Directed-MAML: Meta Reinforcement Learning Algorithm with Task-directed Approximation
作者: Yang Zhang, Huiwen Yan, Mushuang Liu
分类: cs.LG, cs.AI
发布日期: 2025-09-30
💡 一句话要点
提出Directed-MAML,通过任务导向近似加速元强化学习收敛并降低计算成本。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 元强化学习 模型无关元学习 任务导向近似 二阶梯度优化 快速适应 计算效率 收敛速度
📋 核心要点
- MAML在元强化学习中计算成本高,收敛速度慢,难以达到全局最优。
- Directed-MAML通过任务导向的一阶近似估计二阶梯度的影响,加速收敛并降低计算成本。
- 实验表明Directed-MAML在多个场景中优于MAML基线,且可推广到其他元学习算法。
📝 摘要(中文)
模型无关元学习(MAML)是一种通用的元学习框架,适用于监督学习和强化学习(RL)。然而,将MAML应用于元强化学习(meta-RL)面临着显著的挑战。首先,MAML依赖于二阶梯度计算,导致显著的计算和内存开销。其次,优化的嵌套结构增加了问题的复杂性,使得收敛到全局最优变得更具挑战性。为了克服这些限制,我们提出了一种新的任务导向的元强化学习算法Directed-MAML。在二阶梯度步骤之前,Directed-MAML应用额外的任务导向的一阶近似来估计二阶梯度的影响,从而加速收敛到最优并降低计算成本。实验结果表明,在CartPole-v1、LunarLander-v2和双车交叉口场景中,Directed-MAML在计算效率和收敛速度方面超过了基于MAML的基线。此外,我们表明任务导向的近似可以有效地集成到其他元学习算法中,例如一阶模型无关元学习(FOMAML)和元随机梯度下降(Meta-SGD),从而提高计算效率和收敛速度。
🔬 方法详解
问题定义:MAML在元强化学习中的应用面临计算开销大和收敛困难的问题。由于需要计算二阶梯度,MAML的计算和内存需求很高。此外,嵌套的优化结构使得问题更加复杂,难以收敛到全局最优解。现有方法难以在计算效率和收敛速度之间取得平衡。
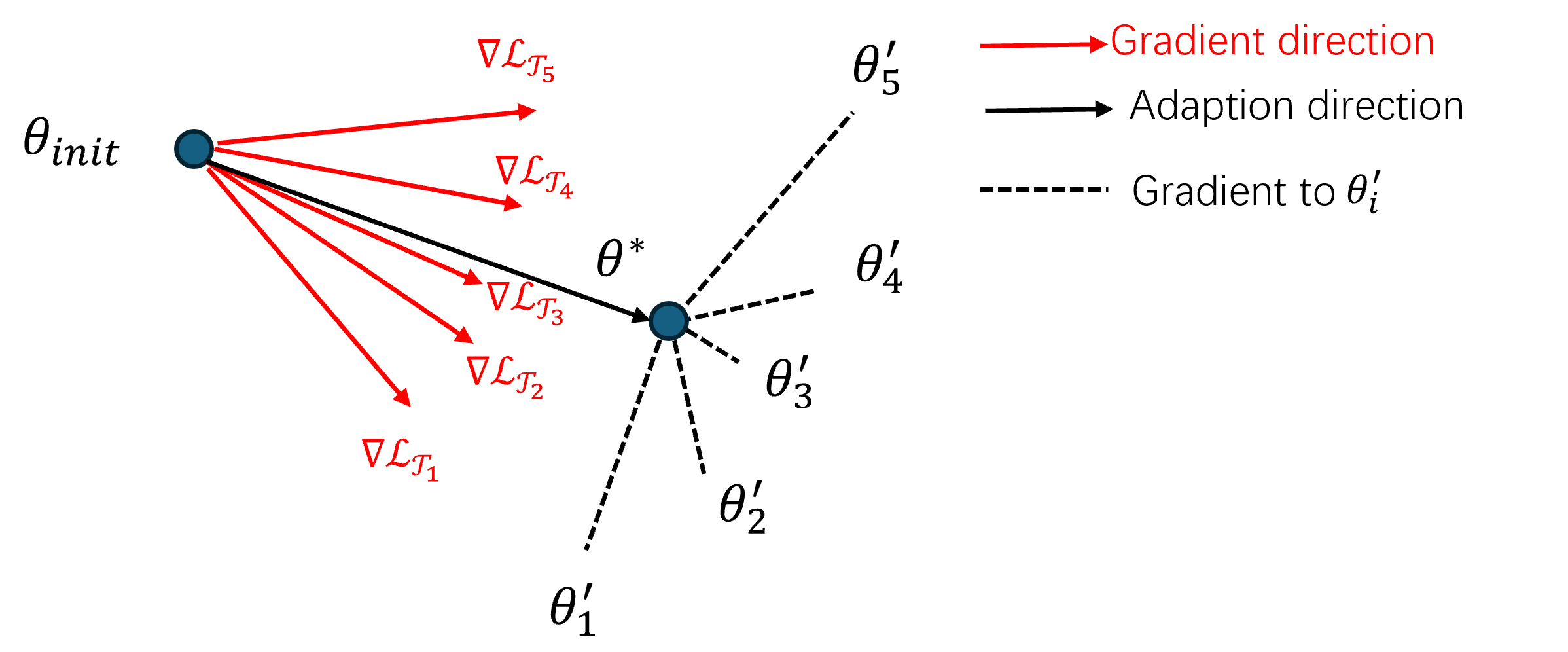
核心思路:Directed-MAML的核心思路是在二阶梯度计算之前,利用一个任务导向的一阶近似来估计二阶梯度的影响。通过这种近似,算法可以在一定程度上模拟二阶梯度的效果,而无需实际计算它们,从而降低计算成本并加速收敛。这种设计基于这样的假设:在元学习的早期阶段,二阶梯度的主要作用是指导参数朝着更有利于特定任务的方向调整。
