DiSC-AMC: Token- and Parameter-Efficient Discretized Statistics In-Context Automatic Modulation Classification
作者: Mohammad Rostami, Atik Faysal, Reihaneh Gh. Roshan, Huaxia Wang, Nikhil Muralidhar, Yu-Dong Yao
分类: cs.LG
发布日期: 2025-09-30
💡 一句话要点
DiSC-AMC:面向token和参数高效的离散化统计量上下文自动调制分类
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 自动调制分类 大型语言模型 上下文学习 离散化统计量 参数高效 token高效 prompt工程
📋 核心要点
- 现有基于LLM的自动调制分类方法依赖长prompt和大型模型,导致部署困难,推理成本高昂。
- DiSC-AMC通过离散化统计量、精简上下文和校准prompt,显著降低token数量和模型参数。
- 实验表明,DiSC-AMC在保持甚至提升分类精度的同时,推理成本降低超过2倍,更易于实际应用。
📝 摘要(中文)
本文针对大型语言模型(LLM)在环自动调制分类(AMC)中,长prompt上下文和大型模型尺寸带来的实际瓶颈,提出了一种token和参数高效的变体:离散化统计量上下文自动调制分类(DiSC-AMC)。该方法(i)将高阶统计量和累积量离散化为紧凑的符号token,(ii)通过轻量级的k-top神经预过滤器修剪示例列表,并使用从先前LLM响应中提取的理由来过滤误导性/低影响的特征,以及(iii)通过校准的prompt模板强制执行仅标签预测。这些改变共同减少了输入/输出token和模型参数占用空间一半以上,同时保持了具有竞争力的准确性。在噪声下的十种调制类型的合成AMC上,一个7B参数的DeepSeek-R1-Distill-Qwen基线实现了5.2%的准确率,而我们的系统,使用一个大约5B参数的Gemini-2.5-Flash模型,达到了45.5%的准确率。这些结果表明,仔细的离散化和上下文选择可以将推理成本降低2倍以上,同时保留了基于prompt的AMC的优势,并实现了实际的环内使用。
🔬 方法详解
问题定义:论文旨在解决在自动调制分类(AMC)任务中,使用大型语言模型(LLM)进行上下文学习时,由于prompt过长和模型过大导致的计算资源消耗高、部署困难的问题。现有方法依赖于大量的上下文示例和复杂的模型结构,使得在实际应用中难以部署和使用。
核心思路:论文的核心思路是通过对输入特征进行离散化,减少prompt的长度;通过特征选择和上下文精简,降低模型的计算负担;以及通过prompt工程,提高模型的预测准确率。这样可以在保证分类性能的同时,显著降低模型的复杂度和计算成本。
技术框架:DiSC-AMC的整体框架包括以下几个主要模块:1) 特征离散化:将高阶统计量和累积量离散化为紧凑的符号token。2) 上下文精简:使用k-top神经预过滤器修剪示例列表,并使用从先前LLM响应中提取的理由来过滤误导性/低影响的特征。3) Prompt校准:通过校准的prompt模板强制执行仅标签预测。这些模块协同工作,共同实现了token和参数高效的自动调制分类。
关键创新:论文的关键创新在于将离散化统计量、上下文精简和prompt校准相结合,从而在保证分类性能的同时,显著降低了模型的复杂度和计算成本。与现有方法相比,DiSC-AMC不需要大量的上下文示例和复杂的模型结构,因此更易于部署和使用。
关键设计:1) 离散化方法:论文采用了一种基于量化的离散化方法,将连续的统计量映射到离散的符号token。2) k-top神经预过滤器:该预过滤器使用一个轻量级的神经网络来评估每个示例的重要性,并选择top-k个示例作为上下文。3) Prompt模板:论文设计了一个校准的prompt模板,该模板可以引导LLM进行仅标签预测,从而提高预测准确率。
🖼️ 关键图片

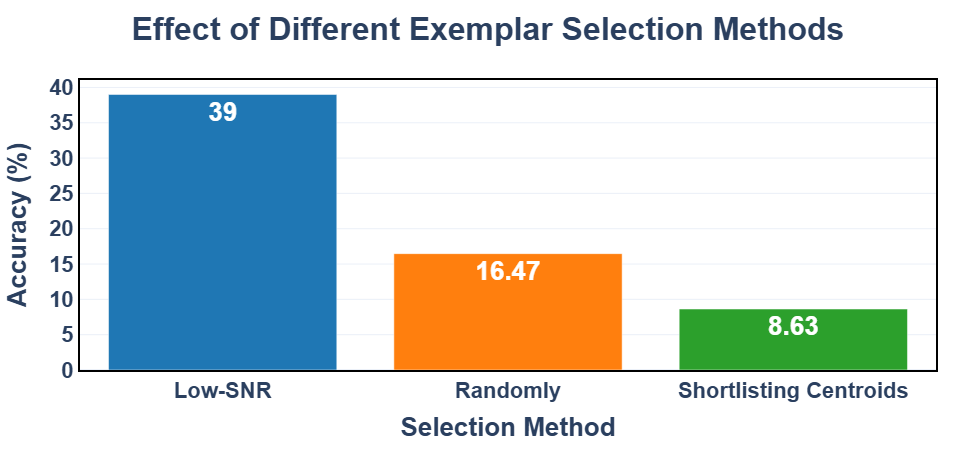
