Learning to See Before Seeing: Demystifying LLM Visual Priors from Language Pre-training
作者: Junlin Han, Shengbang Tong, David Fan, Yufan Ren, Koustuv Sinha, Philip Torr, Filippos Kokkinos
分类: cs.LG, cs.AI, cs.CV, cs.MM
发布日期: 2025-09-30
备注: Project page: https://junlinhan.github.io/projects/lsbs/
💡 一句话要点
揭示LLM视觉先验:通过语言预训练学习视觉感知与推理能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 视觉先验 多模态学习 预训练 视觉推理 视觉感知 数据驱动 多模态基准
📋 核心要点
- 现有方法难以理解LLM中视觉先验的来源和构成,阻碍了多模态LLM的有效构建。
- 论文通过系统分析,揭示了视觉先验由感知和推理先验组成,并探究了它们的来源和缩放规律。
- 实验验证了论文提出的数据驱动的预训练方法,为构建下一代多模态LLM提供了新思路。
📝 摘要(中文)
大型语言模型(LLM)仅通过文本训练,却出人意料地发展出丰富的视觉先验。这些先验使得潜在的视觉能力能够通过相对少量的多模态数据被解锁,用于视觉任务,在某些情况下,甚至可以在没有见过图像的情况下执行视觉任务。通过系统分析,我们揭示了视觉先验——在语言预训练期间获得的关于视觉世界的隐式、涌现的知识——由可分离的感知和推理先验组成,它们具有独特的缩放趋势和起源。我们表明,LLM的潜在视觉推理能力主要通过以推理为中心的数据(例如,代码、数学、学术)的预训练来发展,并逐步扩展。这种从语言预训练中获得的推理先验是可转移的,并且普遍适用于视觉推理。相比之下,感知先验更分散地从广泛的语料库中出现,并且感知能力对视觉编码器和视觉指令调整数据更敏感。同时,描述视觉世界的文本被证明至关重要,尽管其性能影响迅速饱和。利用这些见解,我们提出了一种以数据为中心的预训练视觉感知LLM的配方,并在1T token规模的预训练中验证了它。我们的发现基于超过100个受控实验,消耗了500,000 GPU小时,涵盖了完整的MLLM构建流程——从LLM预训练到视觉对齐和监督多模态微调——跨越五个模型规模,各种数据类别和混合,以及多个适应设置。除了我们的主要发现之外,我们还提出并研究了几个假设,并引入了多级存在基准(MLE-Bench)。总之,这项工作提供了一种有意识地从语言预训练中培养视觉先验的新方法,为下一代多模态LLM铺平了道路。
🔬 方法详解
问题定义:论文旨在解决如何理解和利用大型语言模型(LLM)在纯文本预训练中获得的视觉先验知识,从而更有效地构建多模态LLM。现有方法缺乏对这些视觉先验的深入理解,导致在多模态任务中难以充分发挥LLM的潜力。
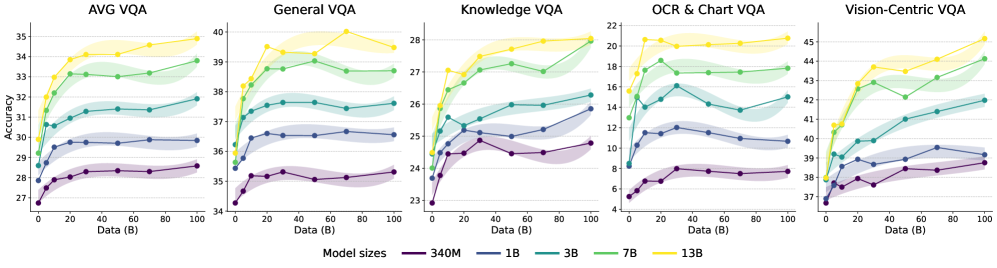
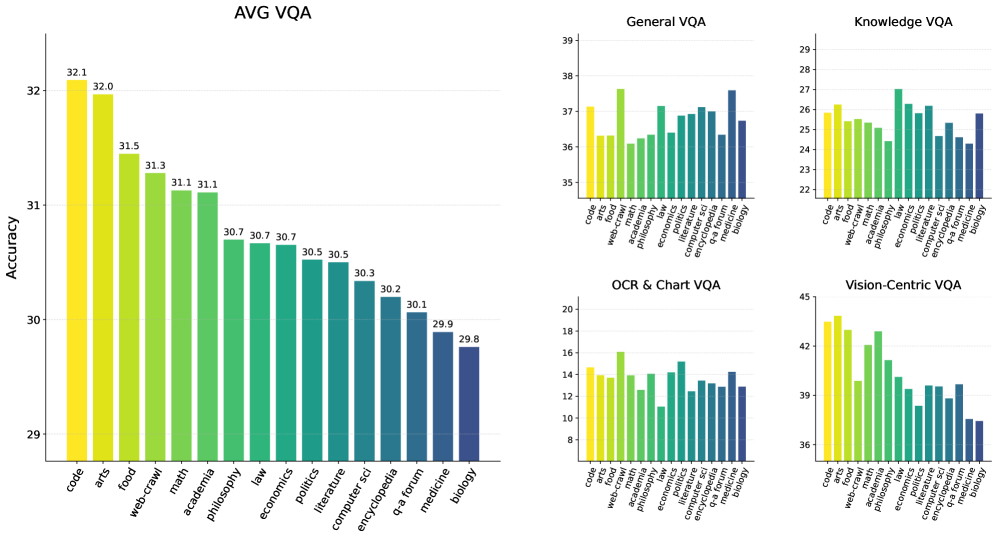
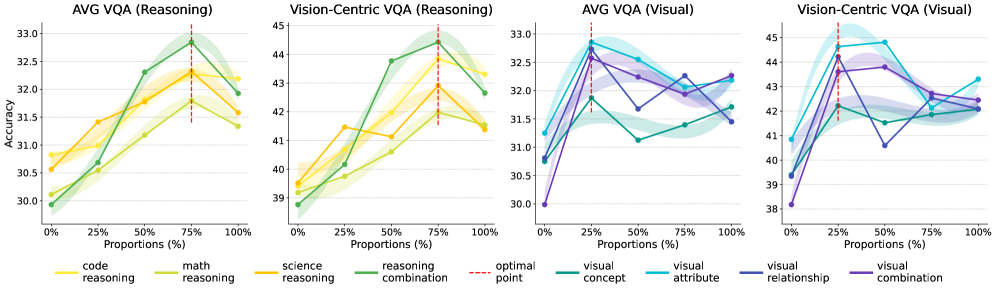
核心思路:论文的核心思路是将LLM的视觉先验分解为感知先验和推理先验,并分别研究它们的来源、缩放规律以及对多模态任务的影响。通过控制预训练数据,分析不同类型数据对感知和推理能力的影响,从而指导多模态LLM的预训练过程。
技术框架:论文的研究框架主要包括以下几个阶段:1) LLM预训练:使用不同类型和规模的文本数据预训练LLM。2) 视觉对齐:将视觉信息与LLM对齐,使其能够理解图像。3) 多模态微调:在多模态数据集上微调LLM,使其能够执行视觉任务。4) 系统分析:通过控制实验,分析不同因素对LLM视觉能力的影响。论文还提出了Multi-Level Existence Bench (MLE-Bench) 用于评估模型的多模态能力。
关键创新:论文的关键创新在于:1) 揭示了LLM中视觉先验的构成,将其分解为感知和推理先验。2) 发现了推理先验主要来源于以推理为中心的数据,而感知先验更分散地来源于广泛的语料库。3) 提出了数据驱动的预训练方法,能够更有效地培养LLM的视觉能力。
关键设计:论文的关键设计包括:1) 使用不同类型的数据(例如,代码、数学、学术文本、普通文本)进行预训练,以研究不同数据对视觉先验的影响。2) 设计了控制实验,例如改变预训练数据的比例、调整视觉编码器等,以分析不同因素对LLM视觉能力的影响。3) 提出了MLE-Bench,用于评估模型在不同层次上的多模态理解能力。
🖼️ 关键图片
📊 实验亮点
论文通过超过100个受控实验,消耗了500,000 GPU小时,验证了所提出的数据驱动预训练方法的有效性。实验结果表明,通过合理控制预训练数据,可以显著提升LLM的视觉推理和感知能力。论文还提出了MLE-Bench,为多模态LLM的评估提供了一个新的基准。
