Why Can't Transformers Learn Multiplication? Reverse-Engineering Reveals Long-Range Dependency Pitfalls
作者: Xiaoyan Bai, Itamar Pres, Yuntian Deng, Chenhao Tan, Stuart Shieber, Fernanda Viégas, Martin Wattenberg, Andrew Lee
分类: cs.LG, cs.AI
发布日期: 2025-09-30
💡 一句话要点
Transformer难以学习乘法:逆向工程揭示长程依赖的陷阱
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: Transformer 长程依赖 逆向工程 归纳偏置 多位数乘法
📋 核心要点
- Transformer模型在多位数乘法等需要长程依赖的任务上表现不佳,现有方法难以有效学习。
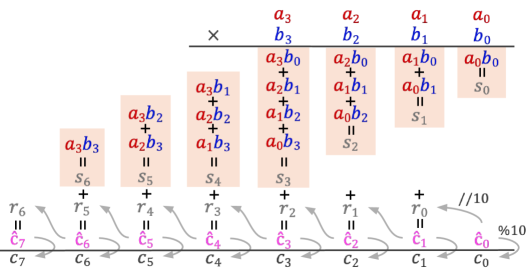
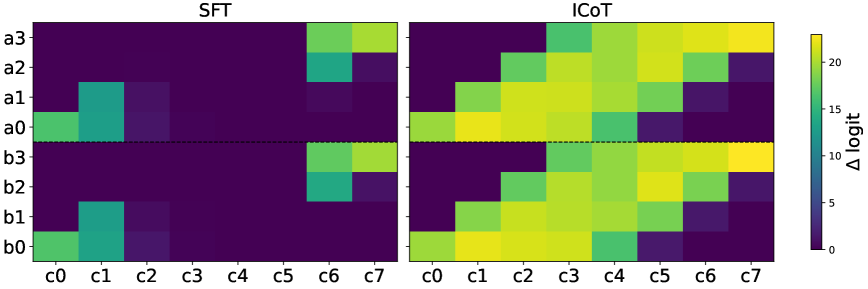
- 通过逆向工程成功学习乘法的模型,发现其利用注意力机制构建有向无环图来缓存和检索中间结果。
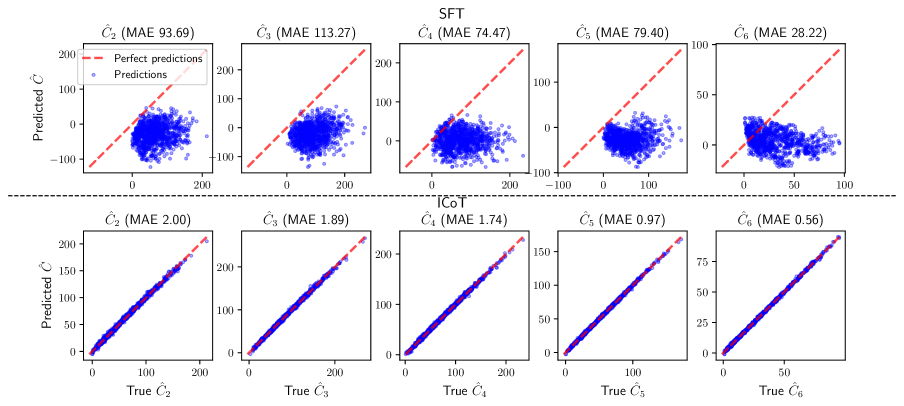
- 引入预测“运行总和”的辅助损失,为模型提供归纳偏置,使其能够成功学习多位数乘法。
📝 摘要(中文)
语言模型能力日益增强,但仍无法完成看似简单的多位数乘法任务。本文通过逆向工程一个成功学习乘法的模型(通过隐式思维链),研究了其原因,并报告了三个发现:(1)长程结构的证据:Logit归因和线性探针表明,该模型编码了多位数乘法所需的必要长程依赖。(2)机制:该模型使用注意力机制构建有向无环图来“缓存”和“检索”成对的中间结果。(3)几何:该模型通过在数字对之间形成闵可夫斯基和,并在注意力头中实现中间结果,并且使用傅里叶基表示数字,这两种表示方法直观且高效,而标准微调模型缺乏这些。基于这些见解,我们重新审视了标准微调的学习动态,发现该模型收敛到缺乏所需长程依赖的局部最优解。我们通过引入一个辅助损失来预测“运行总和”(通过线性回归探针)来验证这一理解,该辅助损失提供了一种归纳偏置,使模型能够成功学习多位数乘法。总之,通过逆向工程隐式思维链模型的机制,我们揭示了Transformer学习长程依赖的一个陷阱,并提供了一个例子,说明正确的归纳偏置如何解决这个问题。
🔬 方法详解
问题定义:论文旨在解决Transformer模型在学习多位数乘法时遇到的困难。现有的Transformer模型在处理需要长程依赖的任务时,容易陷入局部最优解,无法有效地捕捉数字之间的复杂关系,导致无法正确执行乘法运算。
核心思路:论文的核心思路是通过逆向工程一个已经成功学习乘法的Transformer模型,分析其内部机制,从而理解模型如何处理长程依赖。然后,将这些理解应用于标准的微调模型,通过引入合适的归纳偏置来改善其学习能力。
技术框架:论文的研究框架主要包括以下几个阶段:1) 训练一个能够成功进行多位数乘法的Transformer模型(通过隐式思维链)。2) 使用logit归因和线性探针等技术,分析该模型的内部表示,特别是其如何编码长程依赖。3) 揭示模型使用注意力机制构建有向无环图来缓存和检索中间结果的机制。4) 发现模型使用傅里叶基表示数字,并通过闵可夫斯基和在注意力头中实现中间结果。5) 将这些发现应用于标准的微调模型,并引入辅助损失来改善其学习能力。
关键创新:论文的关键创新在于通过逆向工程揭示了Transformer模型学习长程依赖的陷阱,并提供了一种通过引入辅助损失来改善模型学习能力的有效方法。此外,论文还揭示了模型内部使用注意力机制构建有向无环图以及使用傅里叶基表示数字等有趣的机制。
关键设计:论文的关键设计包括:1) 使用logit归因和线性探针来分析模型的内部表示。2) 引入预测“运行总和”的辅助损失,该损失通过线性回归探针实现。3) 使用傅里叶基表示数字,并通过闵可夫斯基和在注意力头中实现中间结果。辅助损失的具体形式和权重需要根据具体任务进行调整。
🖼️ 关键图片
📊 实验亮点
