Beyond Token Probes: Hallucination Detection via Activation Tensors with ACT-ViT
作者: Guy Bar-Shalom, Fabrizio Frasca, Yaniv Galron, Yftah Ziser, Haggai Maron
分类: cs.LG
发布日期: 2025-09-30
备注: Published in NeurIPS 2025
🔗 代码/项目: GITHUB
💡 一句话要点
提出ACT-ViT,利用激活张量检测大语言模型中的幻觉问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 幻觉检测 激活张量 视觉Transformer 零样本学习
📋 核心要点
- 现有幻觉检测方法依赖于特定LLM的token探测,泛化能力和效率受限。
- ACT-ViT将激活张量视为图像,利用视觉Transformer学习跨LLM的幻觉模式。
- 实验表明,ACT-ViT在多个LLM和数据集上优于传统方法,并具备零样本和迁移能力。
📝 摘要(中文)
检测大型语言模型(LLM)生成文本中的幻觉对于其安全部署至关重要。虽然探测分类器显示出潜力,但它们仅在孤立的层-token对上操作,并且特定于LLM,限制了其有效性并阻碍了跨LLM应用。本文提出了一种新方法来解决这些缺点。我们利用激活数据在两个轴(层×token)上的自然序列结构,并提倡将完整的激活张量视为图像。我们设计了ACT-ViT,一个受视觉Transformer启发的模型,可以有效且高效地应用于激活张量,并支持同时在来自多个LLM的数据上进行训练。通过包含各种LLM和数据集的综合实验,我们证明了ACT-ViT始终优于传统的探测技术,同时保持了极高的部署效率。特别是,我们表明我们的架构受益于多LLM训练,在未见数据集上实现了强大的零样本性能,并且可以通过微调有效地转移到新的LLM。
🔬 方法详解
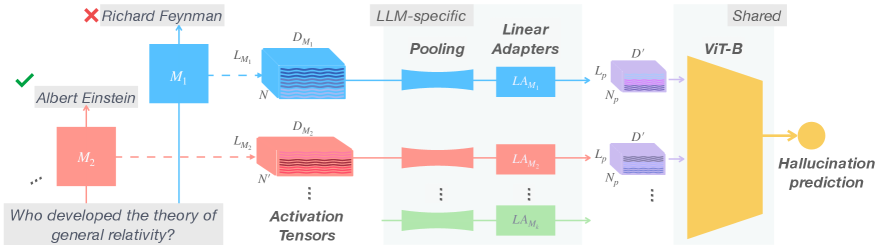
问题定义:现有的大语言模型幻觉检测方法,如token探测,通常针对特定模型和层进行设计,缺乏跨模型和数据集的泛化能力。此外,这些方法通常独立处理每个token,忽略了激活数据中的序列结构信息,效率较低。
核心思路:本文的核心思路是将大语言模型的激活张量视为图像,利用视觉Transformer(ViT)来学习其中的幻觉模式。通过将激活张量视为图像,可以利用ViT强大的特征提取能力,捕捉层和token之间的依赖关系,从而提高幻觉检测的准确性和泛化能力。
技术框架:ACT-ViT的整体架构包括以下几个主要模块:1) 激活张量提取:从大语言模型的中间层提取激活张量;2) 激活张量预处理:对激活张量进行归一化和重塑,使其符合ViT的输入格式;3) ACT-ViT模型:使用ViT模型对激活张量进行特征提取和分类,判断是否存在幻觉;4) 训练和评估:使用包含幻觉和非幻觉样本的数据集训练ACT-ViT模型,并评估其性能。
关键创新:ACT-ViT的关键创新在于将激活张量视为图像,并利用视觉Transformer来学习幻觉模式。这种方法能够有效地捕捉层和token之间的依赖关系,提高幻觉检测的准确性和泛化能力。此外,ACT-ViT支持多LLM训练,可以利用来自多个模型的激活数据来提高模型的鲁棒性。
关键设计:ACT-ViT使用标准的ViT架构,包括Patch Embedding、Transformer Encoder和分类头。Patch Embedding将激活张量分割成小的patch,并将其线性映射到嵌入向量。Transformer Encoder由多个Transformer层组成,用于学习patch之间的关系。分类头将Transformer Encoder的输出映射到幻觉概率。损失函数使用交叉熵损失函数,优化器使用AdamW优化器。
🖼️ 关键图片


📊 实验亮点
ACT-ViT在多个LLM和数据集上取得了显著的性能提升,优于传统的token探测方法。实验结果表明,ACT-ViT在多LLM训练下表现更佳,并且具备强大的零样本泛化能力,能够在未见数据集上取得良好的性能。此外,ACT-ViT可以通过微调快速适应新的LLM。
🎯 应用场景
ACT-ViT可应用于各种需要检测大语言模型幻觉的场景,例如:自动文本摘要、机器翻译、对话系统等。通过提高LLM生成内容的可靠性,ACT-ViT有助于提升用户体验,降低风险,并促进LLM在更多领域的应用。该研究为开发更安全、更可靠的LLM提供了新的思路。
📄 摘要(原文)
Detecting hallucinations in Large Language Model-generated text is crucial for their safe deployment. While probing classifiers show promise, they operate on isolated layer-token pairs and are LLM-specific, limiting their effectiveness and hindering cross-LLM applications. In this paper, we introduce a novel approach to address these shortcomings. We build on the natural sequential structure of activation data in both axes (layers $\times$ tokens) and advocate treating full activation tensors akin to images. We design ACT-ViT, a Vision Transformer-inspired model that can be effectively and efficiently applied to activation tensors and supports training on data from multiple LLMs simultaneously. Through comprehensive experiments encompassing diverse LLMs and datasets, we demonstrate that ACT-ViT consistently outperforms traditional probing techniques while remaining extremely efficient for deployment. In particular, we show that our architecture benefits substantially from multi-LLM training, achieves strong zero-shot performance on unseen datasets, and can be transferred effectively to new LLMs through fine-tuning. Full code is available at https://github.com/BarSGuy/ACT-ViT.