🎯 应用场景
该研究成果可应用于各种多模态任务,例如图像描述、视觉问答、视觉推理等。通过更好地理解和利用LLM的视觉先验,可以构建更强大的多模态LLM,提升其在实际应用中的性能。例如,可以应用于智能客服、自动驾驶、医疗诊断等领域。
📄 摘要(原文)
Large Language Models (LLMs), despite being trained on text alone, surprisingly develop rich visual priors. These priors allow latent visual capabilities to be unlocked for vision tasks with a relatively small amount of multimodal data, and in some cases, to perform visual tasks without ever having seen an image. Through systematic analysis, we reveal that visual priors-the implicit, emergent knowledge about the visual world acquired during language pre-training-are composed of separable perception and reasoning priors with unique scaling trends and origins. We show that an LLM's latent visual reasoning ability is predominantly developed by pre-training on reasoning-centric data (e.g., code, math, academia) and scales progressively. This reasoning prior acquired from language pre-training is transferable and universally applicable to visual reasoning. In contrast, a perception prior emerges more diffusely from broad corpora, and perception ability is more sensitive to the vision encoder and visual instruction tuning data. In parallel, text describing the visual world proves crucial, though its performance impact saturates rapidly. Leveraging these insights, we propose a data-centric recipe for pre-training vision-aware LLMs and verify it in 1T token scale pre-training. Our findings are grounded in over 100 controlled experiments consuming 500,000 GPU-hours, spanning the full MLLM construction pipeline-from LLM pre-training to visual alignment and supervised multimodal fine-tuning-across five model scales, a wide range of data categories and mixtures, and multiple adaptation setups. Along with our main findings, we propose and investigate several hypotheses, and introduce the Multi-Level Existence Bench (MLE-Bench). Together, this work provides a new way of deliberately cultivating visual priors from language pre-training, paving the way for the next generation of multimodal LLMs.