Thin Bridges for Drug Text Alignment: Lightweight Contrastive Learning for Target Specific Drug Retrieval
作者: Mallikarjuna Tupakula
分类: cs.LG, q-bio.BM
发布日期: 2025-09-30
💡 一句话要点
提出轻量级对比学习桥接方法,用于靶点特异性药物文本对齐与检索。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 药物发现 文本对齐 对比学习 分子指纹 靶点特异性检索
📋 核心要点
- 现有药物发现方法依赖大规模预训练或多模态语料库,计算成本高昂且数据需求大。
- 提出轻量级对比桥接方法,通过线性投影头对齐冻结的单模态编码器,实现跨模态对齐。
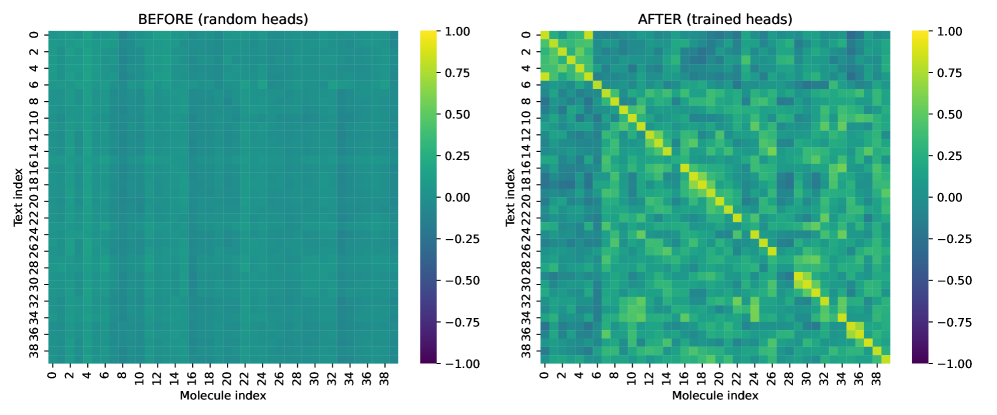
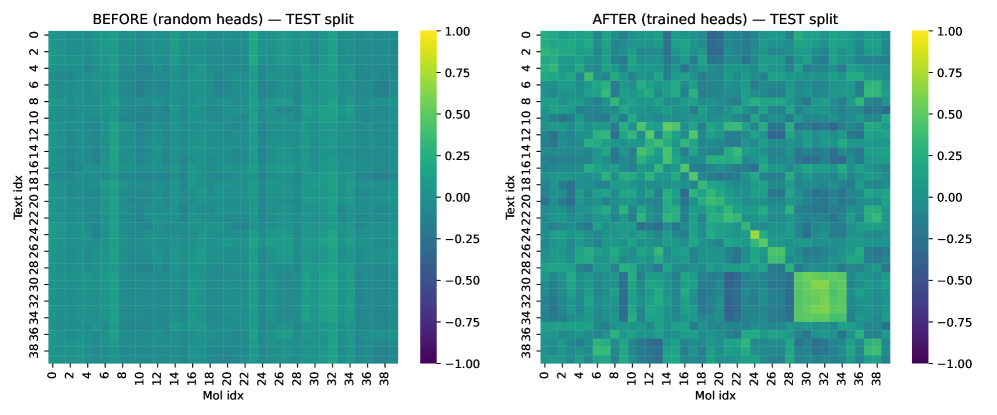
- 实验表明,该方法在骨架分割下显著提升了靶点内区分能力,为精准医学提供高效替代方案。
📝 摘要(中文)
多模态基础模型在药物发现和生物医学应用中展现出潜力,但现有方法通常依赖于大规模预训练或多模态语料库。本文研究了轻量级对比桥接方法,即在冻结的单模态编码器上使用轻量级投影头,是否可以在不训练完整多模态模型的情况下对齐化学和文本表示。利用ChEMBL中的配对机制,通过双线性投影和对比目标函数,将ECFP4分子指纹与生物医学句子嵌入对齐。为了更好地处理共享相同治疗靶点的药物,引入了难负样本加权和margin loss。基于骨架分割的评估(需要跨不相交化学核心的泛化)表明,该方法实现了非平凡的跨模态对齐,并显著提高了靶点内的区分能力。结果表明,轻量级桥接方法为大规模多模态预训练提供了一种计算高效的替代方案,从而能够在精准医学中实现骨架感知的药物文本对齐和靶点特异性检索。
🔬 方法详解
问题定义:论文旨在解决药物文本对齐问题,特别是针对具有相同治疗靶点的药物。现有方法通常需要大规模的多模态预训练,计算成本高昂,且需要大量的标注数据。此外,如何保证模型在具有不同化学骨架的药物上的泛化能力也是一个挑战。
核心思路:论文的核心思路是利用轻量级的对比学习桥接方法,在冻结的单模态编码器(例如,用于分子指纹的ECFP4和用于生物医学文本的句子嵌入)之上,训练简单的线性投影头,将不同模态的表示映射到同一个潜在空间。通过对比学习,使得具有相同靶点的药物的分子指纹和文本描述在潜在空间中更加接近,从而实现跨模态的对齐。
技术框架:整体框架包含以下几个主要模块:1) 单模态编码器:使用预训练的单模态编码器提取分子指纹和文本描述的特征表示。2) 线性投影头:使用两个线性投影层,分别将分子指纹和文本描述的特征表示映射到共享的潜在空间。3) 对比学习目标函数:使用对比学习目标函数,例如InfoNCE loss,来训练线性投影头,使得具有相同靶点的药物的表示在潜在空间中更加接近。4) 难负样本加权和Margin Loss:为了更好地处理共享相同治疗靶点的药物,引入了难负样本加权和margin loss。
关键创新:论文的关键创新在于提出了轻量级的对比学习桥接方法,可以在不进行大规模多模态预训练的情况下,实现跨模态的药物文本对齐。这种方法计算效率高,且可以利用预训练的单模态编码器的知识。此外,论文还引入了难负样本加权和margin loss,以提高模型在具有相同靶点的药物上的区分能力。
