Revoking Amnesia: RL-based Trajectory Optimization to Resurrect Erased Concepts in Diffusion Models
作者: Daiheng Gao, Nanxiang Jiang, Andi Zhang, Shilin Lu, Yufei Tang, Wenbo Zhou, Weiming Zhang, Zhaoxin Fan
分类: cs.LG, cs.CV
发布日期: 2025-09-30
备注: 21 pages, 10 figures
💡 一句话要点
提出RevAm,基于强化学习优化扩散模型轨迹,恢复被擦除的概念
🎯 匹配领域: 支柱一:机器人控制 (Robot Control)
关键词: 扩散模型 概念擦除 强化学习 轨迹优化 安全性 Group Relative Policy Optimization 文本到图像生成
📋 核心要点
- 现有概念擦除方法在新型扩散模型中效果不佳,无法真正实现概念的移除。
- 提出RevAm框架,利用强化学习优化扩散模型的采样轨迹,恢复被擦除的概念。
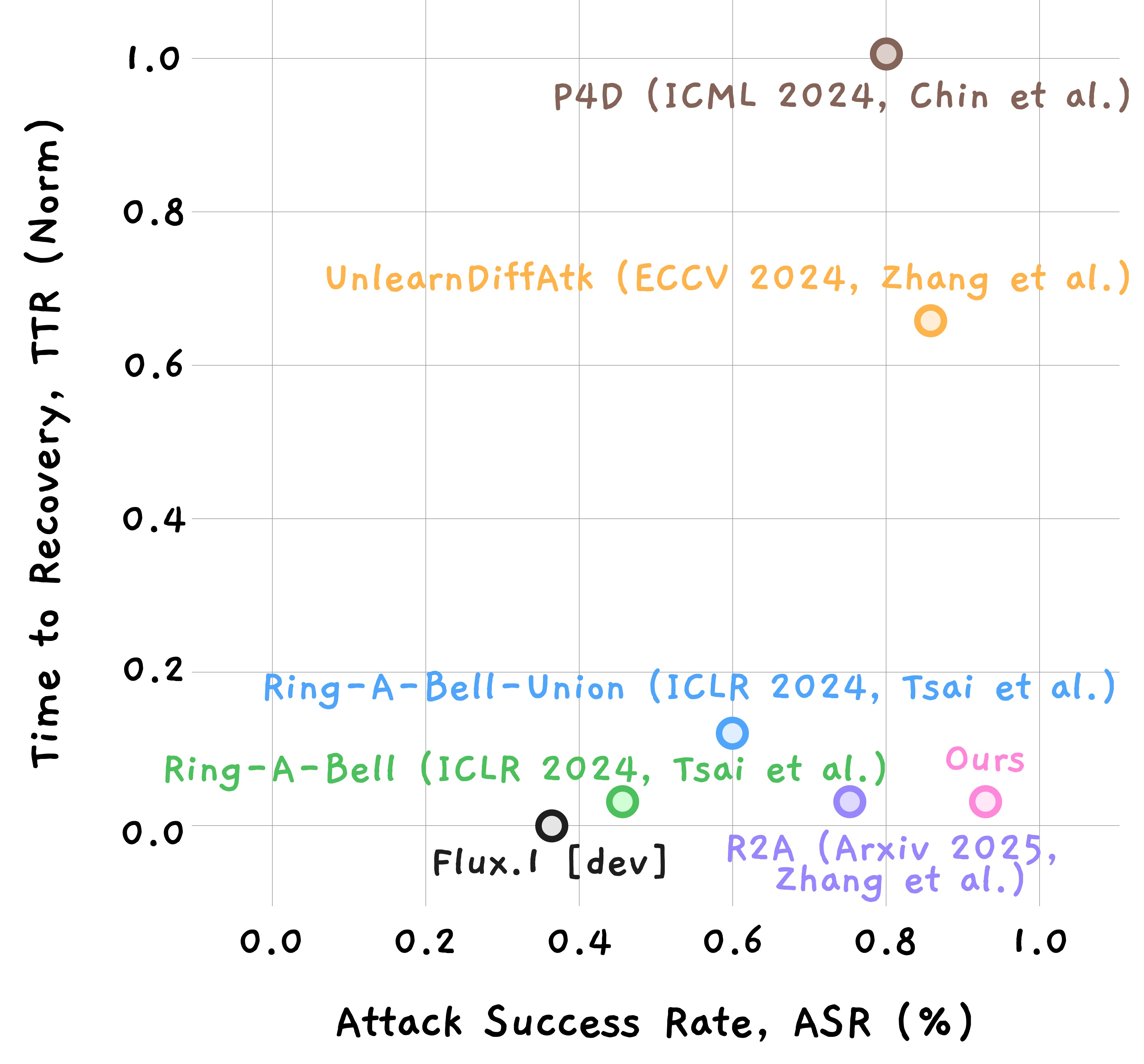
- 实验表明RevAm能有效恢复概念,计算效率提升10倍,揭示现有安全机制的漏洞。
📝 摘要(中文)
为了安全和版权考虑,概念擦除技术被广泛应用于文本到图像(T2I)扩散模型中,以防止生成不适当的内容。然而,随着模型发展到Flux等下一代架构,现有的擦除方法(例如,ESD、UCE、AC)的效果降低,引发了对其真正机制的质疑。通过系统分析,我们发现概念擦除仅仅创造了一种“失忆”的错觉:这些方法并非真正遗忘,而是使采样轨迹偏离目标概念,使得擦除本质上是可逆的。这一发现促使我们需要区分表面安全和真正的概念移除。在这项工作中,我们提出了RevAm(Revoking Amnesia),一个基于强化学习的轨迹优化框架,通过动态引导去噪过程来恢复被擦除的概念,而无需修改模型权重。通过将Group Relative Policy Optimization (GRPO) 应用于扩散模型,RevAm通过轨迹级别的奖励探索多样化的恢复轨迹,克服了限制现有方法的局部最优。大量实验表明,RevAm实现了卓越的概念恢复保真度,同时将计算时间减少了10倍,揭示了当前安全机制中的关键漏洞,并强调了对超越轨迹操作的更强大的擦除技术的需求。
🔬 方法详解
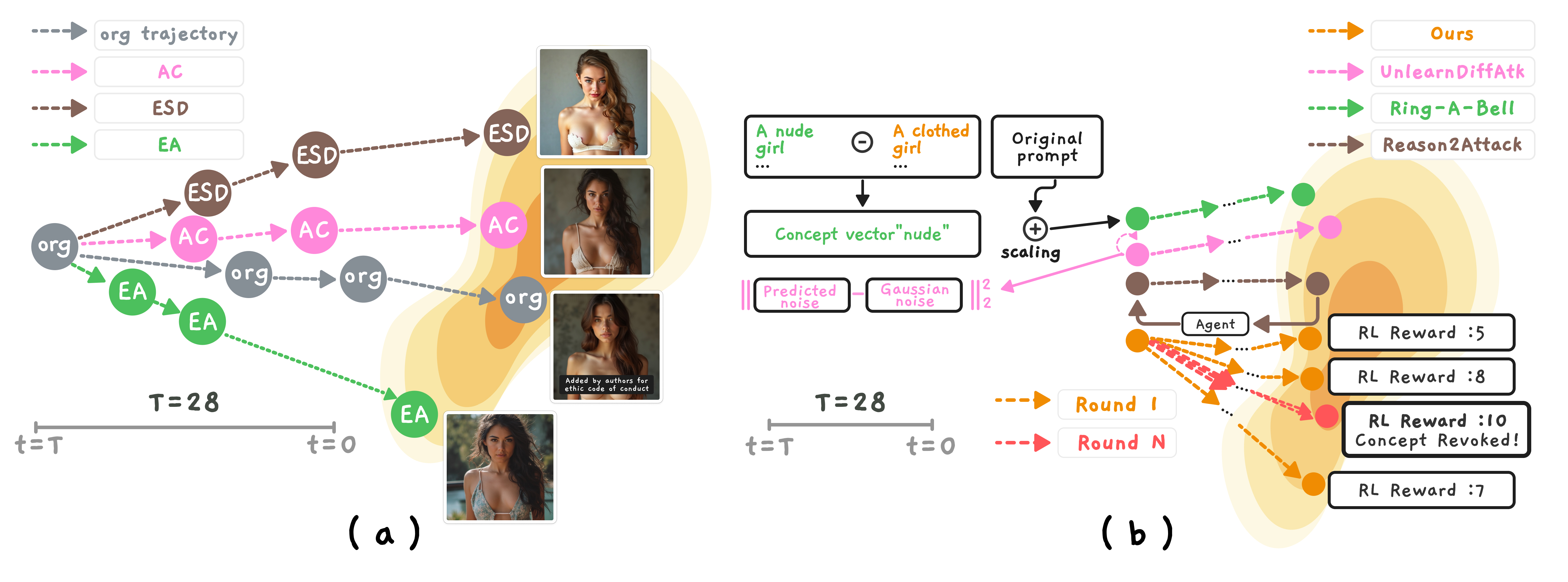
问题定义:论文旨在解决文本到图像扩散模型中概念擦除技术失效的问题。现有的概念擦除方法,如ESD、UCE、AC等,在新型扩散模型(如Flux)上表现出效果退化,无法彻底移除目标概念。这些方法仅仅是改变了采样轨迹,使得模型在生成图像时避开这些概念,而非真正从模型中“遗忘”它们。因此,如何真正且有效地移除扩散模型中的特定概念,避免生成不安全或不合规的内容,是本文要解决的核心问题。