论文通过实验证明,引入预测“运行总和”的辅助损失可以显著提高Transformer模型在多位数乘法任务上的性能。与标准微调模型相比,引入辅助损失的模型能够更快地收敛到全局最优解,并获得更高的准确率。实验结果表明,正确的归纳偏置对于Transformer模型学习长程依赖至关重要。
🎯 应用场景
该研究成果可应用于提升Transformer模型在需要长程依赖的任务上的性能,例如复杂推理、代码生成、数学计算等领域。通过引入合适的归纳偏置,可以使模型更好地捕捉输入数据中的结构信息,从而提高模型的泛化能力和鲁棒性。此外,该研究也为理解Transformer模型的内部机制提供了新的视角。
📄 摘要(原文)
Language models are increasingly capable, yet still fail at a seemingly simple task of multi-digit multiplication. In this work, we study why, by reverse-engineering a model that successfully learns multiplication via \emph{implicit chain-of-thought}, and report three findings: (1) Evidence of long-range structure: Logit attributions and linear probes indicate that the model encodes the necessary long-range dependencies for multi-digit multiplication. (2) Mechanism: the model encodes long-range dependencies using attention to construct a directed acyclic graph to
cache'' andretrieve'' pairwise partial products. (3) Geometry: the model implements partial products in attention heads by forming Minkowski sums between pairs of digits, and digits are represented using a Fourier basis, both of which are intuitive and efficient representations that the standard fine-tuning model lacks. With these insights, we revisit the learning dynamics of standard fine-tuning and find that the model converges to a local optimum that lacks the required long-range dependencies. We further validate this understanding by introducing an auxiliary loss that predicts the ``running sum'' via a linear regression probe, which provides an inductive bias that enables the model to successfully learn multi-digit multiplication. In summary, by reverse-engineering the mechanisms of an implicit chain-of-thought model we uncover a pitfall for learning long-range dependencies in Transformers and provide an example of how the correct inductive bias can address this issue.