关键设计:论文的关键设计包括:1) 使用ECFP4分子指纹作为分子表示,因为它是一种常用的、高效的分子描述符。2) 使用预训练的生物医学句子嵌入作为文本表示,例如BioBERT。3) 使用对比学习目标函数InfoNCE loss,并引入难负样本加权和margin loss。4) 使用基于骨架分割的评估方法,以评估模型在具有不同化学骨架的药物上的泛化能力。
🖼️ 关键图片

📊 实验亮点
实验结果表明,该方法在基于骨架分割的评估中,显著提高了靶点内的区分能力。与冻结的基线模型相比,该方法实现了非平凡的跨模态对齐,表明轻量级桥接方法为大规模多模态预训练提供了一种计算高效的替代方案。
🎯 应用场景
该研究成果可应用于药物发现、药物重定位、精准医学等领域。通过对齐药物的化学结构和文本描述,可以更准确地检索具有特定靶点的药物,加速新药研发过程。此外,该方法还可以用于预测药物的副作用和适应症,为临床决策提供支持。
📄 摘要(原文)
Multimodal foundation models hold promise for drug discovery and biomedical applications, but most existing approaches rely on heavy pretraining or large scale multimodal corpora. We investigate whether thin contrastive bridges, lightweight projection heads over frozen unimodal encoders can align chemical and textual representations without training a full multimodal model. Using paired mechanisms from ChEMBL, we align ECFP4 molecular fingerprints with biomedical sentence embeddings through dual linear projections trained with a contrastive objective. To better handle drugs sharing the same therapeutic target, we incorporate hard negative weighting and a margin loss. Evaluation under scaffold based splits, which require generalization across disjoint chemical cores, demonstrates that our approach achieves non-trivial cross modal alignment and substantially improves within target discrimination compared to frozen baselines. These results suggest that thin bridges offer a compute efficient alternative to large scale multimodal pretraining, enabling scaffold aware drug text alignment and target specific retrieval in precision medicine.