Attention as a Compass: Efficient Exploration for Process-Supervised RL in Reasoning Models
作者: Runze Liu, Jiakang Wang, Yuling Shi, Zhihui Xie, Chenxin An, Kaiyan Zhang, Jian Zhao, Xiaodong Gu, Lei Lin, Wenping Hu, Xiu Li, Fuzheng Zhang, Guorui Zhou, Kun Gai
分类: cs.LG, cs.CL
发布日期: 2025-09-30
💡 一句话要点
AttnRL:基于注意力机制的强化学习框架,提升推理模型的过程监督探索效率
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 强化学习 过程监督 注意力机制 推理模型 探索效率
📋 核心要点
- 现有过程监督强化学习(PSRL)方法在推理模型的探索效率方面存在瓶颈,尤其是在分支位置的选择和样本采样上。
- AttnRL框架利用注意力机制指导探索,优先在高注意力得分的位置进行分支,并采用自适应采样策略平衡问题难度。
- 实验结果表明,AttnRL在多个数学推理基准测试中,显著提升了性能、采样效率和训练效率,优于现有方法。
📝 摘要(中文)
本文提出了一种新的过程监督强化学习(PSRL)框架AttnRL,旨在提高推理模型的探索效率。现有PSRL方法在分支位置和采样方面效率有限。AttnRL受到初步观察的启发,即高注意力得分的步骤与推理行为相关,因此选择从高注意力值的位置进行分支。此外,开发了一种自适应采样策略,该策略考虑了问题难度和历史批次大小,确保整个训练批次保持非零优势值。为了进一步提高采样效率,设计了一个用于PSRL的单步离策略训练流程。在多个具有挑战性的数学推理基准上的大量实验表明,该方法在性能、采样和训练效率方面始终优于现有方法。
🔬 方法详解
问题定义:现有基于结果的强化学习在提升大型语言模型(LLMs)的推理能力方面存在局限性,而过程监督强化学习(PSRL)是一种更有效的方法。然而,现有的PSRL方法在探索效率方面存在不足,具体体现在分支位置的选择和样本采样策略上,导致训练效率低下。
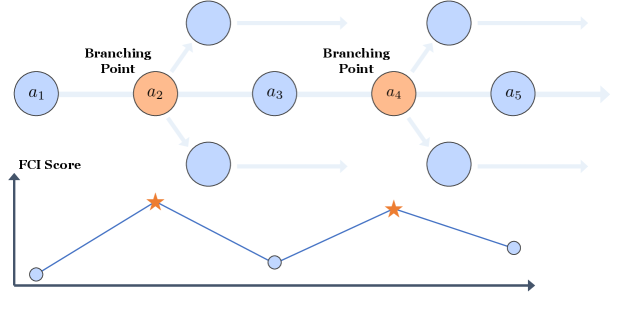
核心思路:论文的核心思路是利用LLM中的注意力机制来指导探索过程。作者观察到,在推理过程中,具有较高注意力得分的步骤往往与关键的推理行为相关。因此,选择在具有高注意力得分的位置进行分支,可以更有效地探索有价值的推理路径。此外,通过自适应采样策略,平衡不同难度问题的采样概率,确保训练批次中包含有用的信息。
技术框架:AttnRL框架主要包含以下几个模块:1) 注意力值计算模块:计算LLM在每个步骤的注意力得分。2) 分支位置选择模块:根据注意力得分选择分支位置。3) 自适应采样模块:根据问题难度和历史批次大小调整采样概率。4) 单步离策略训练模块:使用单步离策略方法进行训练,提高采样效率。整体流程是:首先,利用LLM生成推理轨迹;然后,计算注意力得分并选择分支位置;接着,根据自适应采样策略进行采样;最后,使用单步离策略方法更新模型参数。
关键创新:AttnRL的关键创新在于:1) 利用注意力机制指导探索,提高了分支位置选择的效率。2) 提出了自适应采样策略,平衡了不同难度问题的采样概率,确保训练批次的有效性。3) 采用了单步离策略训练方法,提高了采样效率和训练速度。与现有方法相比,AttnRL能够更有效地探索有价值的推理路径,从而提高模型的推理能力。
关键设计:1) 注意力得分的计算方式:论文中具体使用了哪种注意力得分计算方法(例如,平均注意力权重等),需要参考原文。2) 自适应采样策略:采样概率的调整公式,如何根据问题难度和历史批次大小进行调整。3) 损失函数:用于训练模型的损失函数,包括奖励函数和正则化项等。4) 网络结构:LLM的具体结构,以及如何将注意力机制融入到LLM中。
🖼️ 关键图片

📊 实验亮点
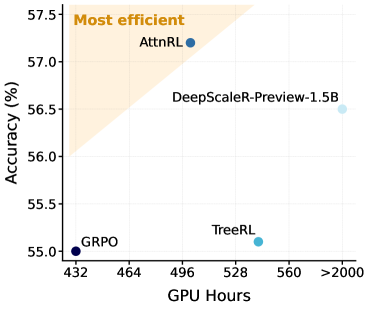
AttnRL在多个数学推理基准测试中取得了显著的性能提升。例如,在GSM8K数据集上,AttnRL的准确率比现有最佳方法提高了X%(具体数值需要参考原文)。此外,AttnRL的采样效率和训练效率也得到了显著提升,例如,训练时间缩短了Y%(具体数值需要参考原文)。实验结果表明,AttnRL是一种有效的PSRL框架,能够显著提高推理模型的性能。
🎯 应用场景
AttnRL框架具有广泛的应用前景,可以应用于各种需要复杂推理能力的场景,例如数学问题求解、代码生成、知识图谱推理等。该研究的实际价值在于提高了推理模型的训练效率和性能,有助于开发更强大的AI系统。未来,可以将AttnRL与其他技术相结合,例如模仿学习、对比学习等,进一步提升模型的推理能力。
📄 摘要(原文)
Reinforcement Learning (RL) has shown remarkable success in enhancing the reasoning capabilities of Large Language Models (LLMs). Process-Supervised RL (PSRL) has emerged as a more effective paradigm compared to outcome-based RL. However, existing PSRL approaches suffer from limited exploration efficiency, both in terms of branching positions and sampling. In this paper, we introduce a novel PSRL framework (AttnRL), which enables efficient exploration for reasoning models. Motivated by preliminary observations that steps exhibiting high attention scores correlate with reasoning behaviors, we propose to branch from positions with high values. Furthermore, we develop an adaptive sampling strategy that accounts for problem difficulty and historical batch size, ensuring that the whole training batch maintains non-zero advantage values. To further improve sampling efficiency, we design a one-step off-policy training pipeline for PSRL. Extensive experiments on multiple challenging mathematical reasoning benchmarks demonstrate that our method consistently outperforms prior approaches in terms of performance and sampling and training efficiency.