Linking Process to Outcome: Conditional Reward Modeling for LLM Reasoning
作者: Zheng Zhang, Ziwei Shan, Kaitao Song, Yexin Li, Kan Ren
分类: cs.LG
发布日期: 2025-09-30
💡 一句话要点
提出条件奖励建模(CRM)以提升LLM推理能力,解决过程奖励模型的局限性。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 推理能力 奖励模型 条件奖励建模 信用分配 因果关系 强化学习 奖励黑客
📋 核心要点
- 现有过程奖励模型(PRM)未能充分捕捉推理步骤间的依赖关系,且难以将过程奖励与最终结果对齐,导致信用分配模糊。
- 提出条件奖励建模(CRM),将每个推理步骤的奖励与前面的步骤和最终结果相关联,捕捉推理步骤间的因果关系。
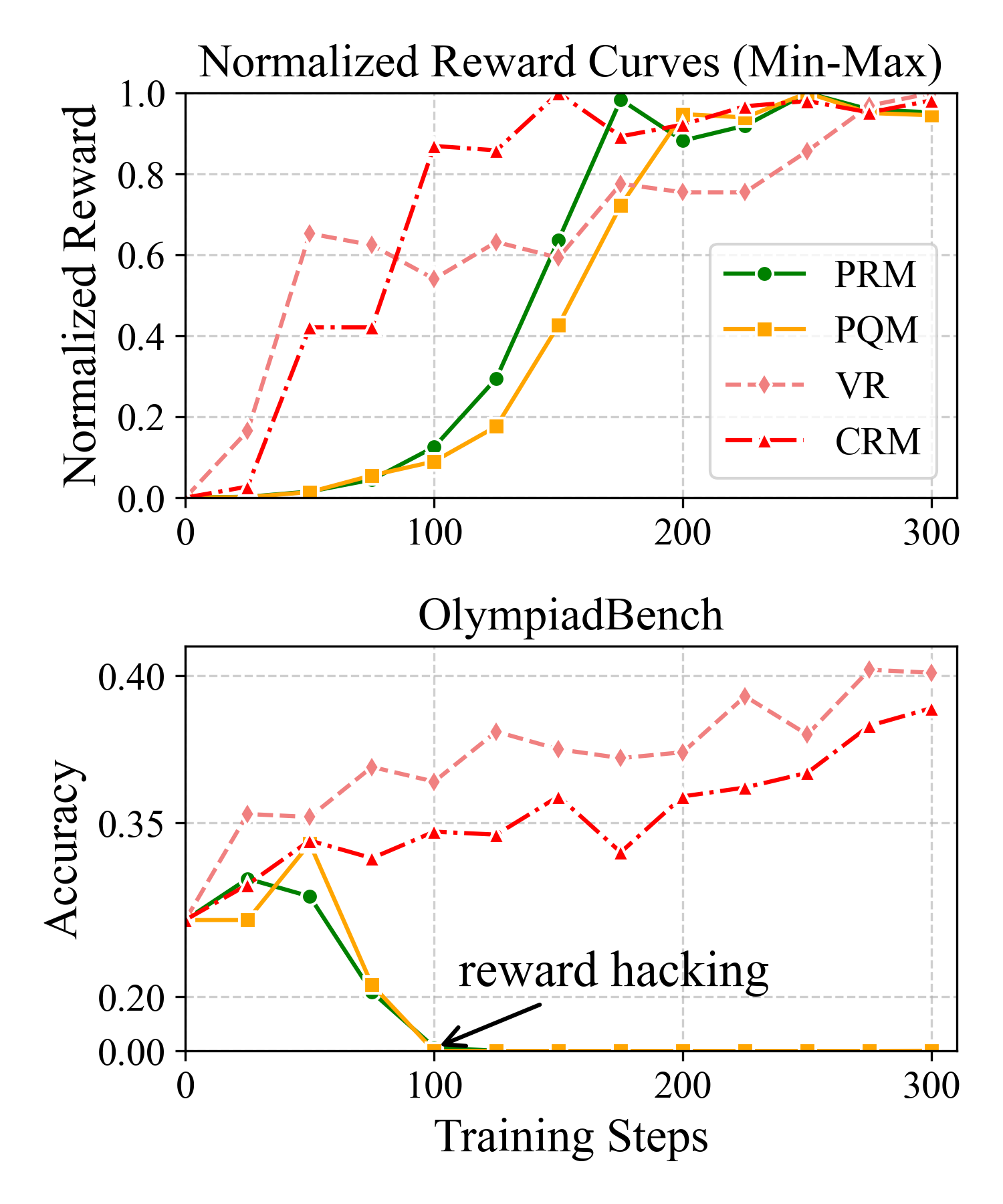
- 实验表明,CRM在Best-of-N抽样、束搜索和强化学习中均优于现有奖励模型,且对奖励黑客攻击更具鲁棒性。
📝 摘要(中文)
过程奖励模型(PRM)通过引导大型语言模型(LLM)逐步推理以获得最终答案,已成为增强其推理能力的一种有前景的方法。然而,现有的PRM要么孤立地对待每个推理步骤,未能捕捉步骤间的依赖关系,要么难以将过程奖励与最终结果对齐。因此,奖励信号未能尊重序列推理中的时间因果关系,并面临着模糊的信用分配问题。这些限制使得下游模型容易受到奖励黑客攻击,并导致次优性能。本文提出了条件奖励建模(CRM),将LLM推理视为一个通向正确答案的时间过程。每个推理步骤的奖励不仅取决于前面的步骤,而且明确地与推理轨迹的最终结果相关联。通过强制执行条件概率规则,我们的设计捕捉了推理步骤之间的因果关系,并与结果的联系允许对每个中间步骤进行精确的归因,从而解决信用分配的模糊性。此外,通过这种一致的概率建模,CRM产生的奖励能够实现更可靠的跨样本比较。在Best-of-N抽样、束搜索和强化学习方面的实验表明,CRM始终优于现有的奖励模型,为增强LLM推理提供了一个有原则的框架。特别是,CRM对奖励黑客攻击更具鲁棒性,并提供稳定的下游改进,而无需依赖从真实标签导出的可验证奖励。
🔬 方法详解
问题定义:现有过程奖励模型(PRM)在指导LLM进行推理时存在两个主要问题。一是未能捕捉推理步骤之间的依赖关系,将每个步骤孤立地看待。二是难以将过程奖励与最终结果对齐,导致奖励信号与最终结果之间的因果关系不明确,从而产生信用分配问题。这些问题使得LLM容易受到奖励黑客攻击,最终影响推理性能。
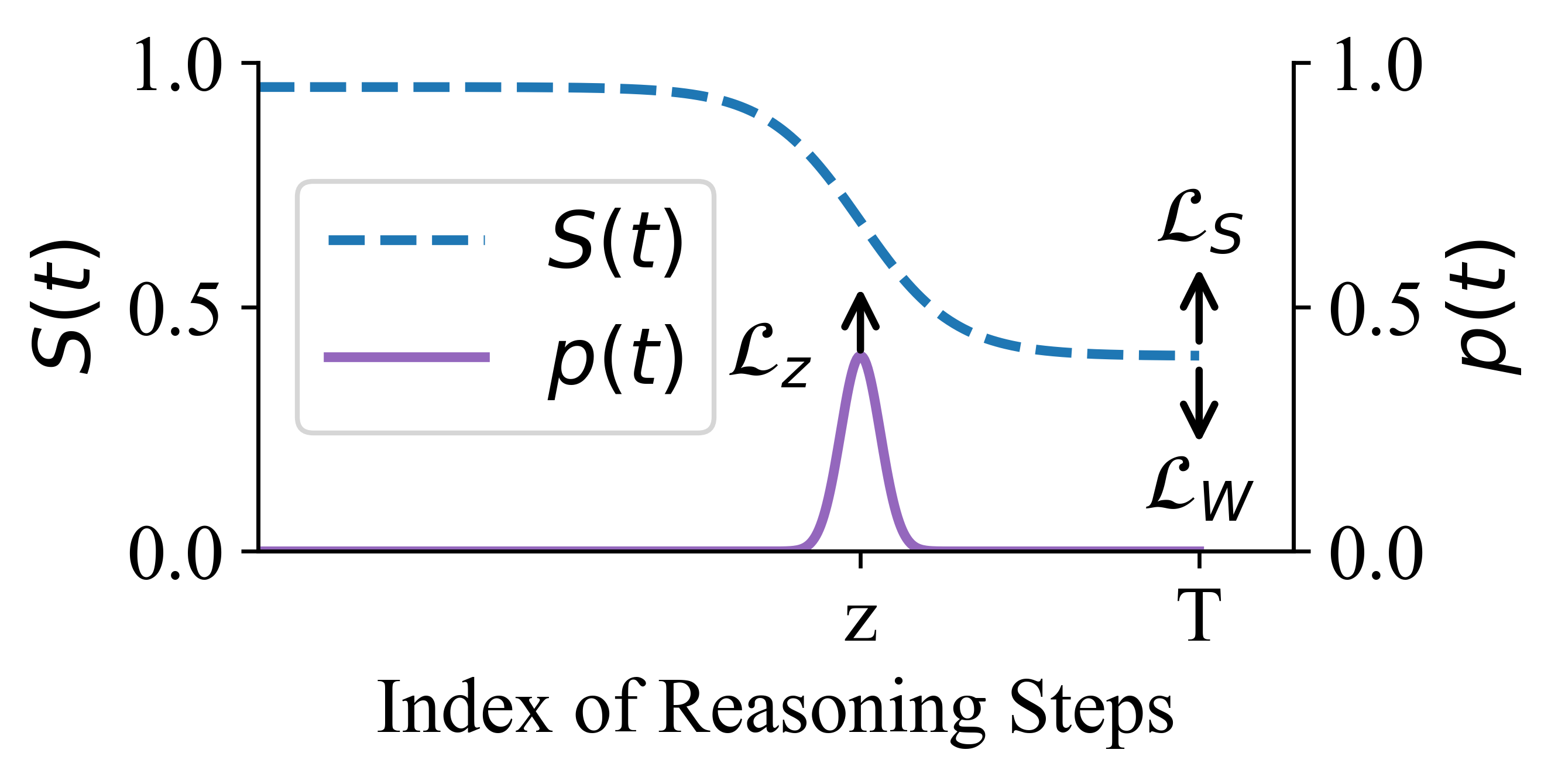
核心思路:论文的核心思路是将LLM的推理过程建模为一个时间序列过程,其中每个步骤的奖励不仅取决于之前的步骤,还显式地与最终结果相关联。通过引入条件概率建模,确保奖励信号能够反映推理步骤之间的因果关系,并能够根据最终结果对每个中间步骤进行准确的信用分配。这种方法旨在解决现有PRM的局限性,提高LLM推理的稳定性和准确性。