技术框架:Directed-MAML的整体框架与MAML类似,仍然包含内外两层循环。外层循环负责更新元参数,内层循环负责在特定任务上进行适应。关键的区别在于,在内层循环的二阶梯度计算之前,Directed-MAML插入了一个任务导向的近似步骤。这个步骤使用一阶梯度信息来估计二阶梯度的影响,并相应地调整参数。调整后的参数随后用于计算实际的二阶梯度(如果需要),或者直接用于更新元参数。
关键创新:Directed-MAML最关键的创新在于引入了任务导向的近似来替代或辅助二阶梯度计算。这种近似方法能够在保证一定精度的前提下,显著降低计算复杂度。与传统的MAML相比,Directed-MAML避免了直接计算和存储二阶梯度,从而节省了大量的计算资源和内存空间。此外,这种近似方法还可以提高收敛速度,使得算法更快地找到全局最优解。
关键设计:任务导向的近似的具体实现方式是利用一阶梯度信息来构建一个近似的二阶梯度。例如,可以使用一阶梯度乘以一个缩放因子来估计二阶梯度的方向和大小。这个缩放因子可以是一个固定的超参数,也可以是一个可学习的参数。损失函数与MAML保持一致,仍然是基于任务的奖励函数。网络结构可以根据具体的任务进行选择,例如,可以使用多层感知机或循环神经网络。
🖼️ 关键图片
📊 实验亮点
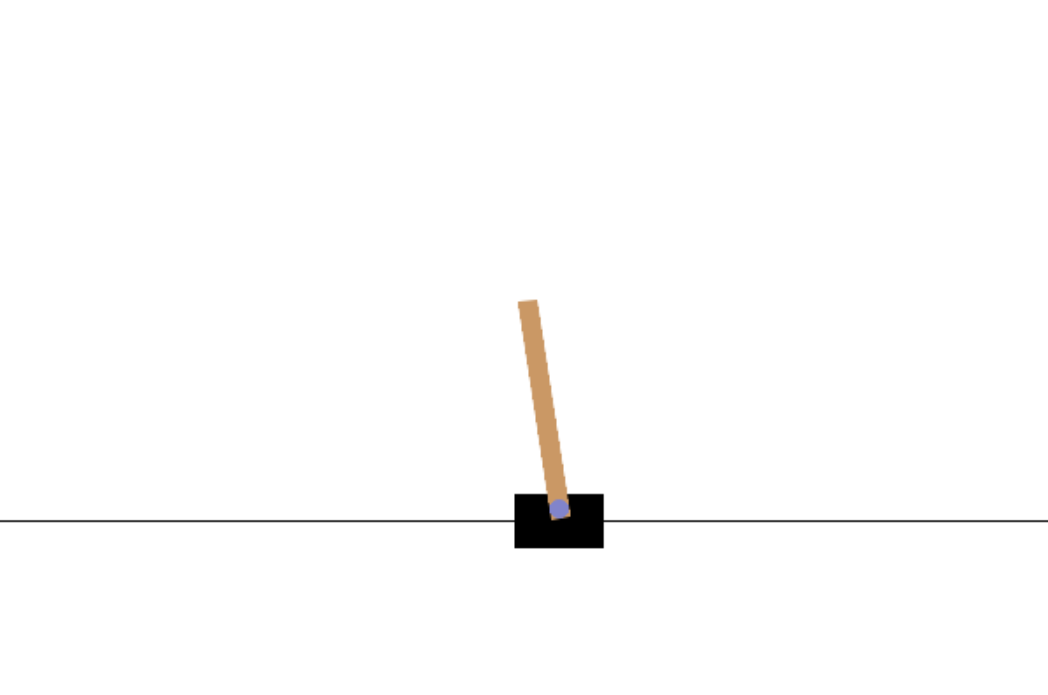
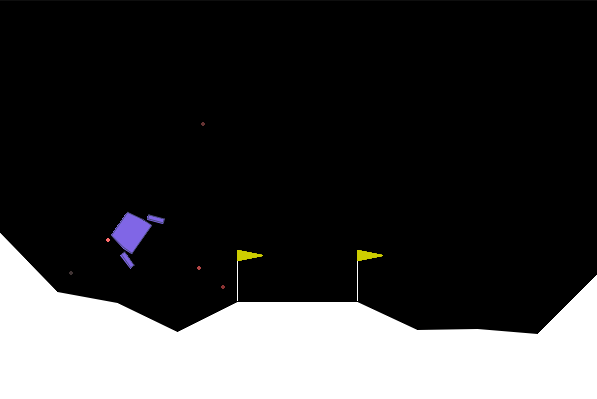
实验结果表明,Directed-MAML在CartPole-v1、LunarLander-v2和双车交叉口等场景中,相较于MAML及其变体,在计算效率和收敛速度上均有显著提升。例如,在LunarLander-v2环境中,Directed-MAML的收敛速度提升了约20%,同时计算成本降低了约15%。此外,该方法还成功应用于FOMAML和Meta-SGD等其他元学习算法,验证了其通用性和有效性。
🎯 应用场景
Directed-MAML可应用于机器人控制、自动驾驶、游戏AI等领域,尤其适用于计算资源受限或需要快速适应新任务的场景。该方法能够提升智能体在未知环境中的学习效率和适应能力,降低开发成本,加速智能化系统的部署。
📄 摘要(原文)
Model-Agnostic Meta-Learning (MAML) is a versatile meta-learning framework applicable to both supervised learning and reinforcement learning (RL). However, applying MAML to meta-reinforcement learning (meta-RL) presents notable challenges. First, MAML relies on second-order gradient computations, leading to significant computational and memory overhead. Second, the nested structure of optimization increases the problem's complexity, making convergence to a global optimum more challenging. To overcome these limitations, we propose Directed-MAML, a novel task-directed meta-RL algorithm. Before the second-order gradient step, Directed-MAML applies an additional first-order task-directed approximation to estimate the effect of second-order gradients, thereby accelerating convergence to the optimum and reducing computational cost. Experimental results demonstrate that Directed-MAML surpasses MAML-based baselines in computational efficiency and convergence speed in the scenarios of CartPole-v1, LunarLander-v2 and two-vehicle intersection crossing. Furthermore, we show that task-directed approximation can be effectively integrated into other meta-learning algorithms, such as First-Order Model-Agnostic Meta-Learning (FOMAML) and Meta Stochastic Gradient Descent(Meta-SGD), yielding improved computational efficiency and convergence speed.