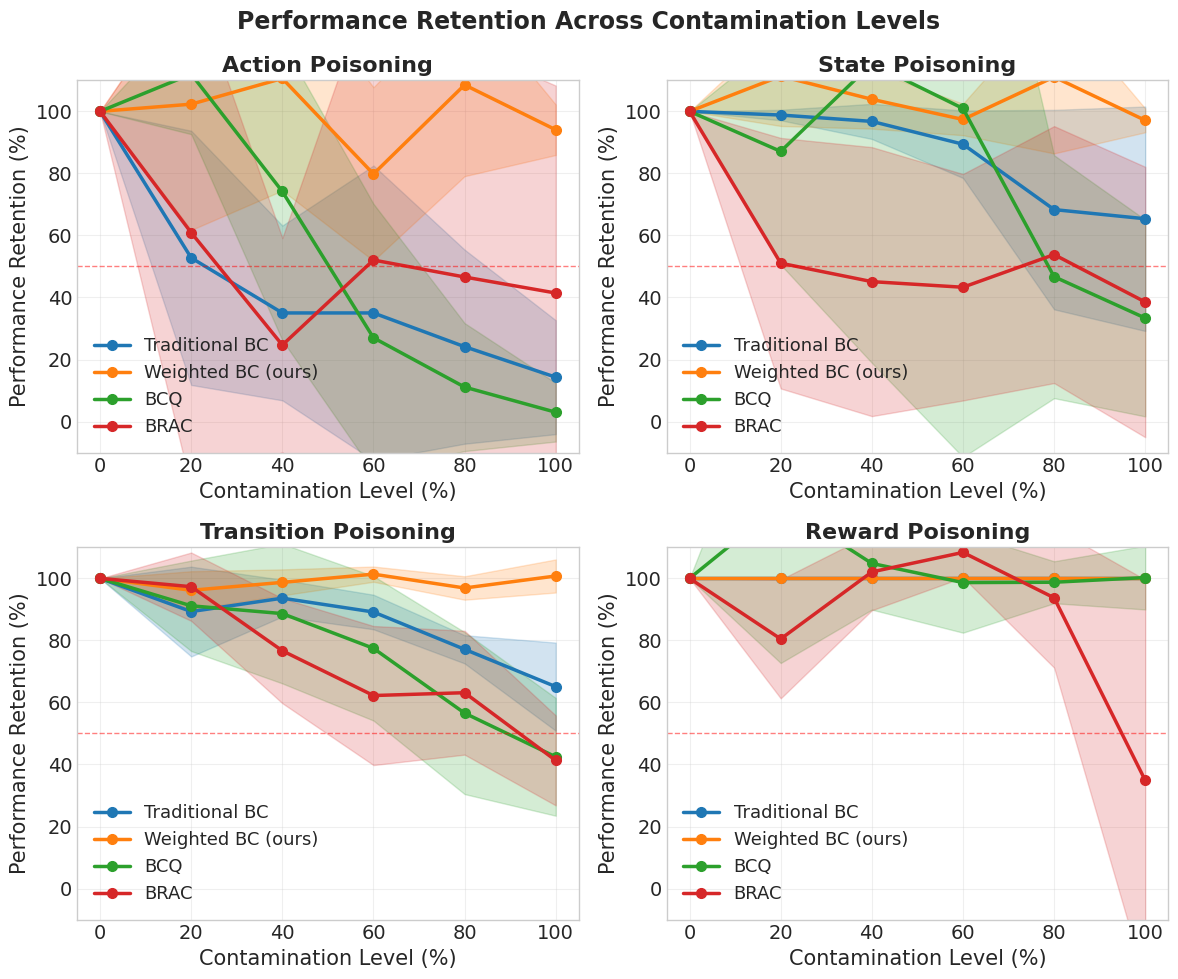
- 实验结果表明,Weighted BC在高达70%的数据污染率下仍能保持接近最优的性能,明显优于传统行为克隆和其他基线方法。
📝 摘要(中文)
离线强化学习(RL)使得从固定数据集中优化策略成为可能,适用于在线探索不可行的安全关键应用。然而,这些数据集常常受到对抗性污染、系统错误或低质量样本的影响,导致标准行为克隆(BC)和离线RL方法的策略性能下降。本文提出了密度比加权行为克隆(Weighted BC),这是一种稳健的模仿学习方法,利用小规模的经过验证的干净参考集,通过二元判别器估计轨迹级别的密度比。这些比率被裁剪并用作BC目标中的权重,以优先考虑干净的专家行为,同时降低或丢弃受污染的数据,而无需了解污染机制。我们建立了理论保证,显示在有限样本界限下收敛到干净的专家策略,这与污染率无关。综合评估框架涵盖了各种污染协议(奖励、状态、转移和动作),并在连续控制基准上进行了评估。实验表明,Weighted BC在高污染比率下仍能保持接近最优的性能,超越了传统BC、批约束Q学习(BCQ)和行为正则化演员-评论家(BRAC)等基线。
🔬 方法详解
问题定义:本文解决的问题是如何在数据集受到污染的情况下,依然有效地进行策略学习。现有的行为克隆和离线RL方法在面对对抗性污染和低质量样本时,性能显著下降,无法充分利用可用数据。
核心思路:论文提出的Weighted BC方法通过引入密度比的概念,利用小规模的干净参考集来估计轨迹级别的密度比,从而在训练过程中优先考虑高质量的专家行为,降低受污染数据的影响。
技术框架:Weighted BC的整体架构包括数据预处理、密度比估计和行为克隆目标优化三个主要模块。首先,通过二元判别器对干净和污染数据进行分类,然后计算密度比并应用于BC目标中。
关键创新:本文的主要创新在于引入密度比加权机制,使得在不需要了解污染机制的情况下,能够有效地减轻数据污染对策略学习的影响。这与传统的行为克隆方法有本质区别,后者通常无法处理数据质量不均的问题。
关键设计:在技术细节上,Weighted BC使用了裁剪的密度比作为权重,并设计了相应的损失函数来优化策略。此外,网络结构采用了适应性调整,以便在不同污染程度下保持稳定的学习效果。
🖼️ 关键图片
📊 实验亮点
实验结果显示,Weighted BC在高达70%的数据污染率下仍能保持接近最优的性能,相比传统行为克隆方法提升了约20%的策略表现。此外,Weighted BC在与批约束Q学习(BCQ)和行为正则化演员-评论家(BRAC)的对比中,均表现出显著的优势,验证了其有效性。
🎯 应用场景
该研究的潜在应用领域包括自动驾驶、医疗决策和机器人控制等安全关键场景。在这些领域,数据集往往受到污染,Weighted BC方法能够有效提升策略学习的鲁棒性,确保系统在不确定环境中的安全性和可靠性。未来,该方法有望推广到更多需要高可靠性的智能系统中。
📄 摘要(原文)
Offline reinforcement learning (RL) enables policy optimization from fixed datasets, making it suitable for safety-critical applications where online exploration is infeasible. However, these datasets are often contaminated by adversarial poisoning, system errors, or low-quality samples, leading to degraded policy performance in standard behavioral cloning (BC) and offline RL methods. This paper introduces Density-Ratio Weighted Behavioral Cloning (Weighted BC), a robust imitation learning approach that uses a small, verified clean reference set to estimate trajectory-level density ratios via a binary discriminator. These ratios are clipped and used as weights in the BC objective to prioritize clean expert behavior while down-weighting or discarding corrupted data, without requiring knowledge of the contamination mechanism. We establish theoretical guarantees showing convergence to the clean expert policy with finite-sample bounds that are independent of the contamination rate. A comprehensive evaluation framework is established, which incorporates various poisoning protocols (reward, state, transition, and action) on continuous control benchmarks. Experiments demonstrate that Weighted BC maintains near-optimal performance even at high contamination ratios outperforming baselines such as traditional BC, batch-constrained Q-learning (BCQ) and behavior regularized actor-critic (BRAC).