核心思路:论文的核心思路是利用强化学习来优化扩散模型的采样轨迹,从而“逆转”概念擦除的效果,恢复原本被抑制的目标概念。作者认为,现有的擦除方法只是将采样轨迹推离了目标概念,而模型本身仍然保留着这些概念的信息。因此,通过精心设计的强化学习策略,可以引导采样轨迹重新回到目标概念的区域,从而“唤醒”这些被擦除的概念。
技术框架:RevAm框架主要包含以下几个关键模块:1) 扩散模型:作为生成图像的基础模型,可以是任何类型的扩散模型,例如DDPM、DDIM等。2) 概念擦除模块:使用现有的概念擦除方法(如ESD、UCE、AC)对扩散模型进行概念擦除。3) 强化学习代理:使用Group Relative Policy Optimization (GRPO) 作为强化学习算法,负责学习如何优化采样轨迹。4) 奖励函数:用于评估采样轨迹的质量,鼓励生成包含目标概念的图像,并惩罚生成不符合要求的图像。整体流程是,首先使用概念擦除模块对扩散模型进行擦除,然后使用强化学习代理在去噪过程中动态调整采样轨迹,最终生成包含被擦除概念的图像。
关键创新:RevAm的关键创新在于将强化学习引入到扩散模型的采样轨迹优化中,从而实现对被擦除概念的“复活”。与现有方法不同,RevAm不修改模型权重,而是通过动态调整采样轨迹来控制生成结果。此外,RevAm采用了Group Relative Policy Optimization (GRPO) 算法,能够探索更多样化的恢复轨迹,克服了局部最优问题。
关键设计:RevAm的关键设计包括:1) 奖励函数的设计:奖励函数需要能够准确评估生成图像中目标概念的存在程度,并能够区分不同类型的图像。作者可能使用了CLIP等模型来计算图像与目标概念之间的相似度,并将其作为奖励信号。2) GRPO算法的应用:GRPO算法能够有效地探索高维空间中的策略,并避免陷入局部最优。作者需要仔细调整GRPO算法的参数,以确保其能够有效地优化采样轨迹。3) 轨迹表示:如何将扩散模型的采样轨迹表示为强化学习代理可以理解的状态空间,也是一个关键的设计问题。作者可能使用了扩散模型的中间层特征作为状态表示。
🖼️ 关键图片

📊 实验亮点
实验结果表明,RevAm能够有效地恢复被擦除的概念,并且在概念恢复保真度方面优于现有方法。更重要的是,RevAm将计算时间减少了10倍,这表明其具有更高的效率。这些结果揭示了当前概念擦除技术的局限性,并强调了开发更鲁棒的擦除技术的必要性。
🎯 应用场景
该研究成果可应用于评估和改进现有扩散模型的安全性。通过RevAm,可以检测现有概念擦除技术的漏洞,并为开发更强大的概念移除方法提供指导。此外,该技术还可以用于生成对抗样本,帮助提高扩散模型对恶意攻击的鲁棒性。未来,该研究或可扩展到其他生成模型,例如GANs和Transformers。
📄 摘要(原文)
Concept erasure techniques have been widely deployed in T2I diffusion models to prevent inappropriate content generation for safety and copyright considerations. However, as models evolve to next-generation architectures like Flux, established erasure methods (\textit{e.g.}, ESD, UCE, AC) exhibit degraded effectiveness, raising questions about their true mechanisms. Through systematic analysis, we reveal that concept erasure creates only an illusion of ``amnesia": rather than genuine forgetting, these methods bias sampling trajectories away from target concepts, making the erasure fundamentally reversible. This insight motivates the need to distinguish superficial safety from genuine concept removal. In this work, we propose \textbf{RevAm} (\underline{Rev}oking \underline{Am}nesia), an RL-based trajectory optimization framework that resurrects erased concepts by dynamically steering the denoising process without modifying model weights. By adapting Group Relative Policy Optimization (GRPO) to diffusion models, RevAm explores diverse recovery trajectories through trajectory-level rewards, overcoming local optima that limit existing methods. Extensive experiments demonstrate that RevAm achieves superior concept resurrection fidelity while reducing computational time by 10$\times$, exposing critical vulnerabilities in current safety mechanisms and underscoring the need for more robust erasure techniques beyond trajectory manipulation.