技术框架:CRM的技术框架主要包括以下几个阶段:1) 推理轨迹生成:使用LLM生成多个推理轨迹,每个轨迹包含一系列推理步骤和最终答案。2) 条件奖励建模:构建条件奖励模型,该模型根据之前的推理步骤和最终结果,为每个步骤分配奖励。3) 模型训练:使用生成的推理轨迹和相应的奖励,训练条件奖励模型。训练目标是最大化正确推理轨迹的奖励,同时惩罚错误的推理轨迹。4) 推理优化:使用训练好的条件奖励模型,指导LLM进行推理,选择奖励最高的推理路径。
关键创新:CRM的关键创新在于其条件奖励建模方法。与现有PRM不同,CRM显式地将每个推理步骤的奖励与之前的步骤和最终结果相关联,从而捕捉推理步骤之间的因果关系。这种条件建模方法能够更准确地评估每个步骤的贡献,解决信用分配的模糊性,并提高LLM推理的鲁棒性。此外,CRM通过一致的概率建模,使得奖励具有更好的可比性,从而能够更有效地进行跨样本比较。
关键设计:CRM的关键设计包括:1) 条件概率建模:使用条件概率来建模每个推理步骤的奖励,即P(reward | previous steps, final outcome)。2) 奖励函数设计:设计合适的奖励函数,以鼓励正确的推理步骤,并惩罚错误的推理步骤。奖励函数可以基于最终结果的正确性,以及中间步骤的合理性。3) 模型结构:可以使用Transformer等神经网络结构来构建条件奖励模型,输入为之前的推理步骤和最终结果,输出为每个步骤的奖励。4) 训练策略:可以使用强化学习或监督学习等方法来训练条件奖励模型。强化学习可以使用策略梯度算法,监督学习可以使用交叉熵损失函数。
🖼️ 关键图片

📊 实验亮点
实验结果表明,CRM在Best-of-N抽样、束搜索和强化学习等多种场景下均优于现有的奖励模型。特别是在奖励黑客攻击方面,CRM表现出更强的鲁棒性。CRM能够在不依赖真实标签的情况下,实现稳定的下游性能提升,证明了其在增强LLM推理方面的有效性。
🎯 应用场景
该研究成果可广泛应用于需要LLM进行复杂推理的场景,例如问答系统、代码生成、数学问题求解、逻辑推理等。通过提高LLM推理的准确性和鲁棒性,可以提升这些应用的性能和用户体验。此外,该方法还可以应用于其他序列决策问题,例如机器人导航、游戏AI等。
📄 摘要(原文)
Process Reward Models (PRMs) have emerged as a promising approach to enhance the reasoning capabilities of large language models (LLMs) by guiding their step-by-step reasoning toward a final answer. However, existing PRMs either treat each reasoning step in isolation, failing to capture inter-step dependencies, or struggle to align process rewards with the final outcome. Consequently, the reward signal fails to respect temporal causality in sequential reasoning and faces ambiguous credit assignment. These limitations make downstream models vulnerable to reward hacking and lead to suboptimal performance. In this work, we propose Conditional Reward Modeling (CRM) that frames LLM reasoning as a temporal process leading to a correct answer. The reward of each reasoning step is not only conditioned on the preceding steps but also explicitly linked to the final outcome of the reasoning trajectory. By enforcing conditional probability rules, our design captures the causal relationships among reasoning steps, with the link to the outcome allowing precise attribution of each intermediate step, thereby resolving credit assignment ambiguity. Further, through this consistent probabilistic modeling, the rewards produced by CRM enable more reliable cross-sample comparison. Experiments across Best-of-N sampling, beam search and reinforcement learning demonstrate that CRM consistently outperforms existing reward models, offering a principled framework for enhancing LLM reasoning. In particular, CRM is more robust to reward hacking and delivers stable downstream improvements without relying on verifiable rewards derived from ground truth.