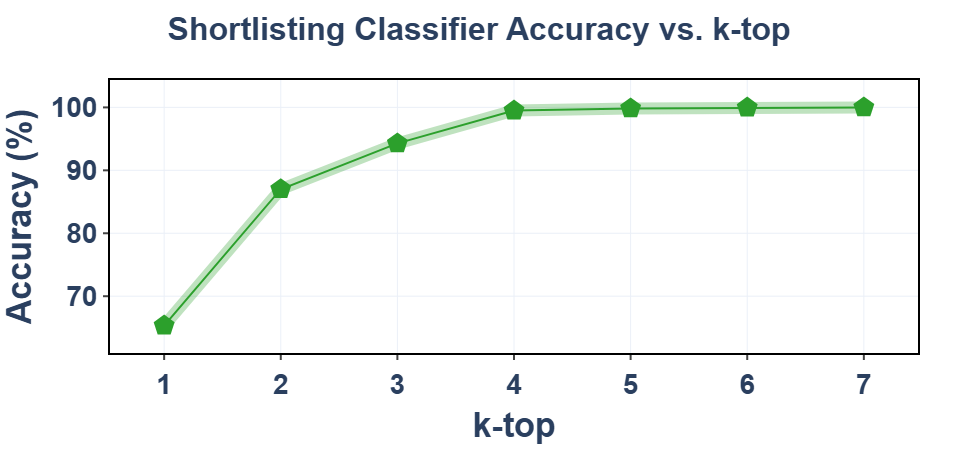
📊 实验亮点
DiSC-AMC在合成AMC数据集上取得了显著的性能提升。使用约5B参数的Gemini-2.5-Flash模型,DiSC-AMC达到了45.5%的准确率,而7B参数的DeepSeek-R1-Distill-Qwen基线仅为5.2%。这表明DiSC-AMC在降低模型复杂度的同时,显著提高了分类准确率。
🎯 应用场景
DiSC-AMC可应用于无线通信、频谱感知、认知无线电等领域,在资源受限的边缘设备上实现高效的自动调制分类。该方法降低了模型复杂度和计算成本,使得在实际通信系统中进行实时调制识别成为可能,有助于提高频谱利用率和通信质量。
📄 摘要(原文)
Large Language Models (LLMs) can perform Automatic Modulation Classification (AMC) in an open-set manner without LLM fine-tuning when equipped with carefully designed in-context prompts~\cite{rostami2025plug}. Building on this prior work, we target the practical bottlenecks of long prompt contexts and large model sizes that impede in-the-loop deployment. We present Discretized Statistics in-Context Automatic Modulation Classification (DiSC-AMC), a token- and parameter-efficient variant that: (i) discretizes higher-order statistics and cumulants into compact symbolic tokens, (ii) prunes the exemplar list via a lightweight k-top neural prefilter and filters misleading/low-impact features using rationales extracted from prior LLM responses, and (iii) enforces label-only predictions through a calibrated prompt template. Together, these changes reduce both input/output tokens and the model parameter footprint by more than half while maintaining competitive accuracy. On synthetic AMC with ten modulation types under noise, a 7B \textit{DeepSeek-R1-Distill-Qwen} baseline achieves 5.2% accuracy, whereas our system, using an approximately 5B-parameter \textit{Gemini-2.5-Flash}~\cite{comanici2025gemini} model, attains 45.5% accuracy. These results demonstrate that careful discretization and context selection can cut inference cost by over 2x while preserving the advantages of prompt-based AMC and enabling practical in-the-loop use.