Clarification as Supervision: Reinforcement Learning for Vision-Language Interfaces
作者: John Gkountouras, Ivan Titov
分类: cs.LG, cs.CL, cs.CV
发布日期: 2025-09-30
💡 一句话要点
提出自适应澄清强化学习,解决视觉-语言接口中信息缺失问题
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 视觉-语言接口 强化学习 视觉数学推理 自适应澄清 隐式监督
📋 核心要点
- 现有视觉-语言模型在视觉数学推理中,由于忽略推理系统所需的精确细节,导致性能受限。
- AC-RL通过强化学习,利用澄清请求作为隐式监督信号,促使模型生成更全面的初始描述。
- 实验表明,AC-RL在多个视觉数学推理基准上显著提升了准确率,并减少了澄清请求。
📝 摘要(中文)
本文提出了一种自适应澄清强化学习(AC-RL)方法,旨在解决视觉-语言模型在视觉数学推理任务中因信息缺失而导致的性能瓶颈。现有模型通常被训练为生成面向人类读者的图像描述,但忽略了推理系统所需的精确细节,造成接口不匹配。AC-RL通过交互式学习,让视觉模型了解推理器需要哪些信息。核心思想是:训练期间的澄清请求揭示了信息缺口;通过惩罚需要澄清才能成功的案例,促使模型生成更全面的初始描述,从而使推理器能够一次性解决问题。实验表明,AC-RL在七个视觉数学推理基准测试中,平均准确率比预训练基线提高了4.4个百分点,并可减少高达39%的澄清请求。AC-RL将澄清视为一种隐式监督,证明了视觉-语言接口可以通过纯交互式学习有效地学习,而无需显式标注。
🔬 方法详解
问题定义:论文旨在解决视觉-语言模型在视觉数学推理任务中,由于视觉信息描述不完整而导致的推理失败问题。现有模型训练目标是生成面向人类的图像描述,而非面向机器推理,因此忽略了推理所需的关键细节,导致推理器无法获取足够的信息来完成任务。
核心思路:论文的核心思路是将澄清请求视为一种隐式监督信号。通过强化学习,模型学习如何生成更全面的初始描述,从而减少推理器对澄清的需求。模型的目标是最大化推理成功率,同时最小化澄清请求的数量。这种方法鼓励模型在第一次尝试时就提供所有必要的信息。
技术框架:AC-RL包含两个主要模块:视觉-语言模型(负责生成图像描述)和推理器(负责根据描述进行推理)。训练过程如下:1) 视觉-语言模型生成图像描述;2) 推理器尝试根据描述解决问题;3) 如果推理失败,推理器可以请求澄清;4) 视觉-语言模型根据澄清请求更新描述;5) 推理器再次尝试解决问题;6) 根据推理结果和澄清请求的数量,计算奖励信号,并使用强化学习算法更新视觉-语言模型。
关键创新:最重要的创新点在于将澄清请求作为一种隐式监督信号,并利用强化学习来优化视觉-语言模型的描述生成策略。与传统的监督学习方法不同,AC-RL不需要显式的标注数据,而是通过与推理器的交互来学习。这种方法更符合实际应用场景,因为在实际应用中,我们通常无法获得完美的标注数据。
关键设计:AC-RL的关键设计包括:1) 奖励函数的设计,奖励函数需要平衡推理成功率和澄清请求的数量;2) 强化学习算法的选择,论文使用了策略梯度算法来优化视觉-语言模型的描述生成策略;3) 视觉-语言模型的结构,论文使用了预训练的视觉-语言模型作为基础模型,并对其进行了微调。
🖼️ 关键图片


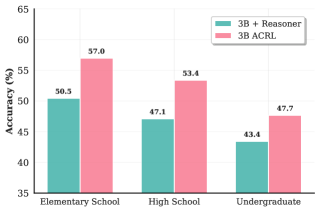
📊 实验亮点
AC-RL在七个视觉数学推理基准测试中,平均准确率比预训练基线提高了4.4个百分点。更重要的是,分析表明,如果允许澄清请求,AC-RL可以将澄清请求的数量减少高达39%。这表明AC-RL能够有效地学习生成更全面的初始描述,从而减少推理器对额外信息的依赖。
🎯 应用场景
该研究成果可应用于各种需要视觉-语言交互的场景,例如视觉问答、机器人导航、图像编辑等。通过学习生成更精确、更全面的图像描述,可以提高机器在这些任务中的性能。此外,该方法还可以用于训练更智能的对话系统,使其能够更好地理解用户的意图并提供更准确的回答。未来,该研究有望推动视觉-语言智能的发展,并为人类提供更智能、更便捷的服务。
📄 摘要(原文)
Recent text-only models demonstrate remarkable mathematical reasoning capabilities. Extending these to visual domains requires vision-language models to translate images into text descriptions. However, current models, trained to produce captions for human readers, often omit the precise details that reasoning systems require. This creates an interface mismatch: reasoners often fail not due to reasoning limitations but because they lack access to critical visual information. We propose Adaptive-Clarification Reinforcement Learning (AC-RL), which teaches vision models what information reasoners need through interaction. Our key insight is that clarification requests during training reveal information gaps; by penalizing success that requires clarification, we create pressure for comprehensive initial captions that enable the reasoner to solve the problem in a single pass. AC-RL improves average accuracy by 4.4 points over pretrained baselines across seven visual mathematical reasoning benchmarks, and analysis shows it would cut clarification requests by up to 39% if those were allowed. By treating clarification as a form of implicit supervision, AC-RL demonstrates that vision-language interfaces can be effectively learned through interaction alone, without requiring explicit annotations.